 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGCformer: Deep Graph Clustering Transformer for Multivariate Time Series Forecasting
May 14, 2024



Multivariate time series forecasting tasks are usually conducted in a channel-dependent (CD) way since it can incorporate more variable-relevant information. However, it may also involve a lot of irrelevant variables, and this even leads to worse performance than the channel-independent (CI) strategy. This paper combines the strengths of both strategies and proposes the Deep Graph Clustering Transformer (DGCformer) for multivariate time series forecasting. Specifically, it first groups these relevant variables by a graph convolutional network integrated with an autoencoder, and a former-latter masked self-attention mechanism is then considered with the CD strategy being applied to each group of variables while the CI one for different groups. Extensive experimental results on eight datasets demonstrate the superiority of our method against state-of-the-art models, and our code will be publicly available upon acceptance.
PGformer: Proxy-Bridged Game Transformer for Multi-Person Extremely Interactive Motion Prediction
Jun 12, 2023



Multi-person motion prediction is a challenging task, especially for real-world scenarios of densely interacted persons. Most previous works have been devoted to studying the case of weak interactions (e.g., hand-shaking), which typically forecast each human pose in isolation. In this paper, we focus on motion prediction for multiple persons with extreme collaborations and attempt to explore the relationships between the highly interactive persons' motion trajectories. Specifically, a novel cross-query attention (XQA) module is proposed to bilaterally learn the cross-dependencies between the two pose sequences tailored for this situation. Additionally, we introduce and build a proxy entity to bridge the involved persons, which cooperates with our proposed XQA module and subtly controls the bidirectional information flows, acting as a motion intermediary. We then adapt these designs to a Transformer-based architecture and devise a simple yet effective end-to-end framework called proxy-bridged game Transformer (PGformer) for multi-person interactive motion prediction. The effectiveness of our method has been evaluated on the challenging ExPI dataset, which involves highly interactive actions. We show that our PGformer consistently outperforms the state-of-the-art methods in both short- and long-term predictions by a large margin. Besides, our approach can also be compatible with the weakly interacted CMU-Mocap and MuPoTS-3D datasets and achieve encouraging results. Our code will become publicly available upon acceptance.
Cross-Layer Retrospective Retrieving via Layer Attention
Feb 28, 2023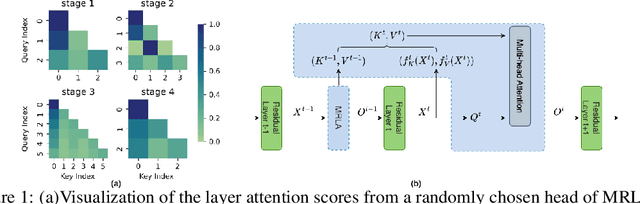
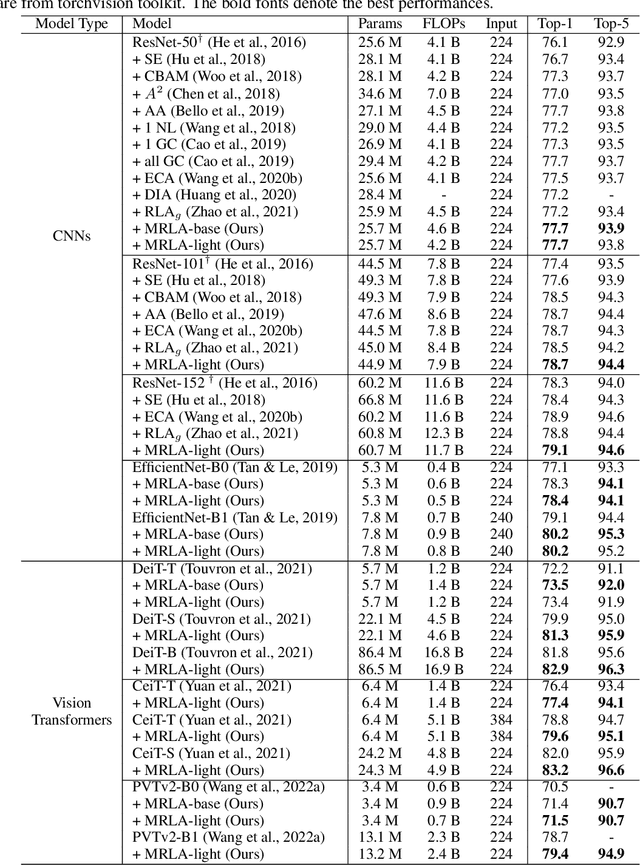
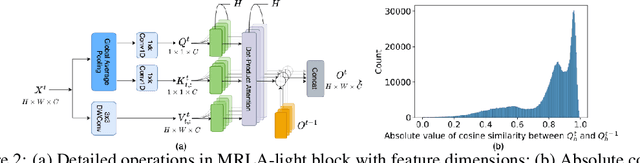
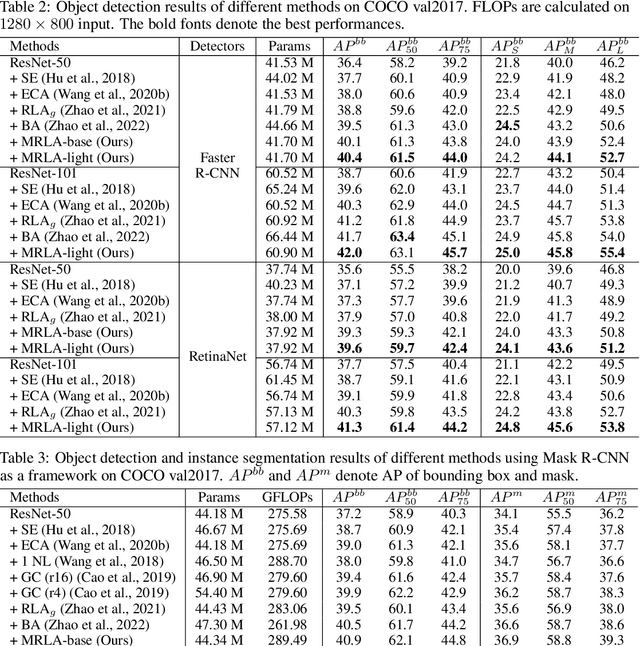
More and more evidence has shown that strengthening layer interactions can enhance the representation power of a deep neural network, while self-attention excels at learning interdependencies by retrieving query-activated information. Motivated by this, we devise a cross-layer attention mechanism, called multi-head recurrent layer attention (MRLA), that sends a query representation of the current layer to all previous layers to retrieve query-related information from different levels of receptive fields. A light-weighted version of MRLA is also proposed to reduce the quadratic computation cost. The proposed layer attention mechanism can enrich the representation power of many state-of-the-art vision networks, including CNNs and vision transformers. Its effectiveness has been extensively evaluated in image classification, object detection and instance segmentation tasks, where improvements can be consistently observed. For example, our MRLA can improve 1.6% Top-1 accuracy on ResNet-50, while only introducing 0.16M parameters and 0.07B FLOPs. Surprisingly, it can boost the performances by a large margin of 3-4% box AP and mask AP in dense prediction tasks. Our code is available at https://github.com/joyfang1106/MRLA.
Recurrence along Depth: Deep Convolutional Neural Networks with Recurrent Layer Aggregation
Oct 22, 2021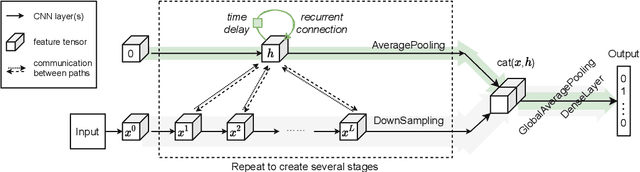
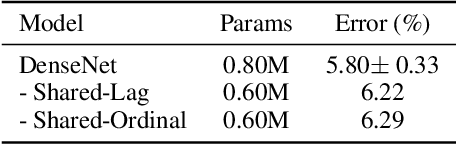
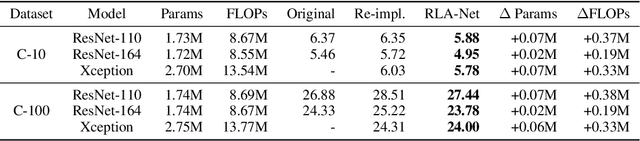
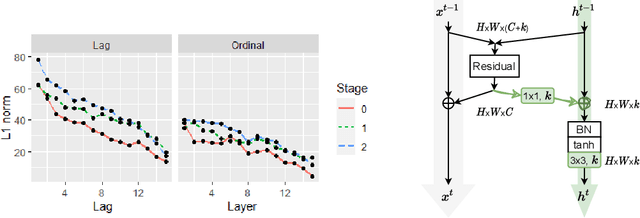
This paper introduces a concept of layer aggregation to describe how information from previous layers can be reused to better extract features at the current layer. While DenseNet is a typical example of the layer aggregation mechanism, its redundancy has been commonly criticized in the literature. This motivates us to propose a very light-weighted module, called recurrent layer aggregation (RLA), by making use of the sequential structure of layers in a deep CNN. Our RLA module is compatible with many mainstream deep CNNs, including ResNets, Xception and MobileNetV2, and its effectiveness is verified by our extensive experiments on image classification, object detection and instance segmentation tasks. Specifically, improvements can be uniformly observed on CIFAR, ImageNet and MS COCO datasets, and the corresponding RLA-Nets can surprisingly boost the performances by 2-3% on the object detection task. This evidences the power of our RLA module in helping main CNNs better learn structural information in images.
Dual-Attention Enhanced BDense-UNet for Liver Lesion Segmentation
Jul 24, 2021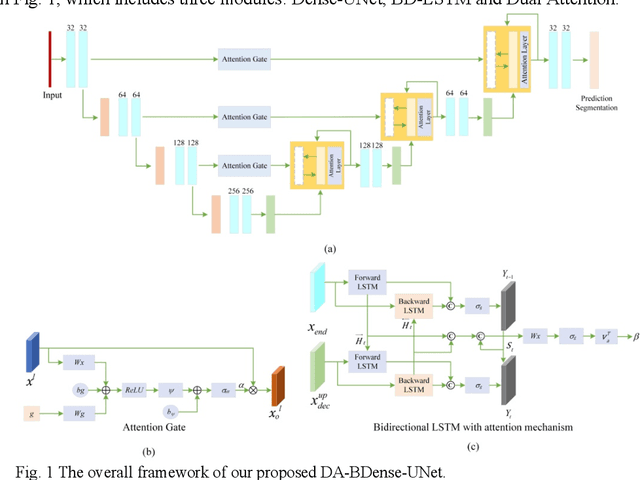
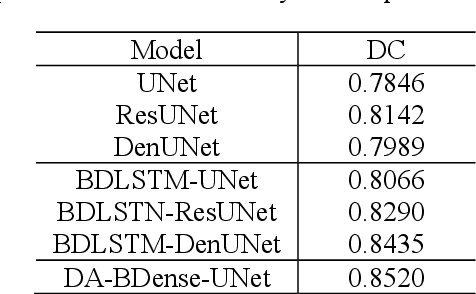
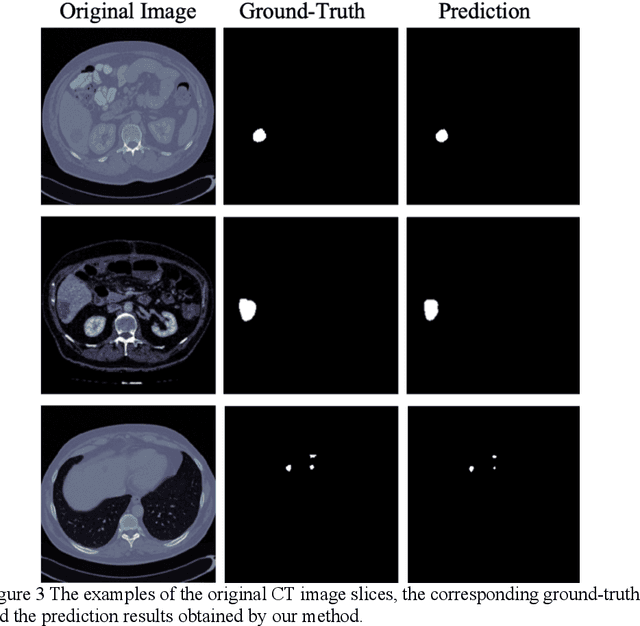
In this work, we propose a new segmentation network by integrating DenseUNet and bidirectional LSTM together with attention mechanism, termed as DA-BDense-UNet. DenseUNet allows learning enough diverse features and enhancing the representative power of networks by regulating the information flow. Bidirectional LSTM is responsible to explore the relationships between the encoded features and the up-sampled features in the encoding and decoding paths. Meanwhile, we introduce attention gates (AG) into DenseUNet to diminish responses of unrelated background regions and magnify responses of salient regions progressively. Besides, the attention in bidirectional LSTM takes into account the contribution differences of the encoded features and the up-sampled features in segmentation improvement, which can in turn adjust proper weights for these two kinds of features. We conduct experiments on liver CT image data sets collected from multiple hospitals by comparing them with state-of-the-art segmentation models. Experimental results indicate that our proposed method DA-BDense-UNet has achieved comparative performance in terms of dice coefficient, which demonstrates its effectiveness.
CNN-based Realized Covariance Matrix Forecasting
Jul 22, 2021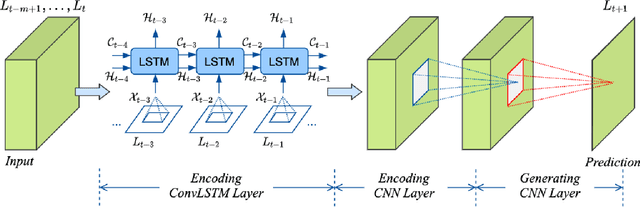
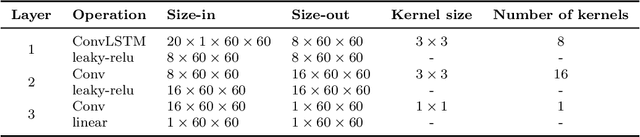
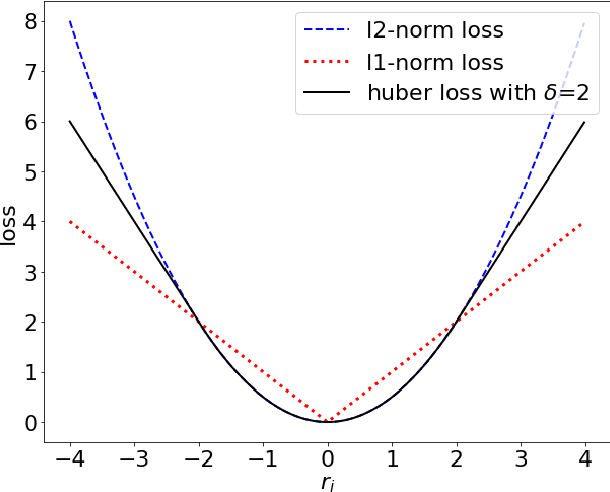
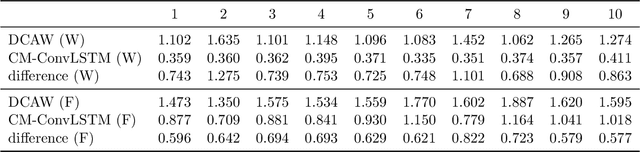
It is well known that modeling and forecasting realized covariance matrices of asset returns play a crucial role in the field of finance. The availability of high frequency intraday data enables the modeling of the realized covariance matrices directly. However, most of the models available in the literature depend on strong structural assumptions and they often suffer from the curse of dimensionality. We propose an end-to-end trainable model built on the CNN and Convolutional LSTM (ConvLSTM) which does not require to make any distributional or structural assumption but could handle high-dimensional realized covariance matrices consistently. The proposed model focuses on local structures and spatiotemporal correlations. It learns a nonlinear mapping that connect the historical realized covariance matrices to the future one. Our empirical studies on synthetic and real-world datasets demonstrate its excellent forecasting ability compared with several advanced volatility models.