 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyStory: Towards Unified Single and Multiple Subject Personalization in Text-to-Image Generation
Jan 16, 2025Recently, large-scale generative models have demonstrated outstanding text-to-image generation capabilities. However, generating high-fidelity personalized images with specific subjects still presents challenges, especially in cases involving multiple subjects. In this paper, we propose AnyStory, a unified approach for personalized subject generation. AnyStory not only achieves high-fidelity personalization for single subjects, but also for multiple subjects, without sacrificing subject fidelity. Specifically, AnyStory models the subject personalization problem in an "encode-then-route" manner. In the encoding step, AnyStory utilizes a universal and powerful image encoder, i.e., ReferenceNet, in conjunction with CLIP vision encoder to achieve high-fidelity encoding of subject features. In the routing step, AnyStory utilizes a decoupled instance-aware subject router to accurately perceive and predict the potential location of the corresponding subject in the latent space, and guide the injection of subject conditions. Detailed experimental results demonstrate the excellent performance of our method in retaining subject details, aligning text descriptions, and personalizing for multiple subjects. The project page is at https://aigcdesigngroup.github.io/AnyStory/ .
AnyText2: Visual Text Generation and Editing With Customizable Attributes
Nov 22, 2024

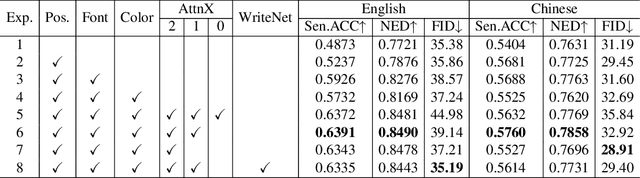

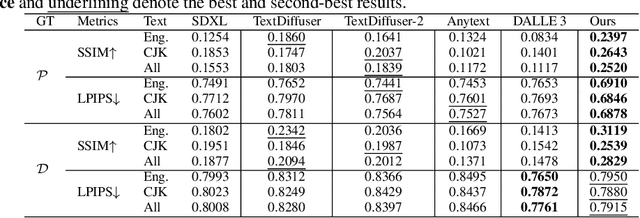
As the text-to-image (T2I) domain progresses, generating text that seamlessly integrates with visual content has garnered significant attention. However, even with accurate text generation, the inability to control font and color can greatly limit certain applications, and this issue remains insufficiently addressed. This paper introduces AnyText2, a novel method that enables precise control over multilingual text attributes in natural scene image generation and editing. Our approach consists of two main components. First, we propose a WriteNet+AttnX architecture that injects text rendering capabilities into a pre-trained T2I model. Compared to its predecessor, AnyText, our new approach not only enhances image realism but also achieves a 19.8% increase in inference speed. Second, we explore techniques for extracting fonts and colors from scene images and develop a Text Embedding Module that encodes these text attributes separately as conditions. As an extension of AnyText, this method allows for customization of attributes for each line of text, leading to improvements of 3.3% and 9.3% in text accuracy for Chinese and English, respectively. Through comprehensive experiments, we demonstrate the state-of-the-art performance of our method. The code and model will be made open-source in https://github.com/tyxsspa/AnyText2.
GLDesigner: Leveraging Multi-Modal LLMs as Designer for Enhanced Aesthetic Text Glyph Layouts
Nov 18, 2024

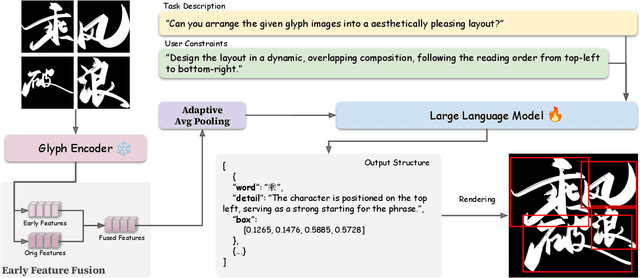
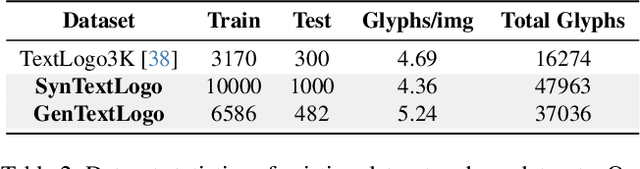
Text logo design heavily relies on the creativity and expertise of professional designers, in which arranging element layouts is one of the most important procedures. However, few attention has been paid to this specific task which needs to take precise textural details and user constraints into consideration, but only on the broader tasks such as document/poster layout generation. In this paper, we propose a VLM-based framework that generates content-aware text logo layouts by integrating multi-modal inputs with user constraints, supporting a more flexible and stable layout design in real-world applications. We introduce two model techniques to reduce the computation for processing multiple glyph images simultaneously, while does not face performance degradation. To support instruction-tuning of out model, we construct two extensive text logo datasets, which are 5x more larger than the existing public dataset. Except for the geometric annotations (e.g. text masks and character recognition), we also compliment with comprehensive layout descriptions in natural language format, for more effective training to have reasoning ability when dealing with complex layouts and custom user constraints. Experimental studies demonstrate the effectiveness of our proposed model and datasets, when comparing with previous methods in various benchmarks to evaluate geometric aesthetics and human preferences. The code and datasets will be publicly available.
Prune and Repaint: Content-Aware Image Retargeting for any Ratio
Oct 30, 2024



Image retargeting is the task of adjusting the aspect ratio of images to suit different display devices or presentation environments. However, existing retargeting methods often struggle to balance the preservation of key semantics and image quality, resulting in either deformation or loss of important objects, or the introduction of local artifacts such as discontinuous pixels and inconsistent regenerated content. To address these issues, we propose a content-aware retargeting method called PruneRepaint. It incorporates semantic importance for each pixel to guide the identification of regions that need to be pruned or preserved in order to maintain key semantics. Additionally, we introduce an adaptive repainting module that selects image regions for repainting based on the distribution of pruned pixels and the proportion between foreground size and target aspect ratio, thus achieving local smoothness after pruning. By focusing on the content and structure of the foreground, our PruneRepaint approach adaptively avoids key content loss and deformation, while effectively mitigating artifacts with local repainting. We conduct experiments on the public RetargetMe benchmark and demonstrate through objective experimental results and subjective user studies that our method outperforms previous approaches in terms of preserving semantics and aesthetics, as well as better generalization across diverse aspect ratios. Codes will be available at https://github.com/fhshen2022/PruneRepaint.
AdaptiveDrag: Semantic-Driven Dragging on Diffusion-Based Image Editing
Oct 16, 2024



Recently, several point-based image editing methods (e.g., DragDiffusion, FreeDrag, DragNoise) have emerged, yielding precise and high-quality results based on user instructions. However, these methods often make insufficient use of semantic information, leading to less desirable results. In this paper, we proposed a novel mask-free point-based image editing method, AdaptiveDrag, which provides a more flexible editing approach and generates images that better align with user intent. Specifically, we design an auto mask generation module using super-pixel division for user-friendliness. Next, we leverage a pre-trained diffusion model to optimize the latent, enabling the dragging of features from handle points to target points. To ensure a comprehensive connection between the input image and the drag process, we have developed a semantic-driven optimization. We design adaptive steps that are supervised by the positions of the points and the semantic regions derived from super-pixel segmentation. This refined optimization process also leads to more realistic and accurate drag results. Furthermore, to address the limitations in the generative consistency of the diffusion model, we introduce an innovative corresponding loss during the sampling process. Building on these effective designs, our method delivers superior generation results using only the single input image and the handle-target point pairs. Extensive experiments have been conducted and demonstrate that the proposed method outperforms others in handling various drag instructions (e.g., resize, movement, extension) across different domains (e.g., animals, human face, land space, clothing).
UniPortrait: A Unified Framework for Identity-Preserving Single- and Multi-Human Image Personalization
Aug 12, 2024



This paper presents UniPortrait, an innovative human image personalization framework that unifies single- and multi-ID customization with high face fidelity, extensive facial editability, free-form input description, and diverse layout generation. UniPortrait consists of only two plug-and-play modules: an ID embedding module and an ID routing module. The ID embedding module extracts versatile editable facial features with a decoupling strategy for each ID and embeds them into the context space of diffusion models. The ID routing module then combines and distributes these embeddings adaptively to their respective regions within the synthesized image, achieving the customization of single and multiple IDs. With a carefully designed two-stage training scheme, UniPortrait achieves superior performance in both single- and multi-ID customization. Quantitative and qualitative experiments demonstrate the advantages of our method over existing approaches as well as its good scalability, e.g., the universal compatibility with existing generative control tools. The project page is at https://aigcdesigngroup.github.io/UniPortrait-Page/ .
MetaDesigner: Advancing Artistic Typography through AI-Driven, User-Centric, and Multilingual WordArt Synthesis
Jun 28, 2024
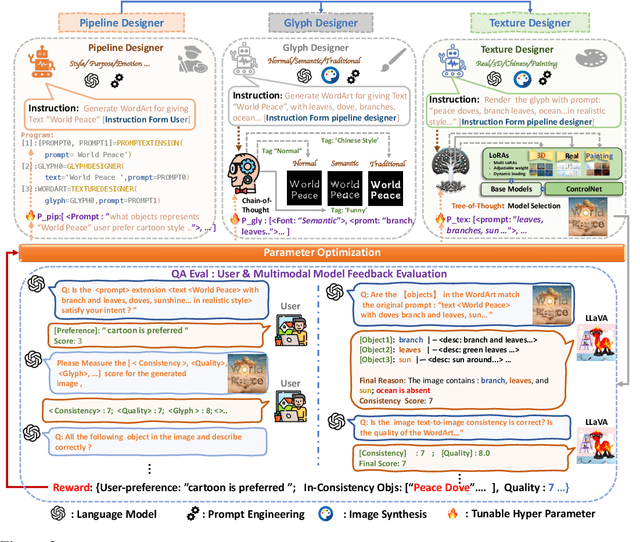
MetaDesigner revolutionizes artistic typography synthesis by leveraging the strengths of Large Language Models (LLMs) to drive a design paradigm centered around user engagement. At the core of this framework lies a multi-agent system comprising the Pipeline, Glyph, and Texture agents, which collectively enable the creation of customized WordArt, ranging from semantic enhancements to the imposition of complex textures. MetaDesigner incorporates a comprehensive feedback mechanism that harnesses insights from multimodal models and user evaluations to refine and enhance the design process iteratively. Through this feedback loop, the system adeptly tunes hyperparameters to align with user-defined stylistic and thematic preferences, generating WordArt that not only meets but exceeds user expectations of visual appeal and contextual relevance. Empirical validations highlight MetaDesigner's capability to effectively serve diverse WordArt applications, consistently producing aesthetically appealing and context-sensitive results.
VirtualModel: Generating Object-ID-retentive Human-object Interaction Image by Diffusion Model for E-commerce Marketing
May 16, 2024Due to the significant advances in large-scale text-to-image generation by diffusion model (DM), controllable human image generation has been attracting much attention recently. Existing works, such as Controlnet [36], T2I-adapter [20] and HumanSD [10] have demonstrated good abilities in generating human images based on pose conditions, they still fail to meet the requirements of real e-commerce scenarios. These include (1) the interaction between the shown product and human should be considered, (2) human parts like face/hand/arm/foot and the interaction between human model and product should be hyper-realistic, and (3) the identity of the product shown in advertising should be exactly consistent with the product itself. To this end, in this paper, we first define a new human image generation task for e-commerce marketing, i.e., Object-ID-retentive Human-object Interaction image Generation (OHG), and then propose a VirtualModel framework to generate human images for product shown, which supports displays of any categories of products and any types of human-object interaction. As shown in Figure 1, VirtualModel not only outperforms other methods in terms of accurate pose control and image quality but also allows for the display of user-specified product objects by maintaining the product-ID consistency and enhancing the plausibility of human-object interaction. Codes and data will be released.
ShoeModel: Learning to Wear on the User-specified Shoes via Diffusion Model
Apr 07, 2024



With the development of the large-scale diffusion model, Artificial Intelligence Generated Content (AIGC) techniques are popular recently. However, how to truly make it serve our daily lives remains an open question. To this end, in this paper, we focus on employing AIGC techniques in one filed of E-commerce marketing, i.e., generating hyper-realistic advertising images for displaying user-specified shoes by human. Specifically, we propose a shoe-wearing system, called Shoe-Model, to generate plausible images of human legs interacting with the given shoes. It consists of three modules: (1) shoe wearable-area detection module (WD), (2) leg-pose synthesis module (LpS) and the final (3) shoe-wearing image generation module (SW). Them three are performed in ordered stages. Compared to baselines, our ShoeModel is shown to generalize better to different type of shoes and has ability of keeping the ID-consistency of the given shoes, as well as automatically producing reasonable interactions with human. Extensive experiments show the effectiveness of our proposed shoe-wearing system. Figure 1 shows the input and output examples of our ShoeModel.
Strictly-ID-Preserved and Controllable Accessory Advertising Image Generation
Apr 07, 2024



Customized generative text-to-image models have the ability to produce images that closely resemble a given subject. However, in the context of generating advertising images for e-commerce scenarios, it is crucial that the generated subject's identity aligns perfectly with the product being advertised. In order to address the need for strictly-ID preserved advertising image generation, we have developed a Control-Net based customized image generation pipeline and have taken earring model advertising as an example. Our approach facilitates a seamless interaction between the earrings and the model's face, while ensuring that the identity of the earrings remains intact. Furthermore, to achieve a diverse and controllable display, we have proposed a multi-branch cross-attention architecture, which allows for control over the scale, pose, and appearance of the model, going beyond the limitations of text prompts. Our method manages to achieve fine-grained control of the generated model's face, resulting in controllable and captivating advertising effects.