 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-OPD: Bridging Offline SFT and Online RL for Vision-Language-Action Models via On-Policy Distillation
Mar 27, 2026Although pre-trained Vision-Language-Action (VLA) models exhibit impressive generalization in robotic manipulation, post-training remains crucial to ensure reliable performance during deployment. However, standard offline Supervised Fine-Tuning (SFT) suffers from distribution shifts and catastrophic forgetting of pre-trained capabilities, while online Reinforcement Learning (RL) struggles with sparse rewards and poor sample efficiency. In this paper, we propose On-Policy VLA Distillation (VLA-OPD), a framework bridging the efficiency of SFT with the robustness of RL. Instead of relying on sparse environmental rewards, VLA-OPD leverages an expert teacher to provide dense, token-level supervision on the student's self-generated trajectories. This enables active error correction on policy-induced states while preserving pre-trained general capabilities through gentle alignment. Crucially, we formulate VLA-OPD via a Reverse-KL objective. Unlike standard Forward-KL that induces mode-covering entropy explosion, or Hard-CE that causes premature entropy collapse, our bounded mode-seeking objective ensures stable policy learning by filtering out the teacher's epistemic uncertainty while maintaining action diversity. Experiments on LIBERO and RoboTwin2.0 benchmarks demonstrate that VLA-OPD significantly improves sample efficiency over RL and robustness over SFT, while effectively mitigating catastrophic forgetting during post-training.
DualCoT-VLA: Visual-Linguistic Chain of Thought via Parallel Reasoning for Vision-Language-Action Models
Mar 23, 2026Vision-Language-Action (VLA) models map visual observations and language instructions directly to robotic actions. While effective for simple tasks, standard VLA models often struggle with complex, multi-step tasks requiring logical planning, as well as precise manipulations demanding fine-grained spatial perception. Recent efforts have incorporated Chain-of-Thought (CoT) reasoning to endow VLA models with a ``thinking before acting'' capability. However, current CoT-based VLA models face two critical limitations: 1) an inability to simultaneously capture low-level visual details and high-level logical planning due to their reliance on isolated, single-modal CoT; 2) high inference latency with compounding errors caused by step-by-step autoregressive decoding. To address these limitations, we propose DualCoT-VLA, a visual-linguistic CoT method for VLA models with a parallel reasoning mechanism. To achieve comprehensive multi-modal reasoning, our method integrates a visual CoT for low-level spatial understanding and a linguistic CoT for high-level task planning. Furthermore, to overcome the latency bottleneck, we introduce a parallel CoT mechanism that incorporates two sets of learnable query tokens, shifting autoregressive reasoning to single-step forward reasoning. Extensive experiments demonstrate that our DualCoT-VLA achieves state-of-the-art performance on the LIBERO and RoboCasa GR1 benchmarks, as well as in real-world platforms.
S-VAM: Shortcut Video-Action Model by Self-Distilling Geometric and Semantic Foresight
Mar 17, 2026Video action models (VAMs) have emerged as a promising paradigm for robot learning, owing to their powerful visual foresight for complex manipulation tasks. However, current VAMs, typically relying on either slow multi-step video generation or noisy one-step feature extraction, cannot simultaneously guarantee real-time inference and high-fidelity foresight. To address this limitation, we propose S-VAM, a shortcut video-action model that foresees coherent geometric and semantic representations via a single forward pass. Serving as a stable blueprint, these foreseen representations significantly simplify the action prediction. To enable this efficient shortcut, we introduce a novel self-distillation strategy that condenses structured generative priors of multi-step denoising into one-step inference. Specifically, vision foundation model (VFM) representations extracted from the diffusion model's own multi-step generated videos provide teacher targets. Lightweight decouplers, as students, learn to directly map noisy one-step features to these targets. Extensive experiments in simulation and the real world demonstrate that our S-VAM outperforms state-of-the-art methods, enabling efficient and precise manipulation in complex environments. Our project page is https://haodong-yan.github.io/S-VAM/
PROSPECT: Unified Streaming Vision-Language Navigation via Semantic--Spatial Fusion and Latent Predictive Representation
Mar 04, 2026Multimodal large language models (MLLMs) have advanced zero-shot end-to-end Vision-Language Navigation (VLN), yet robust navigation requires not only semantic understanding but also predictive modeling of environment dynamics and spatial structure. We propose PROSPECT, a unified streaming navigation agent that couples a streaming Vision-Language-Action (VLA) policy with latent predictive representation learning. PROSPECT uses CUT3R as a streaming 3D foundation spatial encoder to produce long-context, absolute-scale spatial features, and fuses them with SigLIP semantic features via cross-attention. During training, we introduce learnable stream query tokens that query the streaming context and predict next-step 2D and 3D latent features (rather than pixels or explicit modalities), supervised in the latent spaces of frozen SigLIP and CUT3R teachers. The predictive branch shapes internal representations without inference overhead. Experiments on VLN-CE benchmarks and real-robot deployment demonstrate state-of-the-art performance and improved long-horizon robustness under diverse lighting. We will release code for the community soon.
VPGS-SLAM: Voxel-based Progressive 3D Gaussian SLAM in Large-Scale Scenes
May 25, 2025



3D Gaussian Splatting has recently shown promising results in dense visual SLAM. However, existing 3DGS-based SLAM methods are all constrained to small-room scenarios and struggle with memory explosion in large-scale scenes and long sequences. To this end, we propose VPGS-SLAM, the first 3DGS-based large-scale RGBD SLAM framework for both indoor and outdoor scenarios. We design a novel voxel-based progressive 3D Gaussian mapping method with multiple submaps for compact and accurate scene representation in large-scale and long-sequence scenes. This allows us to scale up to arbitrary scenes and improves robustness (even under pose drifts). In addition, we propose a 2D-3D fusion camera tracking method to achieve robust and accurate camera tracking in both indoor and outdoor large-scale scenes. Furthermore, we design a 2D-3D Gaussian loop closure method to eliminate pose drift. We further propose a submap fusion method with online distillation to achieve global consistency in large-scale scenes when detecting a loop. Experiments on various indoor and outdoor datasets demonstrate the superiority and generalizability of the proposed framework. The code will be open source on https://github.com/dtc111111/vpgs-slam.
Sensing-Assisted Channel Prediction in Complex Wireless Environments: An LLM-Based Approach
May 14, 2025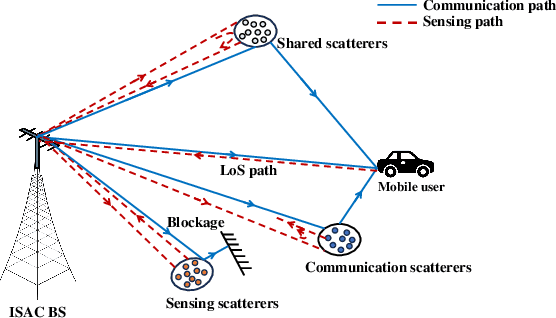
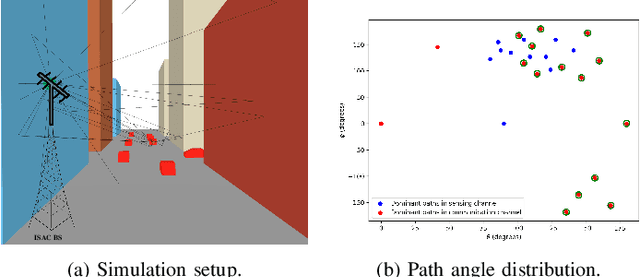
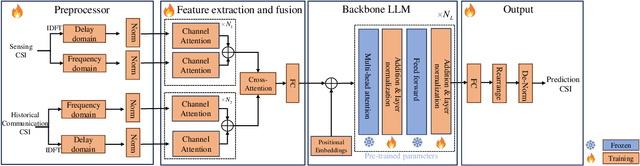
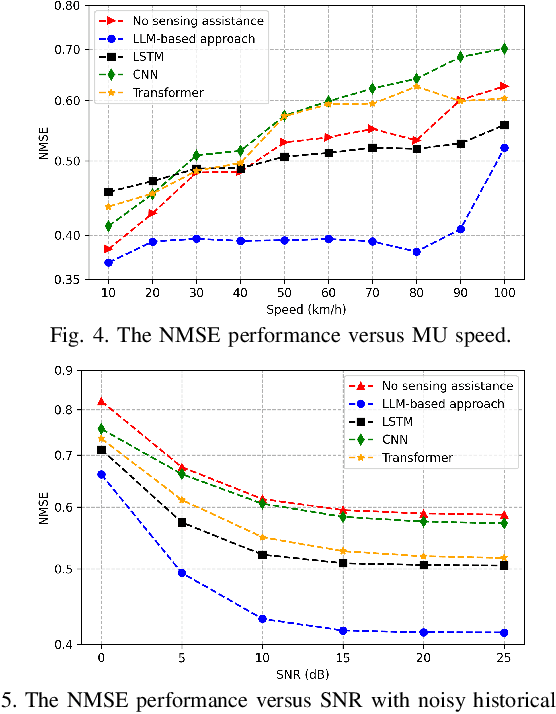
This letter studies the sensing-assisted channel prediction for a multi-antenna orthogonal frequency division multiplexing (OFDM) system operating in realistic and complex wireless environments. In this system,an integrated sensing and communication (ISAC) transmitter leverages the mono-static sensing capability to facilitate the prediction of its bi-static communication channel, by exploiting the fact that the sensing and communication channels share the same physical environment involving shared scatterers. Specifically, we propose a novel large language model (LLM)-based channel prediction approach,which adapts pre-trained text-based LLM to handle the complex-matrix-form channel state information (CSI) data. This approach utilizes the LLM's strong ability to capture the intricate spatiotemporal relationships between the multi-path sensing and communication channels, and thus efficiently predicts upcoming communication CSI based on historical communication and sensing CSI data. Experimental results show that the proposed LLM-based approach significantly outperforms conventional deep learning-based methods and the benchmark scheme without sensing assistance.
AnyStory: Towards Unified Single and Multiple Subject Personalization in Text-to-Image Generation
Jan 16, 2025



Recently, large-scale generative models have demonstrated outstanding text-to-image generation capabilities. However, generating high-fidelity personalized images with specific subjects still presents challenges, especially in cases involving multiple subjects. In this paper, we propose AnyStory, a unified approach for personalized subject generation. AnyStory not only achieves high-fidelity personalization for single subjects, but also for multiple subjects, without sacrificing subject fidelity. Specifically, AnyStory models the subject personalization problem in an "encode-then-route" manner. In the encoding step, AnyStory utilizes a universal and powerful image encoder, i.e., ReferenceNet, in conjunction with CLIP vision encoder to achieve high-fidelity encoding of subject features. In the routing step, AnyStory utilizes a decoupled instance-aware subject router to accurately perceive and predict the potential location of the corresponding subject in the latent space, and guide the injection of subject conditions. Detailed experimental results demonstrate the excellent performance of our method in retaining subject details, aligning text descriptions, and personalizing for multiple subjects. The project page is at https://aigcdesigngroup.github.io/AnyStory/ .
UniPortrait: A Unified Framework for Identity-Preserving Single- and Multi-Human Image Personalization
Aug 12, 2024



This paper presents UniPortrait, an innovative human image personalization framework that unifies single- and multi-ID customization with high face fidelity, extensive facial editability, free-form input description, and diverse layout generation. UniPortrait consists of only two plug-and-play modules: an ID embedding module and an ID routing module. The ID embedding module extracts versatile editable facial features with a decoupling strategy for each ID and embeds them into the context space of diffusion models. The ID routing module then combines and distributes these embeddings adaptively to their respective regions within the synthesized image, achieving the customization of single and multiple IDs. With a carefully designed two-stage training scheme, UniPortrait achieves superior performance in both single- and multi-ID customization. Quantitative and qualitative experiments demonstrate the advantages of our method over existing approaches as well as its good scalability, e.g., the universal compatibility with existing generative control tools. The project page is at https://aigcdesigngroup.github.io/UniPortrait-Page/ .
LIV-GaussMap: LiDAR-Inertial-Visual Fusion for Real-time 3D Radiance Field Map Rendering
Jan 26, 2024



We introduce an integrated precise LiDAR, Inertial, and Visual (LIV) multi-modal sensor fused mapping system that builds on the differentiable surface splatting to improve the mapping fidelity, quality, and structural accuracy. Notably, this is also a novel form of tightly coupled map for LiDAR-visual-inertial sensor fusion. This system leverages the complementary characteristics of LiDAR and visual data to capture the geometric structures of large-scale 3D scenes and restore their visual surface information with high fidelity. The initial poses for surface Gaussian scenes are obtained using a LiDAR-inertial system with size-adaptive voxels. Then, we optimized and refined the Gaussians by visual-derived photometric gradients to optimize the quality and density of LiDAR measurements. Our method is compatible with various types of LiDAR, including solid-state and mechanical LiDAR, supporting both repetitive and non-repetitive scanning modes. bolstering structure construction through LiDAR and facilitating real-time generation of photorealistic renderings across diverse LIV datasets. It showcases notable resilience and versatility in generating real-time photorealistic scenes potentially for digital twins and virtual reality while also holding potential applicability in real-time SLAM and robotics domains. We release our software and hardware and self-collected datasets on Github\footnote[3]{https://github.com/sheng00125/LIV-GaussMap} to benefit the community.
FastInst: A Simple Query-Based Model for Real-Time Instance Segmentation
Apr 01, 2023



Recent attention in instance segmentation has focused on query-based models. Despite being non-maximum suppression (NMS)-free and end-to-end, the superiority of these models on high-accuracy real-time benchmarks has not been well demonstrated. In this paper, we show the strong potential of query-based models on efficient instance segmentation algorithm designs. We present FastInst, a simple, effective query-based framework for real-time instance segmentation. FastInst can execute at a real-time speed (i.e., 32.5 FPS) while yielding an AP of more than 40 (i.e., 40.5 AP) on COCO test-dev without bells and whistles. Specifically, FastInst follows the meta-architecture of recently introduced Mask2Former. Its key designs include instance activation-guided queries, dual-path update strategy, and ground truth mask-guided learning, which enable us to use lighter pixel decoders, fewer Transformer decoder layers, while achieving better performance. The experiments show that FastInst outperforms most state-of-the-art real-time counterparts, including strong fully convolutional baselines, in both speed and accuracy. Code can be found at https://github.com/junjiehe96/FastInst .