 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParametrization of subgrid scales in long-term simulations of the shallow-water equations using machine learning and convex limiting
Jan 30, 2026We present a method for parametrizing sub-grid processes in the Shallow Water equations. We define coarse variables and local spatial averages and use a feed-forward neural network to learn sub-grid fluxes. Our method results in a local parametrization that uses a four-point computational stencil, which has several advantages over globally coupled parametrizations. We demonstrate numerically that our method improves energy balance in long-term turbulent simulations and also accurately reproduces individual solutions. The neural network parametrization can be easily combined with flux limiting to reduce oscillations near shocks. More importantly, our method provides reliable parametrizations, even in dynamical regimes that are not included in the training data.
MuLanTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2023
Sep 12, 2023In this paper, we present MuLanTTS, the Microsoft end-to-end neural text-to-speech (TTS) system designed for the Blizzard Challenge 2023. About 50 hours of audiobook corpus for French TTS as hub task and another 2 hours of speaker adaptation as spoke task are released to build synthesized voices for different test purposes including sentences, paragraphs, homographs, lists, etc. Building upon DelightfulTTS, we adopt contextual and emotion encoders to adapt the audiobook data to enrich beyond sentences for long-form prosody and dialogue expressiveness. Regarding the recording quality, we also apply denoise algorithms and long audio processing for both corpora. For the hub task, only the 50-hour single speaker data is used for building the TTS system, while for the spoke task, a multi-speaker source model is used for target speaker fine tuning. MuLanTTS achieves mean scores of quality assessment 4.3 and 4.5 in the respective tasks, statistically comparable with natural speech while keeping good similarity according to similarity assessment. The excellent and similarity in this year's new and dense statistical evaluation show the effectiveness of our proposed system in both tasks.
Deep neural network based adaptive learning for switched systems
Jul 11, 2022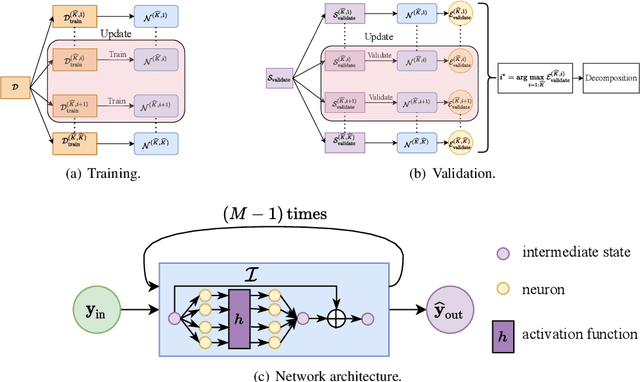

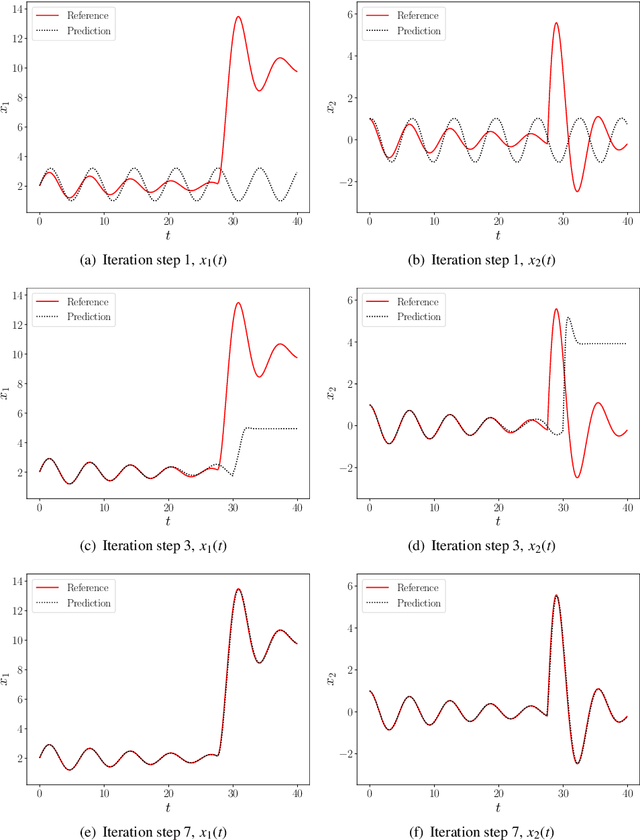
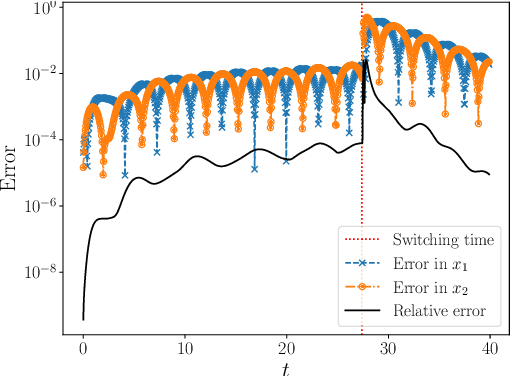
In this paper, we present a deep neural network based adaptive learning (DNN-AL) approach for switched systems. Currently, deep neural network based methods are actively developed for learning governing equations in unknown dynamic systems, but their efficiency can degenerate for switching systems, where structural changes exist at discrete time instants. In this new DNN-AL strategy, observed datasets are adaptively decomposed into subsets, such that no structural changes within each subset. During the adaptive procedures, DNNs are hierarchically constructed, and unknown switching time instants are gradually identified. Especially, network parameters at previous iteration steps are reused to initialize networks for the later iteration steps, which gives efficient training procedures for the DNNs. For the DNNs obtained through our DNN-AL, bounds of the prediction error are established. Numerical studies are conducted to demonstrate the efficiency of DNN-AL.
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021
Nov 19, 2021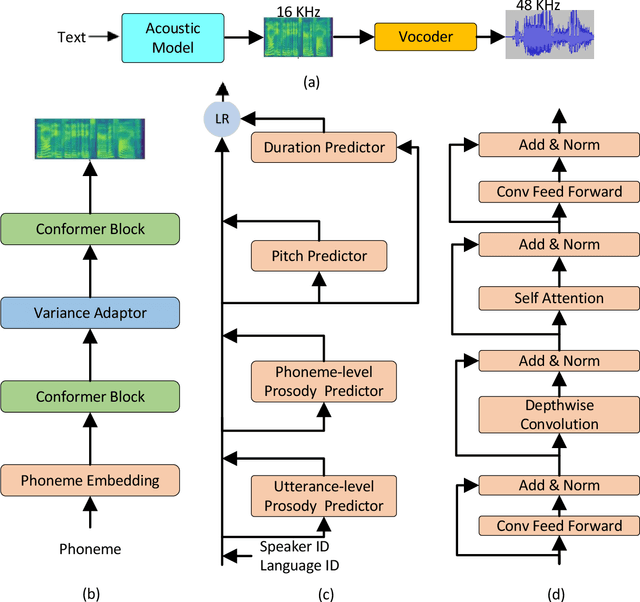
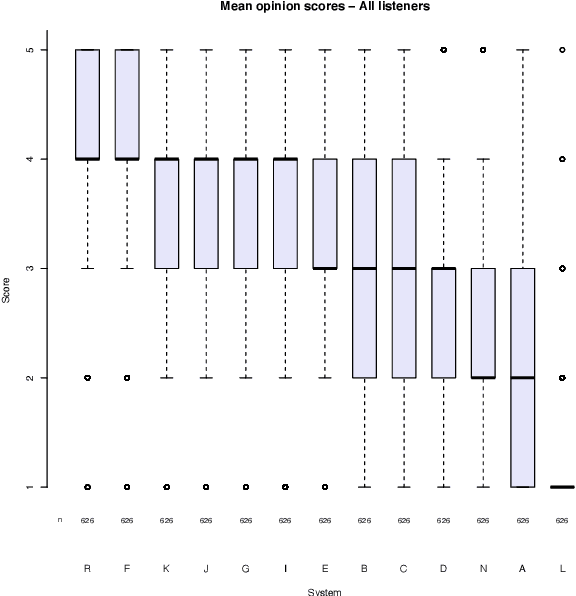
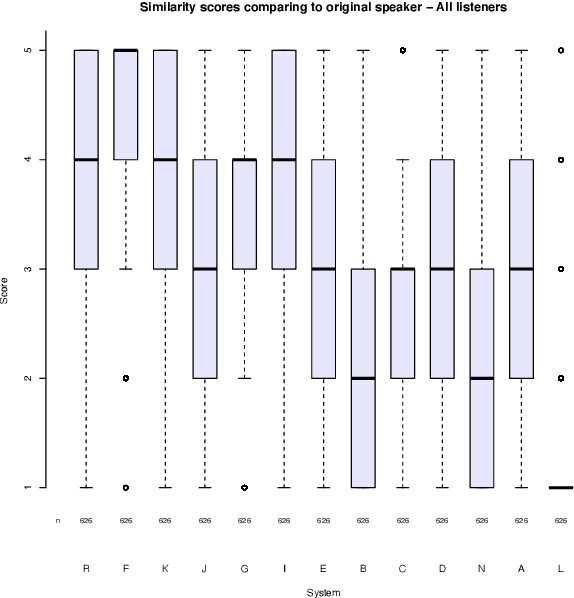
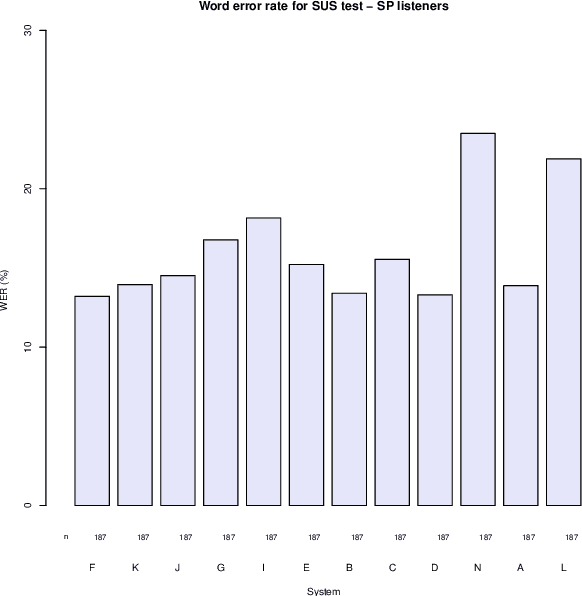
This paper describes the Microsoft end-to-end neural text to speech (TTS) system: DelightfulTTS for Blizzard Challenge 2021. The goal of this challenge is to synthesize natural and high-quality speech from text, and we approach this goal in two perspectives: The first is to directly model and generate waveform in 48 kHz sampling rate, which brings higher perception quality than previous systems with 16 kHz or 24 kHz sampling rate; The second is to model the variation information in speech through a systematic design, which improves the prosody and naturalness. Specifically, for 48 kHz modeling, we predict 16 kHz mel-spectrogram in acoustic model, and propose a vocoder called HiFiNet to directly generate 48 kHz waveform from predicted 16 kHz mel-spectrogram, which can better trade off training efficiency, modelling stability and voice quality. We model variation information systematically from both explicit (speaker ID, language ID, pitch and duration) and implicit (utterance-level and phoneme-level prosody) perspectives: 1) For speaker and language ID, we use lookup embedding in training and inference; 2) For pitch and duration, we extract the values from paired text-speech data in training and use two predictors to predict the values in inference; 3) For utterance-level and phoneme-level prosody, we use two reference encoders to extract the values in training, and use two separate predictors to predict the values in inference. Additionally, we introduce an improved Conformer block to better model the local and global dependency in acoustic model. For task SH1, DelightfulTTS achieves 4.17 mean score in MOS test and 4.35 in SMOS test, which indicates the effectiveness of our proposed system