 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMIGO: Agentic Multi-Image Grounding Oracle Benchmark
Mar 30, 2026Agentic vision-language models increasingly act through extended interactions, but most evaluations still focus on single-image, single-turn correctness. We introduce AMIGO (Agentic Multi-Image Grounding Oracle Benchmark), a long-horizon benchmark for hidden-target identification over galleries of visually similar images. In AMIGO, the oracle privately selects a target image, and the model must recover it by asking a sequence of attribute-focused Yes/No/Unsure questions under a strict protocol that penalizes invalid actions with Skip. This setting stresses (i) question selection under uncertainty, (ii) consistent constraint tracking across turns, and (iii) fine-grained discrimination as evidence accumulates. AMIGO also supports controlled oracle imperfections to probe robustness and verification behavior under inconsistent feedback. We instantiate AMIGO with Guess My Preferred Dress task and report metrics covering both outcomes and interaction quality, including identification success, evidence verification, efficiency, protocol compliance, noise tolerance, and trajectory-level diagnostics.
Structural Action Transformer for 3D Dexterous Manipulation
Mar 04, 2026Achieving human-level dexterity in robots via imitation learning from heterogeneous datasets is hindered by the challenge of cross-embodiment skill transfer, particularly for high-DoF robotic hands. Existing methods, often relying on 2D observations and temporal-centric action representation, struggle to capture 3D spatial relations and fail to handle embodiment heterogeneity. This paper proposes the Structural Action Transformer (SAT), a new 3D dexterous manipulation policy that challenges this paradigm by introducing a structural-centric perspective. We reframe each action chunk not as a temporal sequence, but as a variable-length, unordered sequence of joint-wise trajectories. This structural formulation allows a Transformer to natively handle heterogeneous embodiments, treating the joint count as a variable sequence length. To encode structural priors and resolve ambiguity, we introduce an Embodied Joint Codebook that embeds each joint's functional role and kinematic properties. Our model learns to generate these trajectories from 3D point clouds via a continuous-time flow matching objective. We validate our approach by pre-training on large-scale heterogeneous datasets and fine-tuning on simulation and real-world dexterous manipulation tasks. Our method consistently outperforms all baselines, demonstrating superior sample efficiency and effective cross-embodiment skill transfer. This structural-centric representation offers a new path toward scaling policies for high-DoF, heterogeneous manipulators.
Primary-Fine Decoupling for Action Generation in Robotic Imitation
Feb 25, 2026Multi-modal distribution in robotic manipulation action sequences poses critical challenges for imitation learning. To this end, existing approaches often model the action space as either a discrete set of tokens or a continuous, latent-variable distribution. However, both approaches present trade-offs: some methods discretize actions into tokens and therefore lose fine-grained action variations, while others generate continuous actions in a single stage tend to produce unstable mode transitions. To address these limitations, we propose Primary-Fine Decoupling for Action Generation (PF-DAG), a two-stage framework that decouples coarse action consistency from fine-grained variations. First, we compress action chunks into a small set of discrete modes, enabling a lightweight policy to select consistent coarse modes and avoid mode bouncing. Second, a mode conditioned MeanFlow policy is learned to generate high-fidelity continuous actions. Theoretically, we prove PF-DAG's two-stage design achieves a strictly lower MSE bound than single-stage generative policies. Empirically, PF-DAG outperforms state-of-the-art baselines across 56 tasks from Adroit, DexArt, and MetaWorld benchmarks. It further generalizes to real-world tactile dexterous manipulation tasks. Our work demonstrates that explicit mode-level decoupling enables both robust multi-modal modeling and reactive closed-loop control for robotic manipulation.
Parametrization of subgrid scales in long-term simulations of the shallow-water equations using machine learning and convex limiting
Jan 30, 2026We present a method for parametrizing sub-grid processes in the Shallow Water equations. We define coarse variables and local spatial averages and use a feed-forward neural network to learn sub-grid fluxes. Our method results in a local parametrization that uses a four-point computational stencil, which has several advantages over globally coupled parametrizations. We demonstrate numerically that our method improves energy balance in long-term turbulent simulations and also accurately reproduces individual solutions. The neural network parametrization can be easily combined with flux limiting to reduce oscillations near shocks. More importantly, our method provides reliable parametrizations, even in dynamical regimes that are not included in the training data.
Offline Meta-Reinforcement Learning with Flow-Based Task Inference and Adaptive Correction of Feature Overgeneralization
Jan 12, 2026Offline meta-reinforcement learning (OMRL) combines the strengths of learning from diverse datasets in offline RL with the adaptability to new tasks of meta-RL, promising safe and efficient knowledge acquisition by RL agents. However, OMRL still suffers extrapolation errors due to out-of-distribution (OOD) actions, compromised by broad task distributions and Markov Decision Process (MDP) ambiguity in meta-RL setups. Existing research indicates that the generalization of the $Q$ network affects the extrapolation error in offline RL. This paper investigates this relationship by decomposing the $Q$ value into feature and weight components, observing that while decomposition enhances adaptability and convergence in the case of high-quality data, it often leads to policy degeneration or collapse in complex tasks. We observe that decomposed $Q$ values introduce a large estimation bias when the feature encounters OOD samples, a phenomenon we term ''feature overgeneralization''. To address this issue, we propose FLORA, which identifies OOD samples by modeling feature distributions and estimating their uncertainties. FLORA integrates a return feedback mechanism to adaptively adjust feature components. Furthermore, to learn precise task representations, FLORA explicitly models the complex task distribution using a chain of invertible transformations. We theoretically and empirically demonstrate that FLORA achieves rapid adaptation and meta-policy improvement compared to baselines across various environments.
Wavelet Predictive Representations for Non-Stationary Reinforcement Learning
Oct 06, 2025The real world is inherently non-stationary, with ever-changing factors, such as weather conditions and traffic flows, making it challenging for agents to adapt to varying environmental dynamics. Non-Stationary Reinforcement Learning (NSRL) addresses this challenge by training agents to adapt rapidly to sequences of distinct Markov Decision Processes (MDPs). However, existing NSRL approaches often focus on tasks with regularly evolving patterns, leading to limited adaptability in highly dynamic settings. Inspired by the success of Wavelet analysis in time series modeling, specifically its ability to capture signal trends at multiple scales, we propose WISDOM to leverage wavelet-domain predictive task representations to enhance NSRL. WISDOM captures these multi-scale features in evolving MDP sequences by transforming task representation sequences into the wavelet domain, where wavelet coefficients represent both global trends and fine-grained variations of non-stationary changes. In addition to the auto-regressive modeling commonly employed in time series forecasting, we devise a wavelet temporal difference (TD) update operator to enhance tracking and prediction of MDP evolution. We theoretically prove the convergence of this operator and demonstrate policy improvement with wavelet task representations. Experiments on diverse benchmarks show that WISDOM significantly outperforms existing baselines in both sample efficiency and asymptotic performance, demonstrating its remarkable adaptability in complex environments characterized by non-stationary and stochastically evolving tasks.
Optimizing for the Shortest Path in Denoising Diffusion Model
Mar 06, 2025In this research, we propose a novel denoising diffusion model based on shortest-path modeling that optimizes residual propagation to enhance both denoising efficiency and quality. Drawing on Denoising Diffusion Implicit Models (DDIM) and insights from graph theory, our model, termed the Shortest Path Diffusion Model (ShortDF), treats the denoising process as a shortest-path problem aimed at minimizing reconstruction error. By optimizing the initial residuals, we improve the efficiency of the reverse diffusion process and the quality of the generated samples. Extensive experiments on multiple standard benchmarks demonstrate that ShortDF significantly reduces diffusion time (or steps) while enhancing the visual fidelity of generated samples compared to prior arts. This work, we suppose, paves the way for interactive diffusion-based applications and establishes a foundation for rapid data generation. Code is available at https://github.com/UnicomAI/ShortDF
Bright-NeRF:Brightening Neural Radiance Field with Color Restoration from Low-light Raw Images
Dec 19, 2024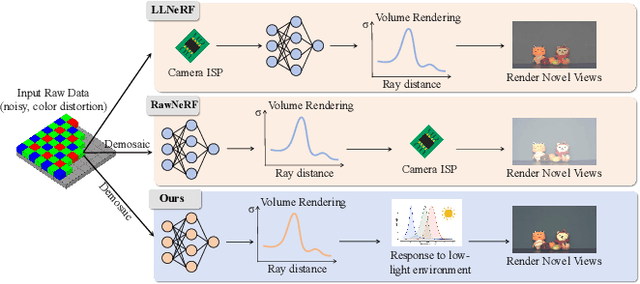
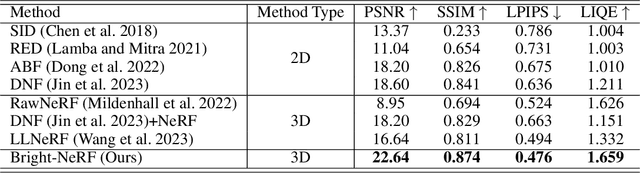
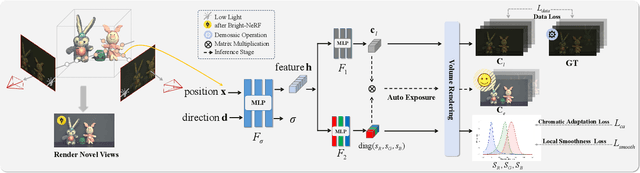
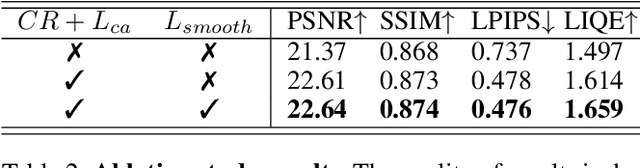
Neural Radiance Fields (NeRFs) have demonstrated prominent performance in novel view synthesis. However, their input heavily relies on image acquisition under normal light conditions, making it challenging to learn accurate scene representation in low-light environments where images typically exhibit significant noise and severe color distortion. To address these challenges, we propose a novel approach, Bright-NeRF, which learns enhanced and high-quality radiance fields from multi-view low-light raw images in an unsupervised manner. Our method simultaneously achieves color restoration, denoising, and enhanced novel view synthesis. Specifically, we leverage a physically-inspired model of the sensor's response to illumination and introduce a chromatic adaptation loss to constrain the learning of response, enabling consistent color perception of objects regardless of lighting conditions. We further utilize the raw data's properties to expose the scene's intensity automatically. Additionally, we have collected a multi-view low-light raw image dataset to advance research in this field. Experimental results demonstrate that our proposed method significantly outperforms existing 2D and 3D approaches. Our code and dataset will be made publicly available.
Superpixel-informed Implicit Neural Representation for Multi-Dimensional Data
Nov 18, 2024Recently, implicit neural representations (INRs) have attracted increasing attention for multi-dimensional data recovery. However, INRs simply map coordinates via a multi-layer perception (MLP) to corresponding values, ignoring the inherent semantic information of the data. To leverage semantic priors from the data, we propose a novel Superpixel-informed INR (S-INR). Specifically, we suggest utilizing generalized superpixel instead of pixel as an alternative basic unit of INR for multi-dimensional data (e.g., images and weather data). The coordinates of generalized superpixels are first fed into exclusive attention-based MLPs, and then the intermediate results interact with a shared dictionary matrix. The elaborately designed modules in S-INR allow us to ingenuously exploit the semantic information within and across generalized superpixels. Extensive experiments on various applications validate the effectiveness and efficacy of our S-INR compared to state-of-the-art INR methods.
Machine Learning Aided Modeling of Granular Materials: A Review
Oct 18, 2024Artificial intelligence (AI) has become a buzz word since Google's AlphaGo beat a world champion in 2017. In the past five years, machine learning as a subset of the broader category of AI has obtained considerable attention in the research community of granular materials. This work offers a detailed review of the recent advances in machine learning-aided studies of granular materials from the particle-particle interaction at the grain level to the macroscopic simulations of granular flow. This work will start with the application of machine learning in the microscopic particle-particle interaction and associated contact models. Then, different neural networks for learning the constitutive behaviour of granular materials will be reviewed and compared. Finally, the macroscopic simulations of practical engineering or boundary value problems based on the combination of neural networks and numerical methods are discussed. We hope readers will have a clear idea of the development of machine learning-aided modelling of granular materials via this comprehensive review work.