 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDTR: A Unified Deep Tensor Representation Framework for Multimedia Data Recovery
Jul 07, 2024



Recently, the transform-based tensor representation has attracted increasing attention in multimedia data (e.g., images and videos) recovery problems, which consists of two indispensable components, i.e., transform and characterization. Previously, the development of transform-based tensor representation mainly focuses on the transform aspect. Although several attempts consider using shallow matrix factorization (e.g., singular value decomposition and negative matrix factorization) to characterize the frontal slices of transformed tensor (termed as latent tensor), the faithful characterization aspect is underexplored. To address this issue, we propose a unified Deep Tensor Representation (termed as DTR) framework by synergistically combining the deep latent generative module and the deep transform module. Especially, the deep latent generative module can faithfully generate the latent tensor as compared with shallow matrix factorization. The new DTR framework not only allows us to better understand the classic shallow representations, but also leads us to explore new representation. To examine the representation ability of the proposed DTR, we consider the representative multi-dimensional data recovery task and suggest an unsupervised DTR-based multi-dimensional data recovery model. Extensive experiments demonstrate that DTR achieves superior performance compared to state-of-the-art methods in both quantitative and qualitative aspects, especially for fine details recovery.
Self-Supervised Nonlinear Transform-Based Tensor Nuclear Norm for Multi-Dimensional Image Recovery
May 29, 2021
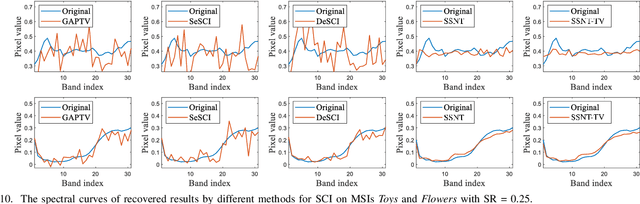

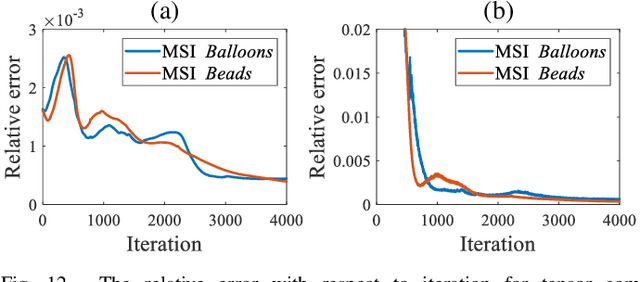
In this paper, we study multi-dimensional image recovery. Recently, transform-based tensor nuclear norm minimization methods are considered to capture low-rank tensor structures to recover third-order tensors in multi-dimensional image processing applications. The main characteristic of such methods is to perform the linear transform along the third mode of third-order tensors, and then compute tensor nuclear norm minimization on the transformed tensor so that the underlying low-rank tensors can be recovered. The main aim of this paper is to propose a nonlinear multilayer neural network to learn a nonlinear transform via the observed tensor data under self-supervision. The proposed network makes use of low-rank representation of transformed tensors and data-fitting between the observed tensor and the reconstructed tensor to construct the nonlinear transformation. Extensive experimental results on tensor completion, background subtraction, robust tensor completion, and snapshot compressive imaging are presented to demonstrate that the performance of the proposed method is better than that of state-of-the-art methods.
Unsupervised Hyperspectral Mixed Noise Removal Via Spatial-Spectral Constrained Deep Image Prior
Aug 22, 2020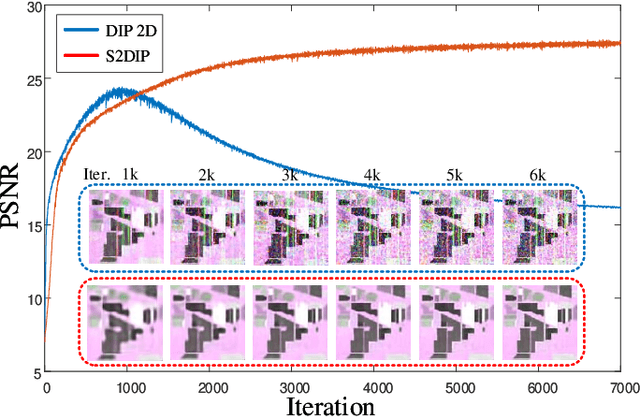

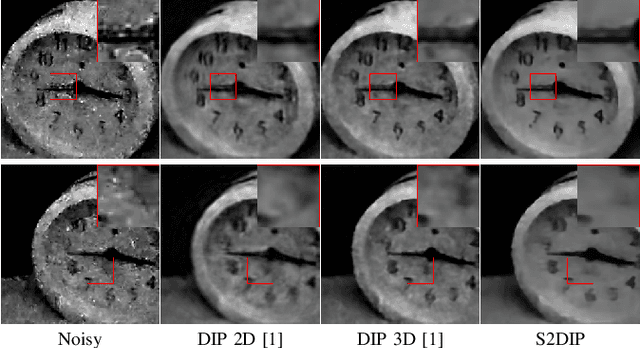
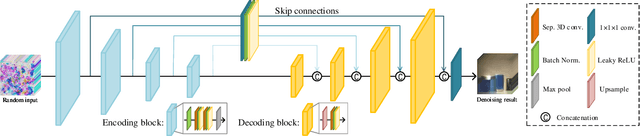
Hyperspectral images (HSIs) are unavoidably corrupted by mixed noise which hinders the subsequent applications. Traditional methods exploit the structure of the HSI via optimization-based models for denoising, while their capacity is inferior to the convolutional neural network (CNN)-based methods, which supervisedly learn the noisy-to-denoised mapping from a large amount of data. However, as the clean-noisy pairs of hyperspectral data are always unavailable in many applications, it is eager to build an unsupervised HSI denoising method with high model capability. To remove the mixed noise in HSIs, we suggest the spatial-spectral constrained deep image prior (S2DIP), which simultaneously capitalize the high model representation ability brought by the CNN in an unsupervised manner and does not need any extra training data. Specifically, we employ the separable 3D convolution blocks to faithfully encode the HSI in the framework of DIP, and a spatial-spectral total variation (SSTV) term is tailored to explore the spatial-spectral smoothness of HSIs. Moreover, our method favorably addresses the semi-convergence behavior of prevailing unsupervised methods, e.g., DIP 2D, and DIP 3D. Extensive experiments demonstrate that the proposed method outperforms state-of-the-art optimization-based HSI denoising methods in terms of effectiveness and robustness.