 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDTR: A Unified Deep Tensor Representation Framework for Multimedia Data Recovery
Jul 07, 2024



Recently, the transform-based tensor representation has attracted increasing attention in multimedia data (e.g., images and videos) recovery problems, which consists of two indispensable components, i.e., transform and characterization. Previously, the development of transform-based tensor representation mainly focuses on the transform aspect. Although several attempts consider using shallow matrix factorization (e.g., singular value decomposition and negative matrix factorization) to characterize the frontal slices of transformed tensor (termed as latent tensor), the faithful characterization aspect is underexplored. To address this issue, we propose a unified Deep Tensor Representation (termed as DTR) framework by synergistically combining the deep latent generative module and the deep transform module. Especially, the deep latent generative module can faithfully generate the latent tensor as compared with shallow matrix factorization. The new DTR framework not only allows us to better understand the classic shallow representations, but also leads us to explore new representation. To examine the representation ability of the proposed DTR, we consider the representative multi-dimensional data recovery task and suggest an unsupervised DTR-based multi-dimensional data recovery model. Extensive experiments demonstrate that DTR achieves superior performance compared to state-of-the-art methods in both quantitative and qualitative aspects, especially for fine details recovery.
Hyperspectral Denoising Using Unsupervised Disentangled Spatio-Spectral Deep Priors
Feb 24, 2021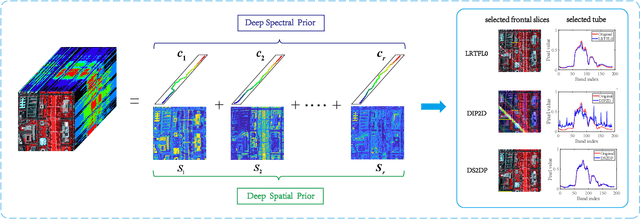
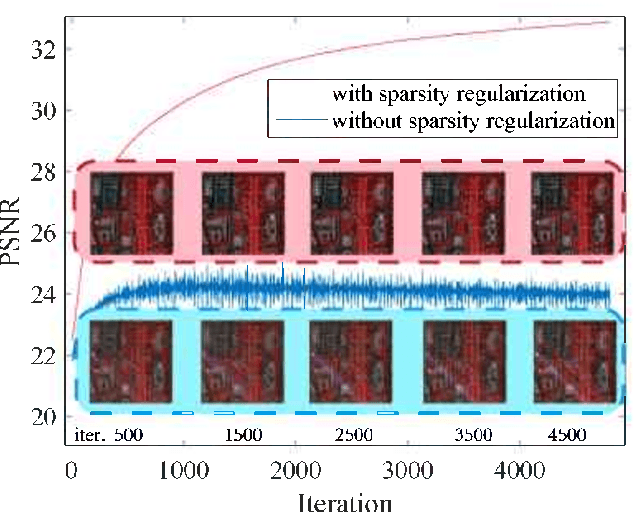

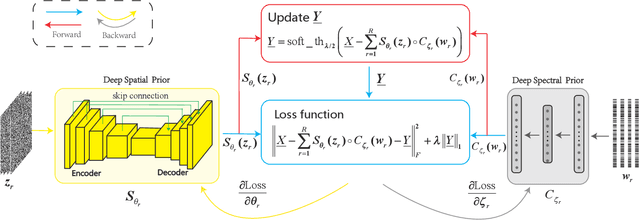
Image denoising is often empowered by accurate prior information. In recent years, data-driven neural network priors have shown promising performance for RGB natural image denoising. Compared to classic handcrafted priors (e.g., sparsity and total variation), the "deep priors" are learned using a large number of training samples -- which can accurately model the complex image generating process. However, data-driven priors are hard to acquire for hyperspectral images (HSIs) due to the lack of training data. A remedy is to use the so-called unsupervised deep image prior (DIP). Under the unsupervised DIP framework, it is hypothesized and empirically demonstrated that proper neural network structures are reasonable priors of certain types of images, and the network weights can be learned without training data. Nonetheless, the most effective unsupervised DIP structures were proposed for natural images instead of HSIs. The performance of unsupervised DIP-based HSI denoising is limited by a couple of serious challenges, namely, network structure design and network complexity. This work puts forth an unsupervised DIP framework that is based on the classic spatio-spectral decomposition of HSIs. Utilizing the so-called linear mixture model of HSIs, two types of unsupervised DIPs, i.e., U-Net-like network and fully-connected networks, are employed to model the abundance maps and endmembers contained in the HSIs, respectively. This way, empirically validated unsupervised DIP structures for natural images can be easily incorporated for HSI denoising. Besides, the decomposition also substantially reduces network complexity. An efficient alternating optimization algorithm is proposed to handle the formulated denoising problem. Semi-real and real data experiments are employed to showcase the effectiveness of the proposed approach.