 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnregistered Spectral Image Fusion: Unmixing, Adversarial Learning, and Recoverability
Mar 23, 2026This paper addresses the fusion of a pair of spatially unregistered hyperspectral image (HSI) and multispectral image (MSI) covering roughly overlapping regions. HSIs offer high spectral but low spatial resolution, while MSIs provide the opposite. The goal is to integrate their complementary information to enhance both HSI spatial resolution and MSI spectral resolution. While hyperspectral-multispectral fusion (HMF) has been widely studied, the unregistered setting remains challenging. Many existing methods focus solely on MSI super-resolution, leaving HSI unchanged. Supervised deep learning approaches were proposed for HSI super-resolution, but rely on accurate training data, which is often unavailable. Moreover, theoretical analyses largely address the co-registered case, leaving unregistered HMF poorly understood. In this work, an unsupervised framework is proposed to simultaneously super-resolve both MSI and HSI. The method integrates coupled spectral unmixing for MSI super-resolution with latent-space adversarial learning for HSI super-resolution. Theoretical guarantees on the recoverability of the super-resolution MSI and HSI are established under reasonable generative models -- providing, to our best knowledge, the first such insights for unregistered HMF. The approach is validated on semi-real and real HSI-MSI pairs across diverse conditions.
Interplay: Training Independent Simulators for Reference-Free Conversational Recommendation
Mar 19, 2026Training conversational recommender systems (CRS) requires extensive dialogue data, which is challenging to collect at scale. To address this, researchers have used simulated user-recommender conversations. Traditional simulation approaches often utilize a single large language model (LLM) that generates entire conversations with prior knowledge of the target items, leading to scripted and artificial dialogues. We propose a reference-free simulation framework that trains two independent LLMs, one as the user and one as the conversational recommender. These models interact in real-time without access to predetermined target items, but preference summaries and target attributes, enabling the recommender to genuinely infer user preferences through dialogue. This approach produces more realistic and diverse conversations that closely mirror authentic human-AI interactions. Our reference-free simulators match or exceed existing methods in quality, while offering a scalable solution for generating high-quality conversational recommendation data without constraining conversations to pre-defined target items. We conduct both quantitative and human evaluations to confirm the effectiveness of our reference-free approach.
Taming Score-Based Denoisers in ADMM: A Convergent Plug-and-Play Framework
Mar 10, 2026While score-based generative models have emerged as powerful priors for solving inverse problems, directly integrating them into optimization algorithms such as ADMM remains nontrivial. Two central challenges arise: i) the mismatch between the noisy data manifolds used to train the score functions and the geometry of ADMM iterates, especially due to the influence of dual variables, and ii) the lack of convergence understanding when ADMM is equipped with score-based denoisers. To address the manifold mismatch issue, we propose ADMM plug-and-play (ADMM-PnP) with the AC-DC denoiser, a new framework that embeds a three-stage denoiser into ADMM: (1) auto-correction (AC) via additive Gaussian noise, (2) directional correction (DC) using conditional Langevin dynamics, and (3) score-based denoising. In terms of convergence, we establish two results: first, under proper denoiser parameters, each ADMM iteration is a weakly nonexpansive operator, ensuring high-probability fixed-point $\textit{ball convergence}$ using a constant step size; second, under more relaxed conditions, the AC-DC denoiser is a bounded denoiser, which leads to convergence under an adaptive step size schedule. Experiments on a range of inverse problems demonstrate that our method consistently improves solution quality over a variety of baselines.
DuoGen: Towards General Purpose Interleaved Multimodal Generation
Feb 03, 2026Interleaved multimodal generation enables capabilities beyond unimodal generation models, such as step-by-step instructional guides, visual planning, and generating visual drafts for reasoning. However, the quality of existing interleaved generation models under general instructions remains limited by insufficient training data and base model capacity. We present DuoGen, a general-purpose interleaved generation framework that systematically addresses data curation, architecture design, and evaluation. On the data side, we build a large-scale, high-quality instruction-tuning dataset by combining multimodal conversations rewritten from curated raw websites, and diverse synthetic examples covering everyday scenarios. Architecturally, DuoGen leverages the strong visual understanding of a pretrained multimodal LLM and the visual generation capabilities of a diffusion transformer (DiT) pretrained on video generation, avoiding costly unimodal pretraining and enabling flexible base model selection. A two-stage decoupled strategy first instruction-tunes the MLLM, then aligns DiT with it using curated interleaved image-text sequences. Across public and newly proposed benchmarks, DuoGen outperforms prior open-source models in text quality, image fidelity, and image-context alignment, and also achieves state-of-the-art performance on text-to-image and image editing among unified generation models. Data and code will be released at https://research.nvidia.com/labs/dir/duogen/.
SemanticGen: Video Generation in Semantic Space
Dec 24, 2025

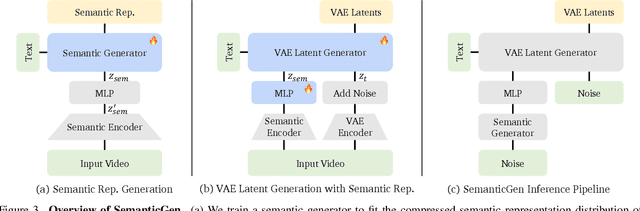

State-of-the-art video generative models typically learn the distribution of video latents in the VAE space and map them to pixels using a VAE decoder. While this approach can generate high-quality videos, it suffers from slow convergence and is computationally expensive when generating long videos. In this paper, we introduce SemanticGen, a novel solution to address these limitations by generating videos in the semantic space. Our main insight is that, due to the inherent redundancy in videos, the generation process should begin in a compact, high-level semantic space for global planning, followed by the addition of high-frequency details, rather than directly modeling a vast set of low-level video tokens using bi-directional attention. SemanticGen adopts a two-stage generation process. In the first stage, a diffusion model generates compact semantic video features, which define the global layout of the video. In the second stage, another diffusion model generates VAE latents conditioned on these semantic features to produce the final output. We observe that generation in the semantic space leads to faster convergence compared to the VAE latent space. Our method is also effective and computationally efficient when extended to long video generation. Extensive experiments demonstrate that SemanticGen produces high-quality videos and outperforms state-of-the-art approaches and strong baselines.
Rethinking Coupled Tensor Analysis for Hyperspectral Super-Resolution: Recoverable Modeling Under Endmember Variability
Dec 22, 2025This work revisits the hyperspectral super-resolution (HSR) problem, i.e., fusing a pair of spatially co-registered hyperspectral (HSI) and multispectral (MSI) images to recover a super-resolution image (SRI) that enhances the spatial resolution of the HSI. Coupled tensor decomposition (CTD)-based methods have gained traction in this domain, offering recoverability guarantees under various assumptions. Existing models such as canonical polyadic decomposition (CPD) and Tucker decomposition provide strong expressive power but lack physical interpretability. The block-term decomposition model with rank-$(L_r, L_r, 1)$ terms (the LL1 model) yields interpretable factors under the linear mixture model (LMM) of spectral images, but LMM assumptions are often violated in practice -- primarily due to nonlinear effects such as endmember variability (EV). To address this, we propose modeling spectral images using a more flexible block-term tensor decomposition with rank-$(L_r, M_r, N_r)$ terms (the LMN model). This modeling choice retains interpretability, subsumes CPD, Tucker, and LL1 as special cases, and robustly accounts for non-ideal effects such as EV, offering a balanced tradeoff between expressiveness and interpretability for HSR. Importantly, under the LMN model for HSI and MSI, recoverability of the SRI can still be established under proper conditions -- providing strong theoretical support. Extensive experiments on synthetic and real datasets further validate the effectiveness and robustness of the proposed method compared with existing CTD-based approaches.
SEE4D: Pose-Free 4D Generation via Auto-Regressive Video Inpainting
Oct 30, 2025Immersive applications call for synthesizing spatiotemporal 4D content from casual videos without costly 3D supervision. Existing video-to-4D methods typically rely on manually annotated camera poses, which are labor-intensive and brittle for in-the-wild footage. Recent warp-then-inpaint approaches mitigate the need for pose labels by warping input frames along a novel camera trajectory and using an inpainting model to fill missing regions, thereby depicting the 4D scene from diverse viewpoints. However, this trajectory-to-trajectory formulation often entangles camera motion with scene dynamics and complicates both modeling and inference. We introduce SEE4D, a pose-free, trajectory-to-camera framework that replaces explicit trajectory prediction with rendering to a bank of fixed virtual cameras, thereby separating camera control from scene modeling. A view-conditional video inpainting model is trained to learn a robust geometry prior by denoising realistically synthesized warped images and to inpaint occluded or missing regions across virtual viewpoints, eliminating the need for explicit 3D annotations. Building on this inpainting core, we design a spatiotemporal autoregressive inference pipeline that traverses virtual-camera splines and extends videos with overlapping windows, enabling coherent generation at bounded per-step complexity. We validate See4D on cross-view video generation and sparse reconstruction benchmarks. Across quantitative metrics and qualitative assessments, our method achieves superior generalization and improved performance relative to pose- or trajectory-conditioned baselines, advancing practical 4D world modeling from casual videos.
FieldFormer: Self-supervised Reconstruction of Physical Fields via Tensor Attention Prior
Jun 13, 2025Reconstructing physical field tensors from \textit{in situ} observations, such as radio maps and ocean sound speed fields, is crucial for enabling environment-aware decision making in various applications, e.g., wireless communications and underwater acoustics. Field data reconstruction is often challenging, due to the limited and noisy nature of the observations, necessitating the incorporation of prior information to aid the reconstruction process. Deep neural network-based data-driven structural constraints (e.g., ``deeply learned priors'') have showed promising performance. However, this family of techniques faces challenges such as model mismatches between training and testing phases. This work introduces FieldFormer, a self-supervised neural prior learned solely from the limited {\it in situ} observations without the need of offline training. Specifically, the proposed framework starts with modeling the fields of interest using the tensor Tucker model of a high multilinear rank, which ensures a universal approximation property for all fields. In the sequel, an attention mechanism is incorporated to learn the sparsity pattern that underlies the core tensor in order to reduce the solution space. In this way, a ``complexity-adaptive'' neural representation, grounded in the Tucker decomposition, is obtained that can flexibly represent various types of fields. A theoretical analysis is provided to support the recoverability of the proposed design. Moreover, extensive experiments, using various physical field tensors, demonstrate the superiority of the proposed approach compared to state-of-the-art baselines.
ReCamMaster: Camera-Controlled Generative Rendering from A Single Video
Mar 14, 2025Camera control has been actively studied in text or image conditioned video generation tasks. However, altering camera trajectories of a given video remains under-explored, despite its importance in the field of video creation. It is non-trivial due to the extra constraints of maintaining multiple-frame appearance and dynamic synchronization. To address this, we present ReCamMaster, a camera-controlled generative video re-rendering framework that reproduces the dynamic scene of an input video at novel camera trajectories. The core innovation lies in harnessing the generative capabilities of pre-trained text-to-video models through a simple yet powerful video conditioning mechanism -- its capability often overlooked in current research. To overcome the scarcity of qualified training data, we construct a comprehensive multi-camera synchronized video dataset using Unreal Engine 5, which is carefully curated to follow real-world filming characteristics, covering diverse scenes and camera movements. It helps the model generalize to in-the-wild videos. Lastly, we further improve the robustness to diverse inputs through a meticulously designed training strategy. Extensive experiments tell that our method substantially outperforms existing state-of-the-art approaches and strong baselines. Our method also finds promising applications in video stabilization, super-resolution, and outpainting. Project page: https://jianhongbai.github.io/ReCamMaster/
Domain-Factored Untrained Deep Prior for Spectrum Cartography
Jan 23, 2025Spectrum cartography (SC) focuses on estimating the radio power propagation map of multiple emitters across space and frequency using limited sensor measurements. Recent advances in SC have shown that leveraging learned deep generative models (DGMs) as structural constraints yields state-of-the-art performance. By harnessing the expressive power of neural networks, these structural "priors" capture intricate patterns in radio maps. However, training DGMs requires substantial data, which is not always available, and distribution shifts between training and testing data can further degrade performance. To address these challenges, this work proposes using untrained neural networks (UNNs) for SC. UNNs, commonly applied in vision tasks to represent complex data without training, encode structural information of data in neural architectures. In our approach, a custom-designed UNN represents radio maps under a spatio-spectral domain factorization model, leveraging physical characteristics to reduce sample complexity of SC. Experiments show that the method achieves performance comparable to learned DGM-based SC, without requiring training data.