 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace Projection Methods for Fast Spectral Embeddings of Evolving Graphs
Mar 19, 2026Several graph data mining, signal processing, and machine learning downstream tasks rely on information related to the eigenvectors of the associated adjacency or Laplacian matrix. Classical eigendecomposition methods are powerful when the matrix remains static but cannot be applied to problems where the matrix entries are updated or the number of rows and columns increases frequently. Such scenarios occur routinely in graph analytics when the graph is changing dynamically and either edges and/or nodes are being added and removed. This paper puts forth a new algorithmic framework to update the eigenvectors associated with the leading eigenvalues of an initial adjacency or Laplacian matrix as the graph evolves dynamically. The proposed algorithm is based on Rayleigh-Ritz projections, in which the original eigenvalue problem is projected onto a restricted subspace which ideally encapsulates the invariant subspace associated with the sought eigenvectors. Following ideas from eigenvector perturbation analysis, we present a new methodology to build the projection subspace. The proposed framework features lower computational and memory complexity with respect to competitive alternatives while empirical results show strong qualitative performance, both in terms of eigenvector approximation and accuracy of downstream learning tasks of central node identification and node clustering.
Learning From Crowdsourced Noisy Labels: A Signal Processing Perspective
Jul 09, 2024One of the primary catalysts fueling advances in artificial intelligence (AI) and machine learning (ML) is the availability of massive, curated datasets. A commonly used technique to curate such massive datasets is crowdsourcing, where data are dispatched to multiple annotators. The annotator-produced labels are then fused to serve downstream learning and inference tasks. This annotation process often creates noisy labels due to various reasons, such as the limited expertise, or unreliability of annotators, among others. Therefore, a core objective in crowdsourcing is to develop methods that effectively mitigate the negative impact of such label noise on learning tasks. This feature article introduces advances in learning from noisy crowdsourced labels. The focus is on key crowdsourcing models and their methodological treatments, from classical statistical models to recent deep learning-based approaches, emphasizing analytical insights and algorithmic developments. In particular, this article reviews the connections between signal processing (SP) theory and methods, such as identifiability of tensor and nonnegative matrix factorization, and novel, principled solutions of longstanding challenges in crowdsourcing -- showing how SP perspectives drive the advancements of this field. Furthermore, this article touches upon emerging topics that are critical for developing cutting-edge AI/ML systems, such as crowdsourcing in reinforcement learning with human feedback (RLHF) and direct preference optimization (DPO) that are key techniques for fine-tuning large language models (LLMs).
Detecting adversaries in Crowdsourcing
Oct 07, 2021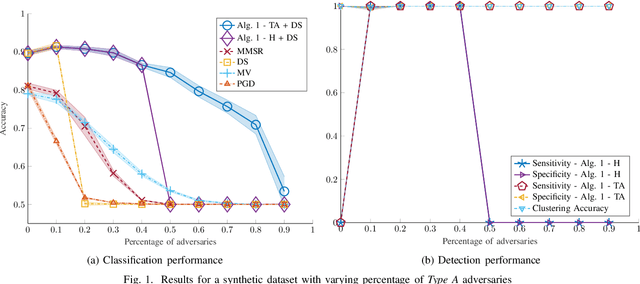
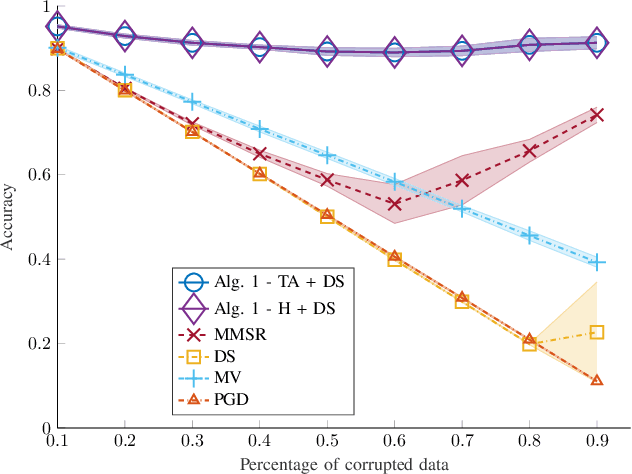
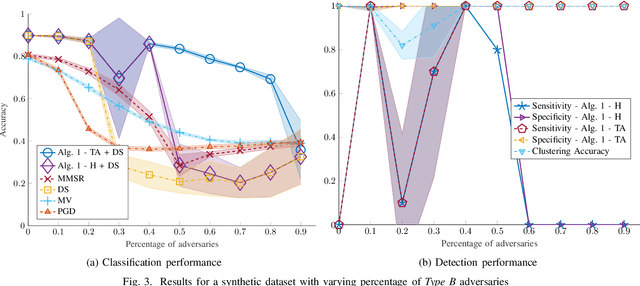
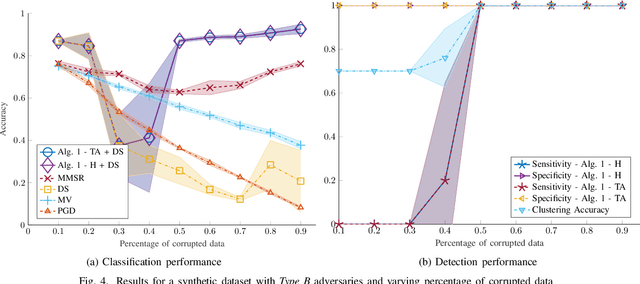
Despite its successes in various machine learning and data science tasks, crowdsourcing can be susceptible to attacks from dedicated adversaries. This work investigates the effects of adversaries on crowdsourced classification, under the popular Dawid and Skene model. The adversaries are allowed to deviate arbitrarily from the considered crowdsourcing model, and may potentially cooperate. To address this scenario, we develop an approach that leverages the structure of second-order moments of annotator responses, to identify large numbers of adversaries, and mitigate their impact on the crowdsourcing task. The potential of the proposed approach is empirically demonstrated on synthetic and real crowdsourcing datasets.
Bayesian Semi-supervised Crowdsourcing
Dec 20, 2020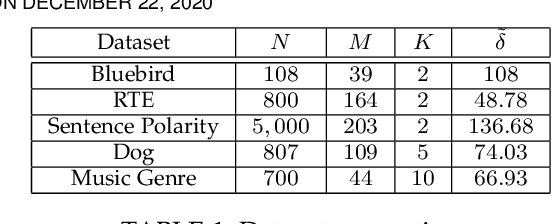
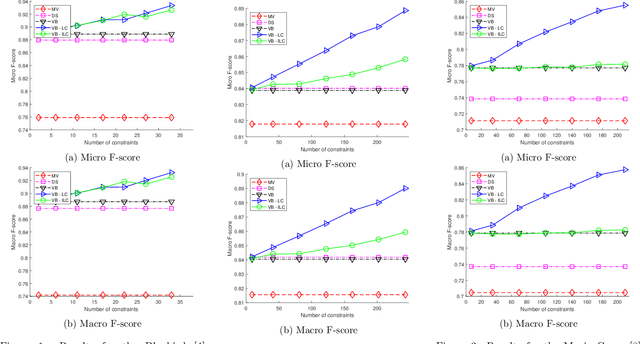
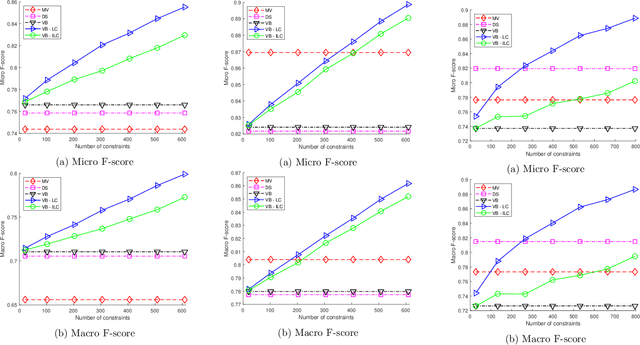
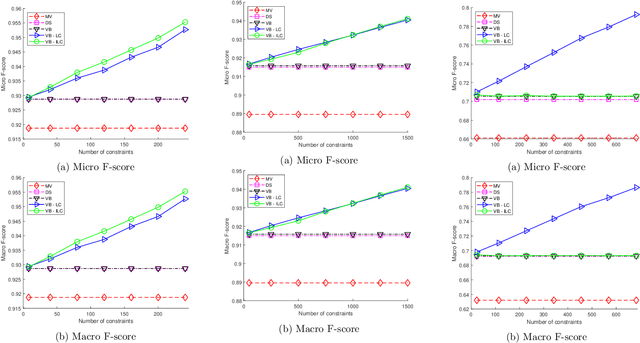
Crowdsourcing has emerged as a powerful paradigm for efficiently labeling large datasets and performing various learning tasks, by leveraging crowds of human annotators. When additional information is available about the data, semi-supervised crowdsourcing approaches that enhance the aggregation of labels from human annotators are well motivated. This work deals with semi-supervised crowdsourced classification, under two regimes of semi-supervision: a) label constraints, that provide ground-truth labels for a subset of data; and b) potentially easier to obtain instance-level constraints, that indicate relationships between pairs of data. Bayesian algorithms based on variational inference are developed for each regime, and their quantifiably improved performance, compared to unsupervised crowdsourcing, is analytically and empirically validated on several crowdsourcing datasets.
Unsupervised Ensemble Classification with Dependent Data
Jun 22, 2019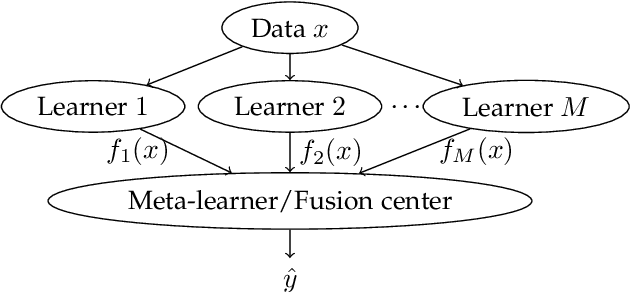

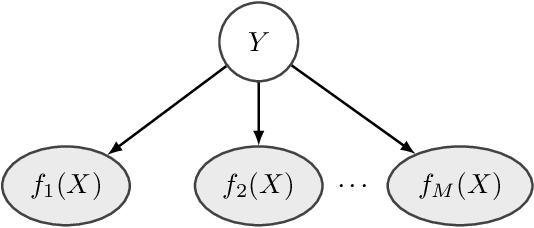
Ensemble learning, the machine learning paradigm where multiple algorithms are combined, has exhibited promising perfomance in a variety of tasks. The present work focuses on unsupervised ensemble classification. The term unsupervised refers to the ensemble combiner who has no knowledge of the ground-truth labels that each classifier has been trained on. While most prior works on unsupervised ensemble classification are designed for independent and identically distributed (i.i.d.) data, the present work introduces an unsupervised scheme for learning from ensembles of classifiers in the presence of data dependencies. Two types of data dependencies are considered: sequential data and networked data whose dependencies are captured by a graph. Moment matching and Expectation Maximization algorithms are developed for the aforementioned cases, and their performance is evaluated on synthetic and real datasets.
Blind Multiclass Ensemble Classification
Jul 20, 2018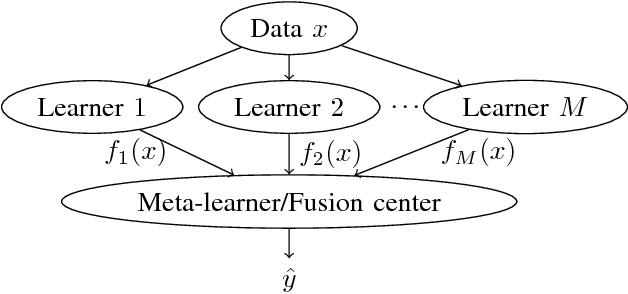
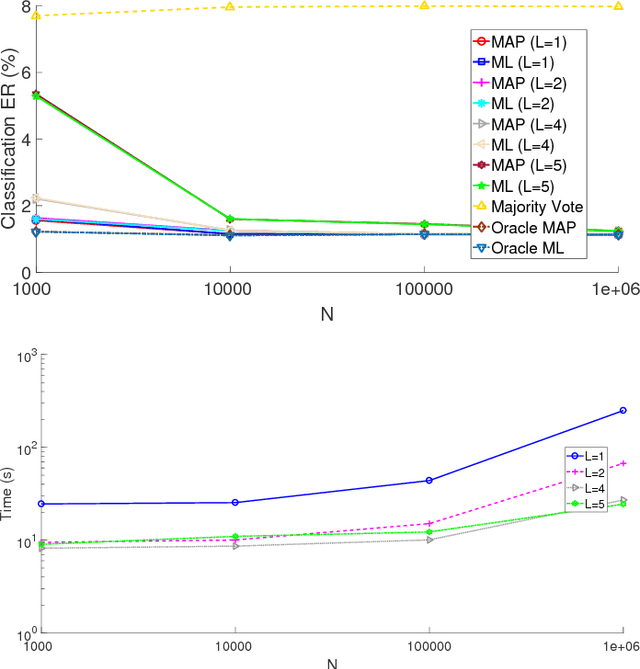
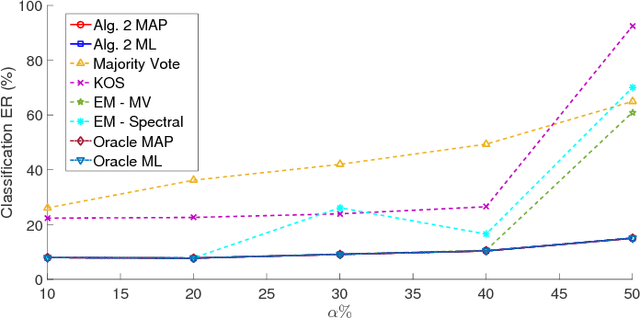

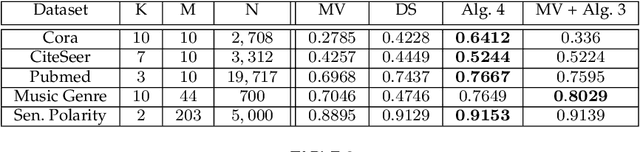
The rising interest in pattern recognition and data analytics has spurred the development of innovative machine learning algorithms and tools. However, as each algorithm has its strengths and limitations, one is motivated to judiciously fuse multiple algorithms in order to find the "best" performing one, for a given dataset. Ensemble learning aims at such high-performance meta-algorithm, by combining the outputs from multiple algorithms. The present work introduces a blind scheme for learning from ensembles of classifiers, using a moment matching method that leverages joint tensor and matrix factorization. Blind refers to the combiner who has no knowledge of the ground-truth labels that each classifier has been trained on. A rigorous performance analysis is derived and the proposed scheme is evaluated on synthetic and real datasets.
Nonlinear Dimensionality Reduction on Graphs
Mar 29, 2018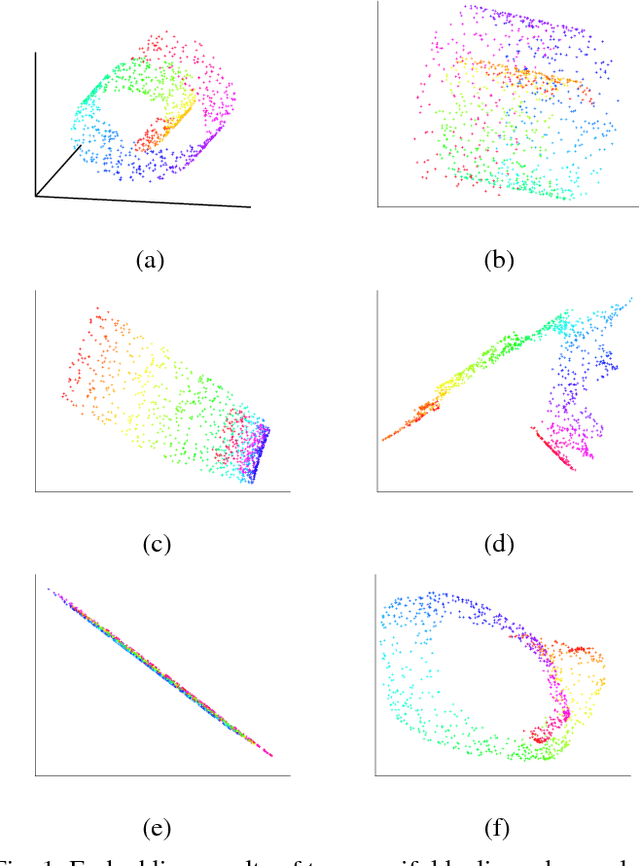
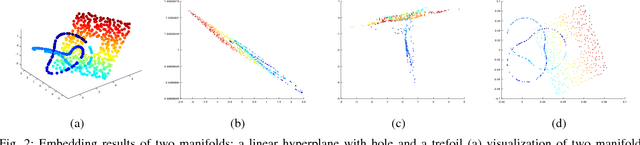
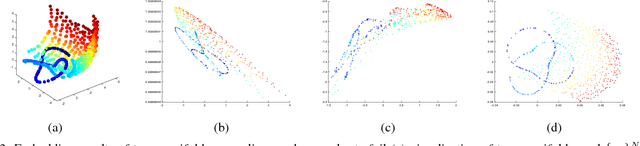
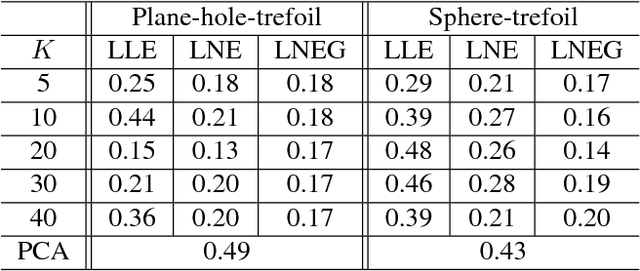
In this era of data deluge, many signal processing and machine learning tasks are faced with high-dimensional datasets, including images, videos, as well as time series generated from social, commercial and brain network interactions. Their efficient processing calls for dimensionality reduction techniques capable of properly compressing the data while preserving task-related characteristics, going beyond pairwise data correlations. The present paper puts forth a nonlinear dimensionality reduction framework that accounts for data lying on known graphs. The novel framework encompasses most of the existing dimensionality reduction methods, but it is also capable of capturing and preserving possibly nonlinear correlations that are ignored by linear methods. Furthermore, it can take into account information from multiple graphs. The proposed algorithms were tested on synthetic as well as real datasets to corroborate their effectiveness.
Sketched Subspace Clustering
Feb 07, 2018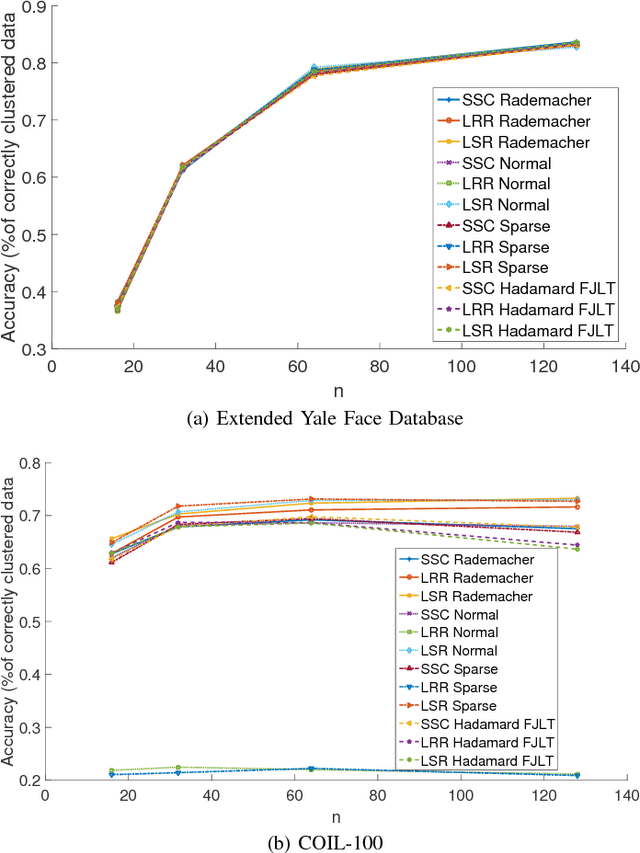
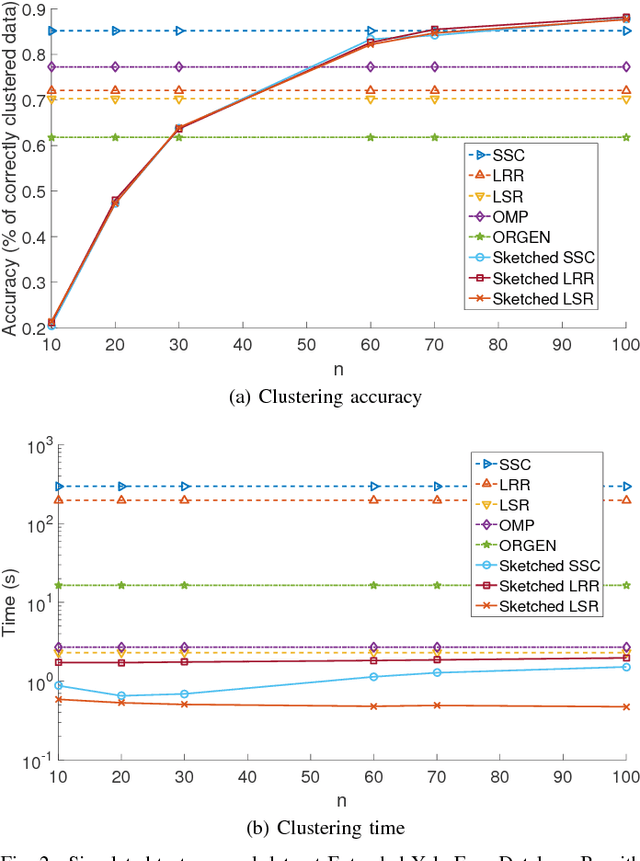
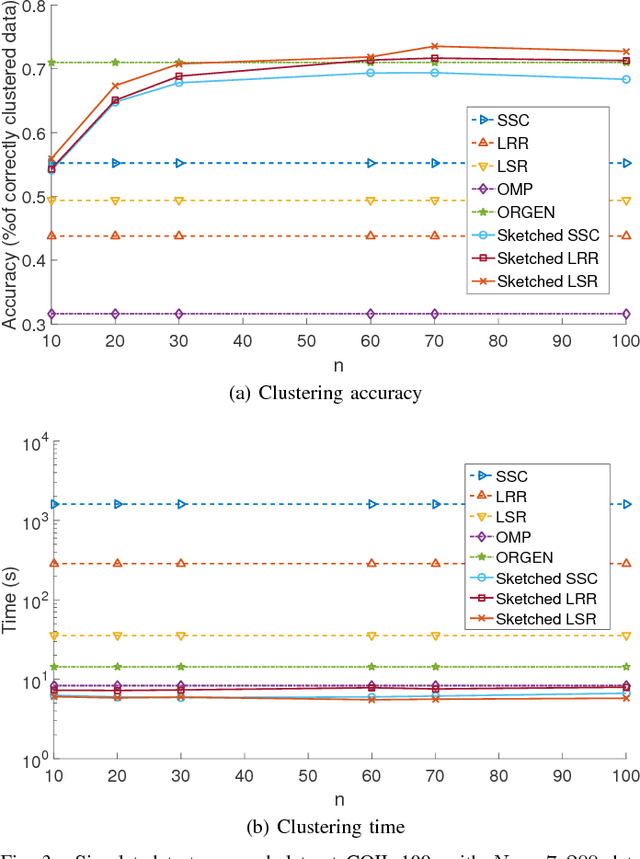

The immense amount of daily generated and communicated data presents unique challenges in their processing. Clustering, the grouping of data without the presence of ground-truth labels, is an important tool for drawing inferences from data. Subspace clustering (SC) is a relatively recent method that is able to successfully classify nonlinearly separable data in a multitude of settings. In spite of their high clustering accuracy, SC methods incur prohibitively high computational complexity when processing large volumes of high-dimensional data. Inspired by random sketching approaches for dimensionality reduction, the present paper introduces a randomized scheme for SC, termed Sketch-SC, tailored for large volumes of high-dimensional data. Sketch-SC accelerates the computationally heavy parts of state-of-the-art SC approaches by compressing the data matrix across both dimensions using random projections, thus enabling fast and accurate large-scale SC. Performance analysis as well as extensive numerical tests on real data corroborate the potential of Sketch-SC and its competitive performance relative to state-of-the-art scalable SC approaches.
Large-scale subspace clustering using sketching and validation
Oct 06, 2015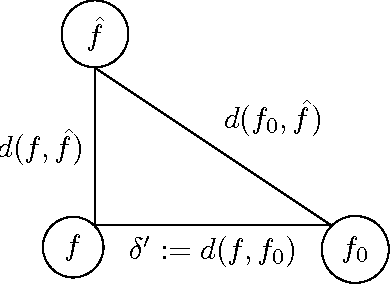
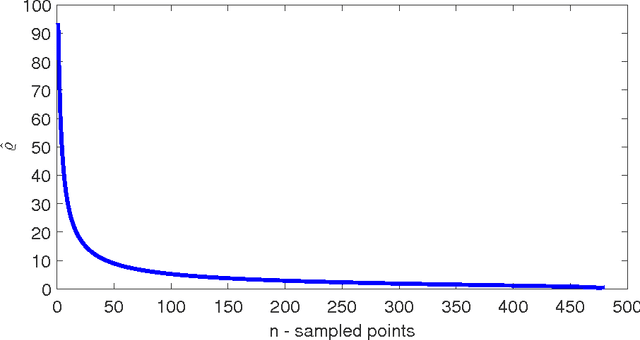
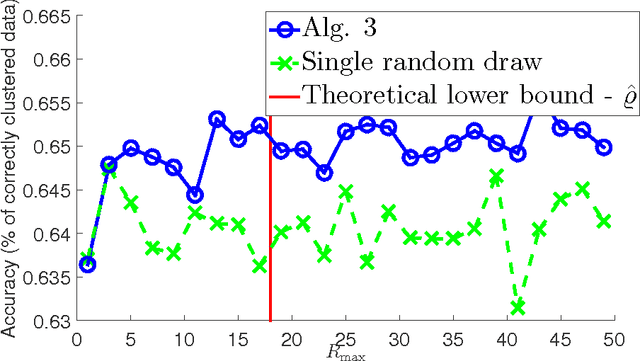
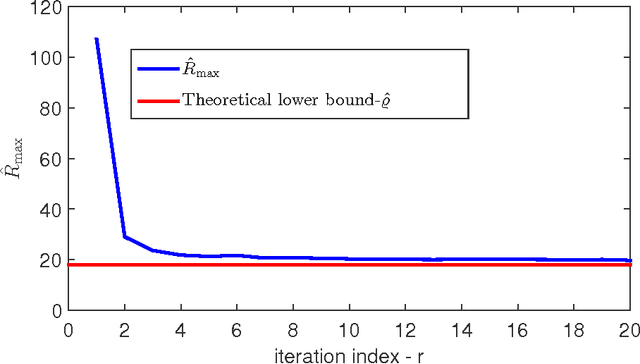
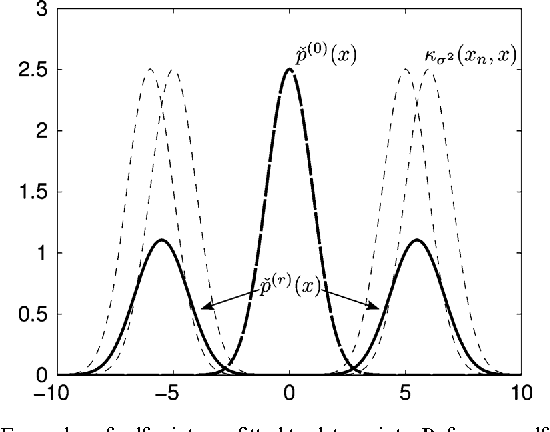
The nowadays massive amounts of generated and communicated data present major challenges in their processing. While capable of successfully classifying nonlinearly separable objects in various settings, subspace clustering (SC) methods incur prohibitively high computational complexity when processing large-scale data. Inspired by the random sampling and consensus (RANSAC) approach to robust regression, the present paper introduces a randomized scheme for SC, termed sketching and validation (SkeVa-)SC, tailored for large-scale data. At the heart of SkeVa-SC lies a randomized scheme for approximating the underlying probability density function of the observed data by kernel smoothing arguments. Sparsity in data representations is also exploited to reduce the computational burden of SC, while achieving high clustering accuracy. Performance analysis as well as extensive numerical tests on synthetic and real data corroborate the potential of SkeVa-SC and its competitive performance relative to state-of-the-art scalable SC approaches. Keywords: Subspace clustering, big data, kernel smoothing, randomization, sketching, validation, sparsity.
Sketch and Validate for Big Data Clustering
Jan 22, 2015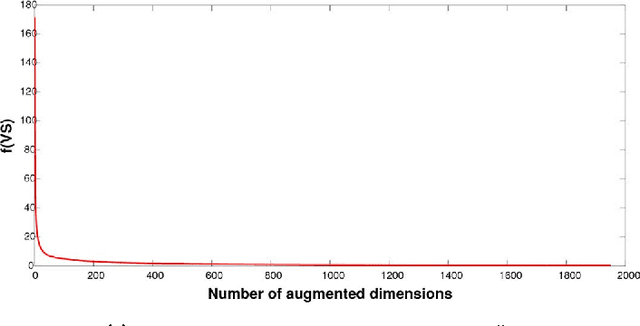
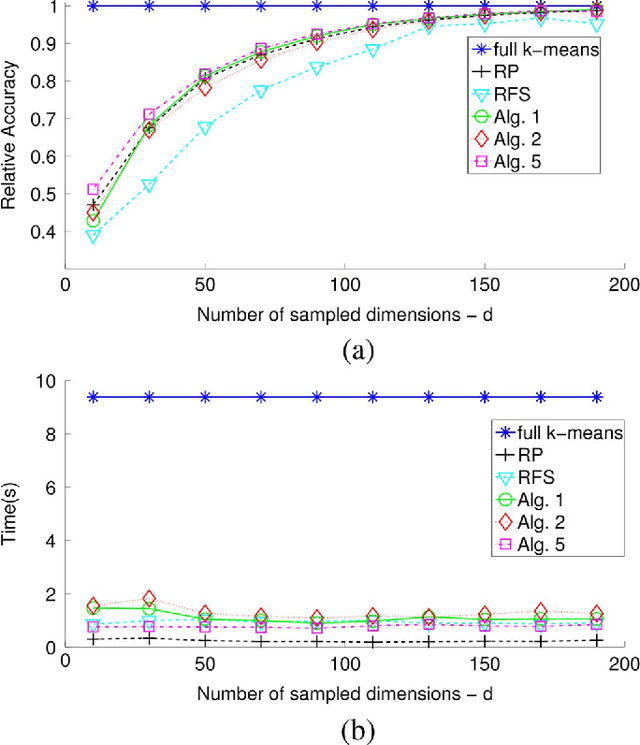
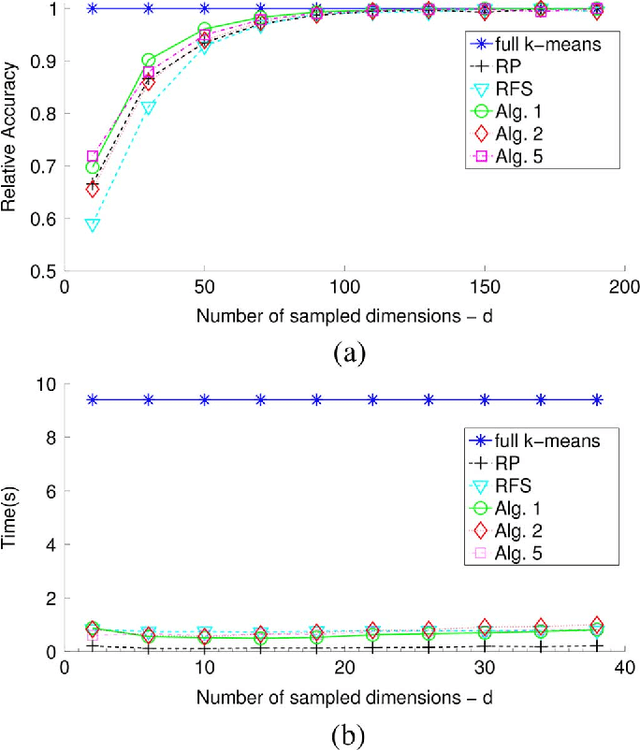
In response to the need for learning tools tuned to big data analytics, the present paper introduces a framework for efficient clustering of huge sets of (possibly high-dimensional) data. Building on random sampling and consensus (RANSAC) ideas pursued earlier in a different (computer vision) context for robust regression, a suite of novel dimensionality and set-reduction algorithms is developed. The advocated sketch-and-validate (SkeVa) family includes two algorithms that rely on K-means clustering per iteration on reduced number of dimensions and/or feature vectors: The first operates in a batch fashion, while the second sequential one offers computational efficiency and suitability with streaming modes of operation. For clustering even nonlinearly separable vectors, the SkeVa family offers also a member based on user-selected kernel functions. Further trading off performance for reduced complexity, a fourth member of the SkeVa family is based on a divergence criterion for selecting proper minimal subsets of feature variables and vectors, thus bypassing the need for K-means clustering per iteration. Extensive numerical tests on synthetic and real data sets highlight the potential of the proposed algorithms, and demonstrate their competitive performance relative to state-of-the-art random projection alternatives.