 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Semi-supervised Crowdsourcing
Paper and Code
Dec 20, 2020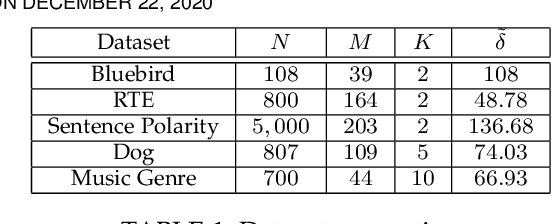
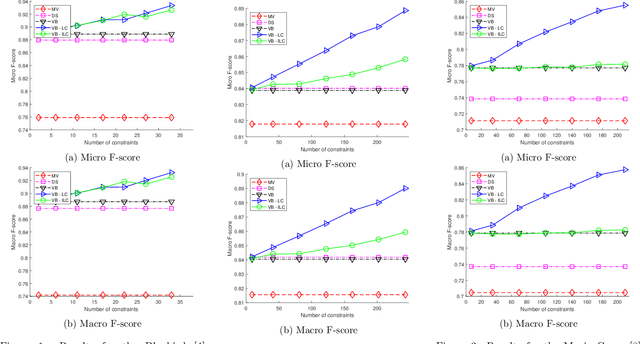
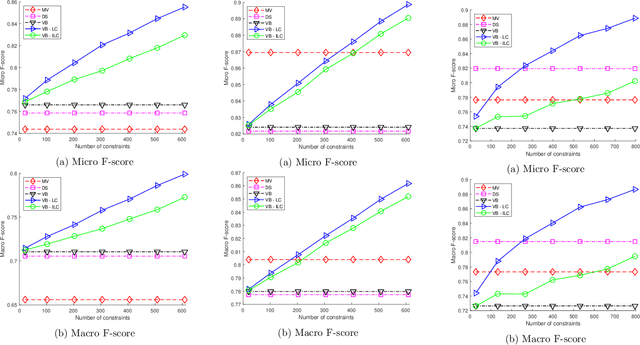
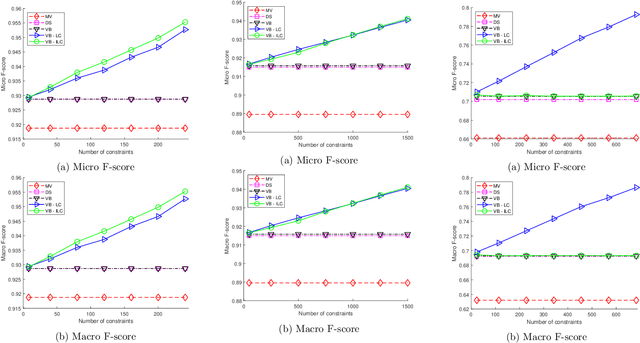
Crowdsourcing has emerged as a powerful paradigm for efficiently labeling large datasets and performing various learning tasks, by leveraging crowds of human annotators. When additional information is available about the data, semi-supervised crowdsourcing approaches that enhance the aggregation of labels from human annotators are well motivated. This work deals with semi-supervised crowdsourced classification, under two regimes of semi-supervision: a) label constraints, that provide ground-truth labels for a subset of data; and b) potentially easier to obtain instance-level constraints, that indicate relationships between pairs of data. Bayesian algorithms based on variational inference are developed for each regime, and their quantifiably improved performance, compared to unsupervised crowdsourcing, is analytically and empirically validated on several crowdsourcing datasets.