 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANCRe: Adaptive Neural Connection Reassignment for Efficient Depth Scaling
Feb 09, 2026Scaling network depth has been a central driver behind the success of modern foundation models, yet recent investigations suggest that deep layers are often underutilized. This paper revisits the default mechanism for deepening neural networks, namely residual connections, from an optimization perspective. Rigorous analysis proves that the layout of residual connections can fundamentally shape convergence behavior, and even induces an exponential gap in convergence rates. Prompted by this insight, we introduce adaptive neural connection reassignment (ANCRe), a principled and lightweight framework that parameterizes and learns residual connectivities from the data. ANCRe adaptively reassigns residual connections with negligible computational and memory overhead ($<1\%$), while enabling more effective utilization of network depth. Extensive numerical tests across pre-training of large language models, diffusion models, and deep ResNets demonstrate consistently accelerated convergence, boosted performance, and enhanced depth efficiency over conventional residual connections.
Topology Identification and Inference over Graphs
Dec 11, 2025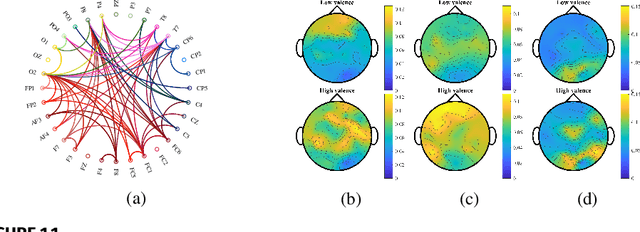
Topology identification and inference of processes evolving over graphs arise in timely applications involving brain, transportation, financial, power, as well as social and information networks. This chapter provides an overview of graph topology identification and statistical inference methods for multidimensional relational data. Approaches for undirected links connecting graph nodes are outlined, going all the way from correlation metrics to covariance selection, and revealing ties with smooth signal priors. To account for directional (possibly causal) relations among nodal variables and address the limitations of linear time-invariant models in handling dynamic as well as nonlinear dependencies, a principled framework is surveyed to capture these complexities through judiciously selected kernels from a prescribed dictionary. Generalizations are also described via structural equations and vector autoregressions that can exploit attributes such as low rank, sparsity, acyclicity, and smoothness to model dynamic processes over possibly time-evolving topologies. It is argued that this approach supports both batch and online learning algorithms with convergence rate guarantees, is amenable to tensor (that is, multi-way array) formulations as well as decompositions that are well-suited for multidimensional network data, and can seamlessly leverage high-order statistical information.
Deploying AI for Signal Processing education: Selected challenges and intriguing opportunities
Sep 10, 2025Powerful artificial intelligence (AI) tools that have emerged in recent years -- including large language models, automated coding assistants, and advanced image and speech generation technologies -- are the result of monumental human achievements. These breakthroughs reflect mastery across multiple technical disciplines and the resolution of significant technological challenges. However, some of the most profound challenges may still lie ahead. These challenges are not purely technical but pertain to the fair and responsible use of AI in ways that genuinely improve the global human condition. This article explores one promising application aligned with that vision: the use of AI tools to facilitate and enhance education, with a specific focus on signal processing (SP). It presents two interrelated perspectives: identifying and addressing technical limitations, and applying AI tools in practice to improve educational experiences. Primers are provided on several core technical issues that arise when using AI in educational settings, including how to ensure fairness and inclusivity, handle hallucinated outputs, and achieve efficient use of resources. These and other considerations -- such as transparency, explainability, and trustworthiness -- are illustrated through the development of an immersive, structured, and reliable "smart textbook." The article serves as a resource for researchers and educators seeking to advance AI's role in engineering education.
RefLoRA: Refactored Low-Rank Adaptation for Efficient Fine-Tuning of Large Models
May 24, 2025Low-Rank Adaptation (LoRA) lowers the computational and memory overhead of fine-tuning large models by updating a low-dimensional subspace of the pre-trained weight matrix. Albeit efficient, LoRA exhibits suboptimal convergence and noticeable performance degradation, due to inconsistent and imbalanced weight updates induced by its nonunique low-rank factorizations. To overcome these limitations, this article identifies the optimal low-rank factorization per step that minimizes an upper bound on the loss. The resultant refactored low-rank adaptation (RefLoRA) method promotes a flatter loss landscape, along with consistent and balanced weight updates, thus speeding up stable convergence. Extensive experiments evaluate RefLoRA on natural language understanding, and commonsense reasoning tasks with popular large language models including DeBERTaV3, LLaMA-7B, LLaMA2-7B and LLaMA3-8B. The numerical tests corroborate that RefLoRA converges faster, outperforms various benchmarks, and enjoys negligible computational overhead compared to state-of-the-art LoRA variants.
Preconditioned Sharpness-Aware Minimization: Unifying Analysis and a Novel Learning Algorithm
Jan 11, 2025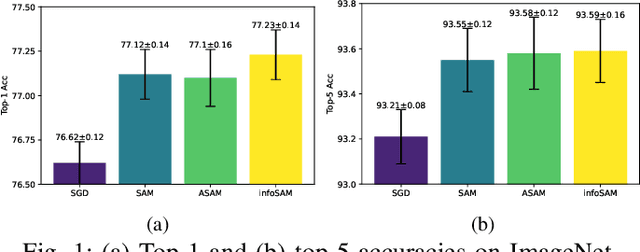
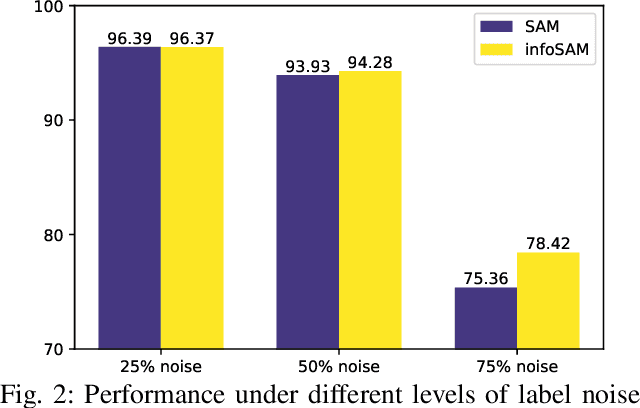
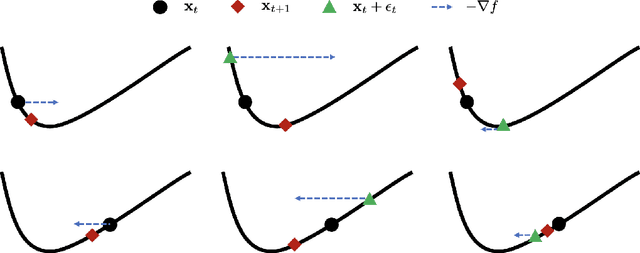
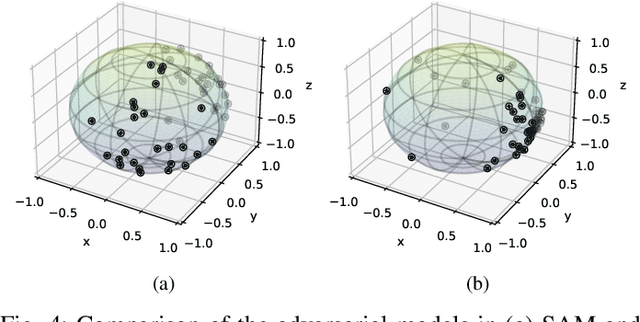
Targeting solutions over `flat' regions of the loss landscape, sharpness-aware minimization (SAM) has emerged as a powerful tool to improve generalizability of deep neural network based learning. While several SAM variants have been developed to this end, a unifying approach that also guides principled algorithm design has been elusive. This contribution leverages preconditioning (pre) to unify SAM variants and provide not only unifying convergence analysis, but also valuable insights. Building upon preSAM, a novel algorithm termed infoSAM is introduced to address the so-called adversarial model degradation issue in SAM by adjusting gradients depending on noise estimates. Extensive numerical tests demonstrate the superiority of infoSAM across various benchmarks.
Online scalable Gaussian processes with conformal prediction for guaranteed coverage
Oct 07, 2024


The Gaussian process (GP) is a Bayesian nonparametric paradigm that is widely adopted for uncertainty quantification (UQ) in a number of safety-critical applications, including robotics, healthcare, as well as surveillance. The consistency of the resulting uncertainty values however, hinges on the premise that the learning function conforms to the properties specified by the GP model, such as smoothness, periodicity and more, which may not be satisfied in practice, especially with data arriving on the fly. To combat against such model mis-specification, we propose to wed the GP with the prevailing conformal prediction (CP), a distribution-free post-processing framework that produces it prediction sets with a provably valid coverage under the sole assumption of data exchangeability. However, this assumption is usually violated in the online setting, where a prediction set is sought before revealing the true label. To ensure long-term coverage guarantee, we will adaptively set the key threshold parameter based on the feedback whether the true label falls inside the prediction set. Numerical results demonstrate the merits of the online GP-CP approach relative to existing alternatives in the long-term coverage performance.
Learning From Crowdsourced Noisy Labels: A Signal Processing Perspective
Jul 09, 2024One of the primary catalysts fueling advances in artificial intelligence (AI) and machine learning (ML) is the availability of massive, curated datasets. A commonly used technique to curate such massive datasets is crowdsourcing, where data are dispatched to multiple annotators. The annotator-produced labels are then fused to serve downstream learning and inference tasks. This annotation process often creates noisy labels due to various reasons, such as the limited expertise, or unreliability of annotators, among others. Therefore, a core objective in crowdsourcing is to develop methods that effectively mitigate the negative impact of such label noise on learning tasks. This feature article introduces advances in learning from noisy crowdsourced labels. The focus is on key crowdsourcing models and their methodological treatments, from classical statistical models to recent deep learning-based approaches, emphasizing analytical insights and algorithmic developments. In particular, this article reviews the connections between signal processing (SP) theory and methods, such as identifiability of tensor and nonnegative matrix factorization, and novel, principled solutions of longstanding challenges in crowdsourcing -- showing how SP perspectives drive the advancements of this field. Furthermore, this article touches upon emerging topics that are critical for developing cutting-edge AI/ML systems, such as crowdsourcing in reinforcement learning with human feedback (RLHF) and direct preference optimization (DPO) that are key techniques for fine-tuning large language models (LLMs).
Meta-Learning with Versatile Loss Geometries for Fast Adaptation Using Mirror Descent
Dec 20, 2023
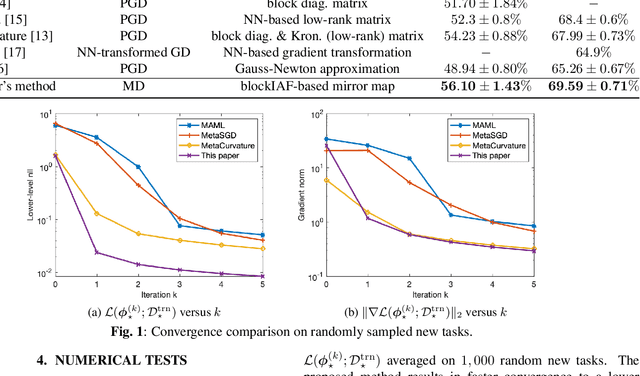
Utilizing task-invariant prior knowledge extracted from related tasks, meta-learning is a principled framework that empowers learning a new task especially when data records are limited. A fundamental challenge in meta-learning is how to quickly "adapt" the extracted prior in order to train a task-specific model within a few optimization steps. Existing approaches deal with this challenge using a preconditioner that enhances convergence of the per-task training process. Though effective in representing locally a quadratic training loss, these simple linear preconditioners can hardly capture complex loss geometries. The present contribution addresses this limitation by learning a nonlinear mirror map, which induces a versatile distance metric to enable capturing and optimizing a wide range of loss geometries, hence facilitating the per-task training. Numerical tests on few-shot learning datasets demonstrate the superior expressiveness and convergence of the advocated approach.
Contractive error feedback for gradient compression
Dec 13, 2023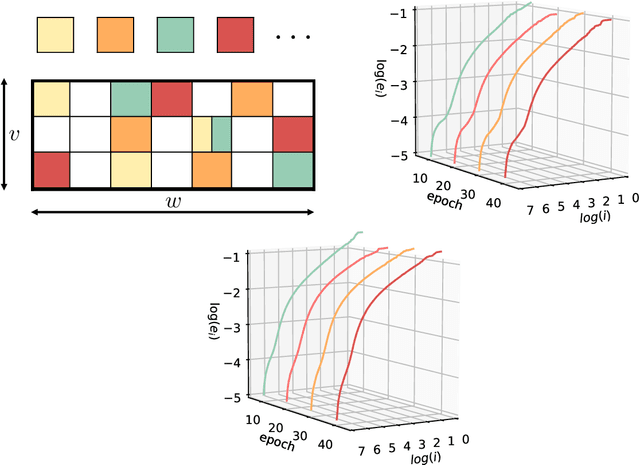
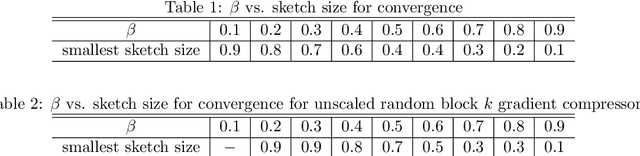
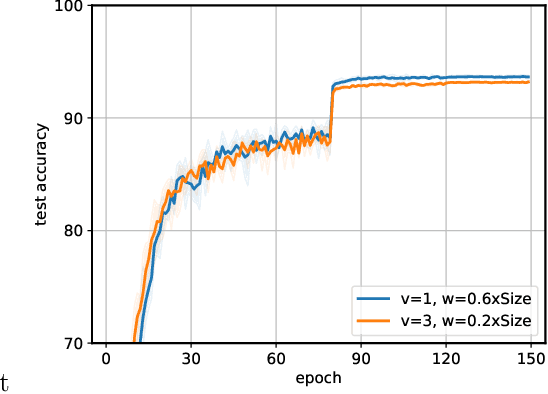
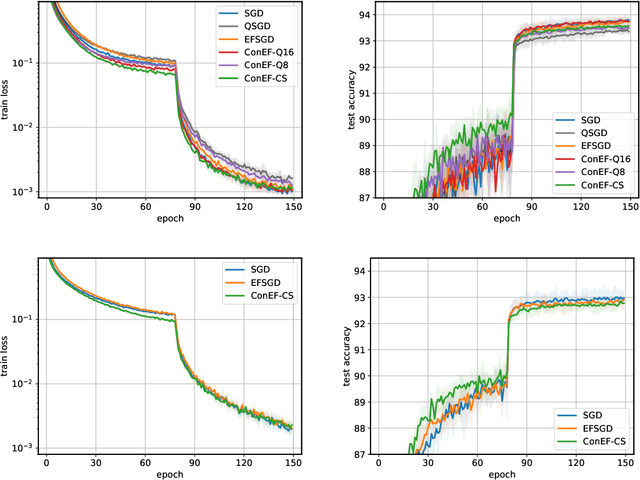
On-device memory concerns in distributed deep learning have become severe due to (i) the growth of model size in multi-GPU training, and (ii) the wide adoption of deep neural networks for federated learning on IoT devices which have limited storage. In such settings, communication efficient optimization methods are attractive alternatives, however they still struggle with memory issues. To tackle these challenges, we propose an communication efficient method called contractive error feedback (ConEF). As opposed to SGD with error-feedback (EFSGD) that inefficiently manages memory, ConEF obtains the sweet spot of convergence and memory usage, and achieves communication efficiency by leveraging biased and all-reducable gradient compression. We empirically validate ConEF on various learning tasks that include image classification, language modeling, and machine translation and observe that ConEF saves 80\% - 90\% of the extra memory in EFSGD with almost no loss on test performance, while also achieving 1.3x - 5x speedup of SGD. Through our work, we also demonstrate the feasibility and convergence of ConEF to clear up the theoretical barrier of integrating ConEF to popular memory efficient frameworks such as ZeRO-3.
3D Reconstruction in Noisy Agricultural Environments: A Bayesian Optimization Perspective for View Planning
Sep 29, 20233D reconstruction is a fundamental task in robotics that gained attention due to its major impact in a wide variety of practical settings, including agriculture, underwater, and urban environments. An important approach for this task, known as view planning, is to judiciously place a number of cameras in positions that maximize the visual information improving the resulting 3D reconstruction. Circumventing the need for a large number of arbitrary images, geometric criteria can be applied to select fewer yet more informative images to markedly improve the 3D reconstruction performance. Nonetheless, incorporating the noise of the environment that exists in various real-world scenarios into these criteria may be challenging, particularly when prior information about the noise is not provided. To that end, this work advocates a novel geometric function that accounts for the existing noise, relying solely on a relatively small number of noise realizations without requiring its closed-form expression. With no analytic expression of the geometric function, this work puts forth a Bayesian optimization algorithm for accurate 3D reconstruction in the presence of noise. Numerical tests on noisy agricultural environments showcase the impressive merits of the proposed approach for 3D reconstruction with even a small number of available cameras.