 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroth-Order Optimization at the Edge of Stability
Apr 16, 2026Zeroth-order (ZO) methods are widely used when gradients are unavailable or prohibitively expensive, including black-box learning and memory-efficient fine-tuning of large models, yet their optimization dynamics in deep learning remain underexplored. In this work, we provide an explicit step size condition that exactly captures the (mean-square) linear stability of a family of ZO methods based on the standard two-point estimator. Our characterization reveals a sharp contrast with first-order (FO) methods: whereas FO stability is governed solely by the largest Hessian eigenvalue, mean-square stability of ZO methods depends on the entire Hessian spectrum. Since computing the full Hessian spectrum is infeasible in practical neural network training, we further derive tractable stability bounds that depend only on the largest eigenvalue and the Hessian trace. Empirically, we find that full-batch ZO methods operate at the edge of stability: ZO-GD, ZO-GDM, and ZO-Adam consistently stabilize near the predicted stability boundary across a range of deep learning training problems. Our results highlight an implicit regularization effect specific to ZO methods, where large step sizes primarily regularize the Hessian trace, whereas in FO methods they regularize the top eigenvalue.
Adaptive Test-Time Compute Allocation for Reasoning LLMs via Constrained Policy Optimization
Apr 16, 2026Test-time compute scaling, the practice of spending extra computation during inference via repeated sampling, search, or extended reasoning, has become a powerful lever for improving large language model performance. Yet deploying these techniques under finite inference budgets requires a decision that current systems largely ignore: which inputs deserve more compute, and which can be answered cheaply? We formalize this as a constrained optimization problem (maximize expected accuracy subject to an average compute budget) and solve it with a two-stage Solve-then-Learn pipeline. In the solve stage, Lagrangian relaxation decomposes the global constraint into per-instance sub-problems, each admitting a closed-form oracle action that optimally prices accuracy against cost. We prove that the induced cost is monotone in the dual variable, enabling exact budget targeting via binary search. In the learn stage, a lightweight classifier is trained to predict oracle actions from cheap input features, amortizing the allocation rule for real-time deployment. We establish that the task-level regret of the learned policy is bounded by its imitation error times the worst-case per-instance gap, yielding a clean reduction from constrained inference to supervised classification. Experiments on MATH and GSM8K with three LLMs (DeepSeek-V3, GPT-4o-mini, Qwen2.5-7B) show that our method consistently outperforms uniform and heuristic allocation baselines, achieving up to 12.8% relative accuracy improvement on MATH under matched budget constraints, while closely tracking the Lagrangian oracle upper bound with over 91% imitation accuracy.
Binomial Gradient-Based Meta-Learning for Enhanced Meta-Gradient Estimation
Apr 14, 2026Meta-learning offers a principled framework leveraging \emph{task-invariant} priors from related tasks, with which \emph{task-specific} models can be fine-tuned on downstream tasks, even with limited data records. Gradient-based meta-learning (GBML) relies on gradient descent (GD) to adapt the prior to a new task. Albeit effective, these methods incur high computational overhead that scales linearly with the number of GD steps. To enhance efficiency and scalability, existing methods approximate the gradient of prior parameters (meta-gradient) via truncated backpropagation, yet suffer large approximation errors. Targeting accurate approximation, this work puts forth binomial GBML (BinomGBML), which relies on a truncated binomial expansion for meta-gradient estimation. This novel expansion endows more information in the meta-gradient estimation via efficient parallel computation. As a running paradigm applied to model-agnostic meta-learning (MAML), the resultant BinomMAML provably enjoys error bounds that not only improve upon existing approaches, but also decay super-exponentially under mild conditions. Numerical tests corroborate the theoretical analysis and showcase boosted performance with slightly increased computational overhead.
Scalable Variational Bayesian Fine-Tuning of LLMs via Orthogonalized Low-Rank Adapters
Apr 03, 2026When deploying large language models (LLMs) to safety-critical applications, uncertainty quantification (UQ) is of utmost importance to self-assess the reliability of the LLM-based decisions. However, such decisions typically suffer from overconfidence, particularly after parameter-efficient fine-tuning (PEFT) for downstream domain-specific tasks with limited data. Existing methods to alleviate this issue either rely on Laplace approximation based post-hoc framework, which may yield suboptimal calibration depending on the training trajectory, or variational Bayesian training that requires multiple complete forward passes through the entire LLM backbone at inference time for Monte Carlo estimation, posing scalability challenges for deployment. To address these limitations, we build on the Bayesian last layer (BLL) model, where the LLM-based deterministic feature extractor is followed by random last layer parameters for uncertainty reasoning. Since existing low-rank adapters (LoRA) for PEFT have limited expressiveness due to rank collapse, we address this with Polar-decomposed Low-rank Adapter Representation (PoLAR), an orthogonalized parameterization paired with Riemannian optimization to enable more stable and expressive adaptation. Building on this PoLAR-BLL model, we leverage the variational (V) inference framework to put forth a scalable Bayesian fine-tuning approach which jointly seeks the PoLAR parameters and approximate posterior of the last layer parameters via alternating optimization. The resulting PoLAR-VBLL is a flexible framework that nicely integrates architecture-enhanced optimization with scalable Bayesian inference to endow LLMs with well-calibrated UQ. Our empirical results verify the effectiveness of PoLAR-VBLL in terms of generalization and uncertainty estimation on both in-distribution and out-of-distribution data for various common-sense reasoning tasks.
ANCRe: Adaptive Neural Connection Reassignment for Efficient Depth Scaling
Feb 09, 2026Scaling network depth has been a central driver behind the success of modern foundation models, yet recent investigations suggest that deep layers are often underutilized. This paper revisits the default mechanism for deepening neural networks, namely residual connections, from an optimization perspective. Rigorous analysis proves that the layout of residual connections can fundamentally shape convergence behavior, and even induces an exponential gap in convergence rates. Prompted by this insight, we introduce adaptive neural connection reassignment (ANCRe), a principled and lightweight framework that parameterizes and learns residual connectivities from the data. ANCRe adaptively reassigns residual connections with negligible computational and memory overhead ($<1\%$), while enabling more effective utilization of network depth. Extensive numerical tests across pre-training of large language models, diffusion models, and deep ResNets demonstrate consistently accelerated convergence, boosted performance, and enhanced depth efficiency over conventional residual connections.
SALAAD: Sparse And Low-Rank Adaptation via ADMM
Feb 01, 2026Modern large language models are increasingly deployed under compute and memory constraints, making flexible control of model capacity a central challenge. While sparse and low-rank structures naturally trade off capacity and performance, existing approaches often rely on heuristic designs that ignore layer and matrix heterogeneity or require model-specific architectural modifications. We propose SALAAD, a plug-and-play framework applicable to different model architectures that induces sparse and low-rank structures during training. By formulating structured weight learning under an augmented Lagrangian framework and introducing an adaptive controller that dynamically balances the training loss and structural constraints, SALAAD preserves the stability of standard training dynamics while enabling explicit control over the evolution of effective model capacity during training. Experiments across model scales show that SALAAD substantially reduces memory consumption during deployment while achieving performance comparable to ad-hoc methods. Moreover, a single training run yields a continuous spectrum of model capacities, enabling smooth and elastic deployment across diverse memory budgets without the need for retraining.
Zeroth-Order Optimization Finds Flat Minima
Jun 05, 2025Zeroth-order methods are extensively used in machine learning applications where gradients are infeasible or expensive to compute, such as black-box attacks, reinforcement learning, and language model fine-tuning. Existing optimization theory focuses on convergence to an arbitrary stationary point, but less is known on the implicit regularization that provides a fine-grained characterization on which particular solutions are finally reached. We show that zeroth-order optimization with the standard two-point estimator favors solutions with small trace of Hessian, which is widely used in previous work to distinguish between sharp and flat minima. We further provide convergence rates of zeroth-order optimization to approximate flat minima for convex and sufficiently smooth functions, where flat minima are defined as the minimizers that achieve the smallest trace of Hessian among all optimal solutions. Experiments on binary classification tasks with convex losses and language model fine-tuning support our theoretical findings.
RefLoRA: Refactored Low-Rank Adaptation for Efficient Fine-Tuning of Large Models
May 24, 2025Low-Rank Adaptation (LoRA) lowers the computational and memory overhead of fine-tuning large models by updating a low-dimensional subspace of the pre-trained weight matrix. Albeit efficient, LoRA exhibits suboptimal convergence and noticeable performance degradation, due to inconsistent and imbalanced weight updates induced by its nonunique low-rank factorizations. To overcome these limitations, this article identifies the optimal low-rank factorization per step that minimizes an upper bound on the loss. The resultant refactored low-rank adaptation (RefLoRA) method promotes a flatter loss landscape, along with consistent and balanced weight updates, thus speeding up stable convergence. Extensive experiments evaluate RefLoRA on natural language understanding, and commonsense reasoning tasks with popular large language models including DeBERTaV3, LLaMA-7B, LLaMA2-7B and LLaMA3-8B. The numerical tests corroborate that RefLoRA converges faster, outperforms various benchmarks, and enjoys negligible computational overhead compared to state-of-the-art LoRA variants.
Can RLHF be More Efficient with Imperfect Reward Models? A Policy Coverage Perspective
Feb 26, 2025Sample efficiency is critical for online Reinforcement Learning from Human Feedback (RLHF). While existing works investigate sample-efficient online exploration strategies, the potential of utilizing misspecified yet relevant reward models to accelerate learning remains underexplored. This paper studies how to transfer knowledge from those imperfect reward models in online RLHF. We start by identifying a novel property of the KL-regularized RLHF objective: \emph{a policy's ability to cover the optimal policy is captured by its sub-optimality}. Building on this insight, we propose a theoretical transfer learning algorithm with provable benefits compared to standard online learning. Our approach achieves low regret in the early stage by quickly adapting to the best available source reward models without prior knowledge of their quality, and over time, it attains an $\tilde{O}(\sqrt{T})$ regret bound \emph{independent} of structural complexity measures. Inspired by our theoretical findings, we develop an empirical algorithm with improved computational efficiency, and demonstrate its effectiveness empirically in summarization tasks.
Preconditioned Sharpness-Aware Minimization: Unifying Analysis and a Novel Learning Algorithm
Jan 11, 2025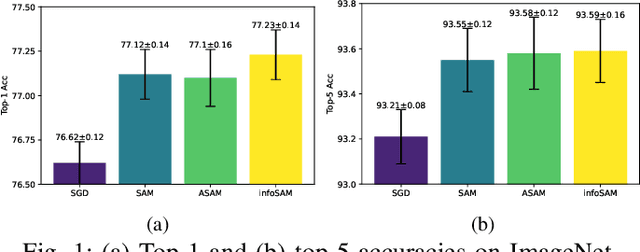
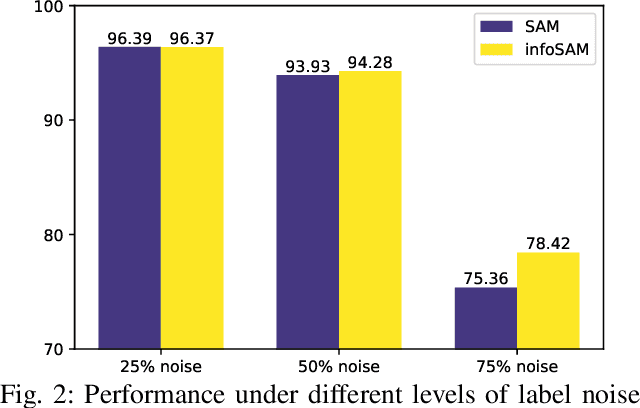
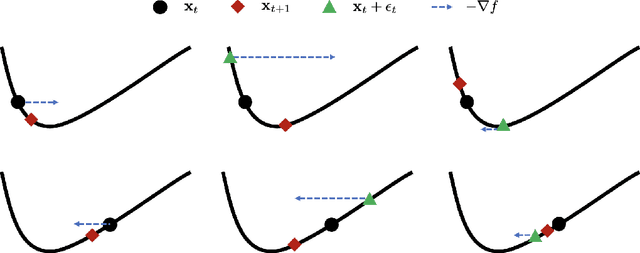
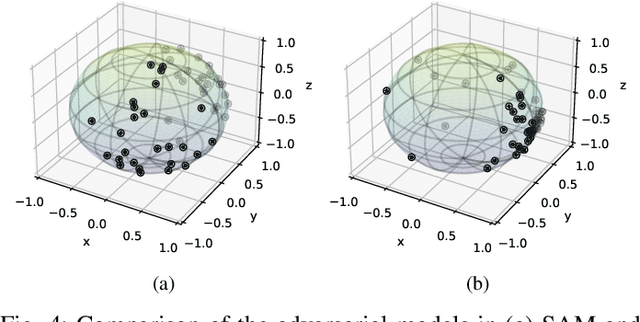
Targeting solutions over `flat' regions of the loss landscape, sharpness-aware minimization (SAM) has emerged as a powerful tool to improve generalizability of deep neural network based learning. While several SAM variants have been developed to this end, a unifying approach that also guides principled algorithm design has been elusive. This contribution leverages preconditioning (pre) to unify SAM variants and provide not only unifying convergence analysis, but also valuable insights. Building upon preSAM, a novel algorithm termed infoSAM is introduced to address the so-called adversarial model degradation issue in SAM by adjusting gradients depending on noise estimates. Extensive numerical tests demonstrate the superiority of infoSAM across various benchmarks.