 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALAAD: Sparse And Low-Rank Adaptation via ADMM
Feb 01, 2026Modern large language models are increasingly deployed under compute and memory constraints, making flexible control of model capacity a central challenge. While sparse and low-rank structures naturally trade off capacity and performance, existing approaches often rely on heuristic designs that ignore layer and matrix heterogeneity or require model-specific architectural modifications. We propose SALAAD, a plug-and-play framework applicable to different model architectures that induces sparse and low-rank structures during training. By formulating structured weight learning under an augmented Lagrangian framework and introducing an adaptive controller that dynamically balances the training loss and structural constraints, SALAAD preserves the stability of standard training dynamics while enabling explicit control over the evolution of effective model capacity during training. Experiments across model scales show that SALAAD substantially reduces memory consumption during deployment while achieving performance comparable to ad-hoc methods. Moreover, a single training run yields a continuous spectrum of model capacities, enabling smooth and elastic deployment across diverse memory budgets without the need for retraining.
Teaching Machine Learning Fundamentals with LEGO Robotics
Jan 27, 2026This paper presents the web-based platform Machine Learning with Bricks and an accompanying two-day course designed to teach machine learning concepts to students aged 12 to 17 through programming-free robotics activities. Machine Learning with Bricks is an open source platform and combines interactive visualizations with LEGO robotics to teach three core algorithms: KNN, linear regression, and Q-learning. Students learn by collecting data, training models, and interacting with robots via a web-based interface. Pre- and post-surveys with 14 students demonstrate significant improvements in conceptual understanding of machine learning algorithms, positive shifts in AI perception, high platform usability, and increased motivation for continued learning. This work demonstrates that tangible, visualization-based approaches can make machine learning concepts accessible and engaging for young learners while maintaining technical depth. The platform is freely available at https://learning-and-dynamics.github.io/ml-with-bricks/, with video tutorials guiding students through the experiments at https://youtube.com/playlist?list=PLx1grFu4zAcwfKKJZ1Ux4LwRqaePCOA2J.
A Systems-Theoretic View on the Convergence of Algorithms under Disturbances
Dec 19, 2025Algorithms increasingly operate within complex physical, social, and engineering systems where they are exposed to disturbances, noise, and interconnections with other dynamical systems. This article extends known convergence guarantees of an algorithm operating in isolation (i.e., without disturbances) and systematically derives stability bounds and convergence rates in the presence of such disturbances. By leveraging converse Lyapunov theorems, we derive key inequalities that quantify the impact of disturbances. We further demonstrate how our result can be utilized to assess the effects of disturbances on algorithmic performance in a wide variety of applications, including communication constraints in distributed learning, sensitivity in machine learning generalization, and intentional noise injection for privacy. This underpins the role of our result as a unifying tool for algorithm analysis in the presence of noise, disturbances, and interconnections with other dynamical systems.
A Critical Perspective on Finite Sample Conformal Prediction Theory in Medical Applications
Dec 09, 2025Machine learning (ML) is transforming healthcare, but safe clinical decisions demand reliable uncertainty estimates that standard ML models fail to provide. Conformal prediction (CP) is a popular tool that allows users to turn heuristic uncertainty estimates into uncertainty estimates with statistical guarantees. CP works by converting predictions of a ML model, together with a calibration sample, into prediction sets that are guaranteed to contain the true label with any desired probability. An often cited advantage is that CP theory holds for calibration samples of arbitrary size, suggesting that uncertainty estimates with practically meaningful statistical guarantees can be achieved even if only small calibration sets are available. We question this promise by showing that, although the statistical guarantees hold for calibration sets of arbitrary size, the practical utility of these guarantees does highly depend on the size of the calibration set. This observation is relevant in medical domains because data is often scarce and obtaining large calibration sets is therefore infeasible. We corroborate our critique in an empirical demonstration on a medical image classification task.
PENEX: AdaBoost-Inspired Neural Network Regularization
Oct 02, 2025AdaBoost sequentially fits so-called weak learners to minimize an exponential loss, which penalizes mislabeled data points more severely than other loss functions like cross-entropy. Paradoxically, AdaBoost generalizes well in practice as the number of weak learners grows. In the present work, we introduce Penalized Exponential Loss (PENEX), a new formulation of the multi-class exponential loss that is theoretically grounded and, in contrast to the existing formulation, amenable to optimization via first-order methods. We demonstrate both empirically and theoretically that PENEX implicitly maximizes margins of data points. Also, we show that gradient increments on PENEX implicitly parameterize weak learners in the boosting framework. Across computer vision and language tasks, we show that PENEX exhibits a regularizing effect often better than established methods with similar computational cost. Our results highlight PENEX's potential as an AdaBoost-inspired alternative for effective training and fine-tuning of deep neural networks.
Embodied Intelligence for Sustainable Flight: A Soaring Robot with Active Morphological Control
Aug 27, 2025Achieving both agile maneuverability and high energy efficiency in aerial robots, particularly in dynamic wind environments, remains challenging. Conventional thruster-powered systems offer agility but suffer from high energy consumption, while fixed-wing designs are efficient but lack hovering and maneuvering capabilities. We present Floaty, a shape-changing robot that overcomes these limitations by passively soaring, harnessing wind energy through intelligent morphological control inspired by birds. Floaty's design is optimized for passive stability, and its control policy is derived from an experimentally learned aerodynamic model, enabling precise attitude and position control without active propulsion. Wind tunnel experiments demonstrate Floaty's ability to hover, maneuver, and reject disturbances in vertical airflows up to 10 m/s. Crucially, Floaty achieves this with a specific power consumption of 10 W/kg, an order of magnitude lower than thruster-powered systems. This introduces a paradigm for energy-efficient aerial robotics, leveraging morphological intelligence and control to operate sustainably in challenging wind conditions.
Zeroth-Order Optimization Finds Flat Minima
Jun 05, 2025Zeroth-order methods are extensively used in machine learning applications where gradients are infeasible or expensive to compute, such as black-box attacks, reinforcement learning, and language model fine-tuning. Existing optimization theory focuses on convergence to an arbitrary stationary point, but less is known on the implicit regularization that provides a fine-grained characterization on which particular solutions are finally reached. We show that zeroth-order optimization with the standard two-point estimator favors solutions with small trace of Hessian, which is widely used in previous work to distinguish between sharp and flat minima. We further provide convergence rates of zeroth-order optimization to approximate flat minima for convex and sufficiently smooth functions, where flat minima are defined as the minimizers that achieve the smallest trace of Hessian among all optimal solutions. Experiments on binary classification tasks with convex losses and language model fine-tuning support our theoretical findings.
ESLM: Risk-Averse Selective Language Modeling for Efficient Pretraining
May 26, 2025Large language model pretraining is compute-intensive, yet many tokens contribute marginally to learning, resulting in inefficiency. We introduce Efficient Selective Language Modeling (ESLM), a risk-aware algorithm that improves training efficiency and distributional robustness by performing online token-level batch selection. ESLM leverages per-token statistics (e.g., entropy or loss) and applies value-at-risk thresholding to retain only the most informative tokens per batch. This data-centric mechanism reshapes the training loss, prioritizing high-risk tokens and eliminating redundant gradient computation. We frame ESLM as a bilevel game: the model competes with a masking adversary that selects worst-case token subsets under a constrained thresholding rule. In the loss-based setting, ESLM recovers conditional value-at-risk loss minimization, providing a principled connection to distributionally robust optimization. We extend our approach to Ada-ESLM, which adaptively tunes the selection confidence during training. Experiments on GPT-2 pretraining show that ESLM significantly reduces training FLOPs while maintaining or improving both perplexity and downstream performance compared to baselines. Our approach also scales across model sizes, pretraining corpora, and integrates naturally with knowledge distillation.
Constraint-Aware Diffusion Guidance for Robotics: Real-Time Obstacle Avoidance for Autonomous Racing
May 19, 2025Diffusion models hold great potential in robotics due to their ability to capture complex, high-dimensional data distributions. However, their lack of constraint-awareness limits their deployment in safety-critical applications. We propose Constraint-Aware Diffusion Guidance (CoDiG), a data-efficient and general-purpose framework that integrates barrier functions into the denoising process, guiding diffusion sampling toward constraint-satisfying outputs. CoDiG enables constraint satisfaction even with limited training data and generalizes across tasks. We evaluate our framework in the challenging setting of miniature autonomous racing, where real-time obstacle avoidance is essential. Real-world experiments show that CoDiG generates safe outputs efficiently under dynamic conditions, highlighting its potential for broader robotic applications. A demonstration video is available at https://youtu.be/KNYsTdtdxOU.
Quantization-Free Autoregressive Action Transformer
Mar 18, 2025
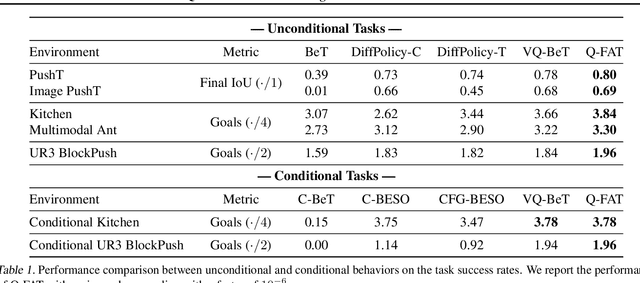
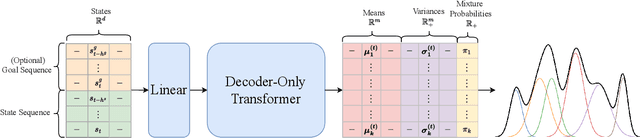
Current transformer-based imitation learning approaches introduce discrete action representations and train an autoregressive transformer decoder on the resulting latent code. However, the initial quantization breaks the continuous structure of the action space thereby limiting the capabilities of the generative model. We propose a quantization-free method instead that leverages Generative Infinite-Vocabulary Transformers (GIVT) as a direct, continuous policy parametrization for autoregressive transformers. This simplifies the imitation learning pipeline while achieving state-of-the-art performance on a variety of popular simulated robotics tasks. We enhance our policy roll-outs by carefully studying sampling algorithms, further improving the results.