 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Gray-Box Approach for Decentralized Grid-Equivalent Model Identification
May 27, 2026We propose a decentralized, frequency-domain identification algorithm that estimates the grid-equivalent model from the perspective of local converters. Since local electric signals in a multi-converter setup are affected by voltage inputs from other converters, considered as the grid, estimating a single apparent impedance yields biased and inaccurate results. To overcome this, we design a framework that decouples the effect of the equivalent impedance (passive) from that of the equivalent voltage (active). The parameters and equivalent grid voltages are then estimated using a constrained least squares and a Kalman filter algorithm, respectively, applied across frequency samples. We then demonstrate the accuracy and performance of our algorithm on an interconnected 5-converter system in grid-forming mode, with minimal voltage excitations and non-ideal operating conditions.
Optimistic Online LQR via Intrinsic Rewards
Mar 30, 2026Optimism in the face of uncertainty is a popular approach to balance exploration and exploitation in reinforcement learning. Here, we consider the online linear quadratic regulator (LQR) problem, i.e., to learn the LQR corresponding to an unknown linear dynamical system by adapting the control policy online based on closed-loop data collected during operation. In this work, we propose Intrinsic Rewards LQR (IR-LQR), an optimistic online LQR algorithm that applies the idea of intrinsic rewards originating from reinforcement learning and the concept of variance regularization to promote uncertainty-driven exploration. IR-LQR retains the structure of a standard LQR synthesis problem by only modifying the cost function, resulting in an intuitively pleasing, simple, computationally cheap, and efficient algorithm. This is in contrast to existing optimistic online LQR formulations that rely on more complicated iterative search algorithms or solve computationally demanding optimization problems. We show that IR-LQR achieves the optimal worst-case regret rate of $\sqrt{T}$, and compare it to various state-of-the-art online LQR algorithms via numerical experiments carried out on an aircraft pitch angle control and an unmanned aerial vehicle example.
Data-driven generalized perimeter control: Zürich case study
Mar 17, 2026Urban traffic congestion is a key challenge for the development of modern cities, requiring advanced control techniques to optimize existing infrastructures usage. Despite the extensive availability of data, modeling such complex systems remains an expensive and time consuming step when designing model-based control approaches. On the other hand, machine learning approaches require simulations to bootstrap models, or are unable to deal with the sparse nature of traffic data and enforce hard constraints. We propose a novel formulation of traffic dynamics based on behavioral systems theory and apply data-enabled predictive control to steer traffic dynamics via dynamic traffic light control. A high-fidelity simulation of the city of Zürich, the largest closed-loop microscopic simulation of urban traffic in the literature to the best of our knowledge, is used to validate the performance of the proposed method in terms of total travel time and CO2 emissions.
Socially-Aware Recommender Systems Mitigate Opinion Clusterization
Jan 02, 2026Recommender systems shape online interactions by matching users with creators content to maximize engagement. Creators, in turn, adapt their content to align with users preferences and enhance their popularity. At the same time, users preferences evolve under the influence of both suggested content from the recommender system and content shared within their social circles. This feedback loop generates a complex interplay between users, creators, and recommender algorithms, which is the key cause of filter bubbles and opinion polarization. We develop a social network-aware recommender system that explicitly accounts for this user-creators feedback interaction and strategically exploits the topology of the user's own social network to promote diversification. Our approach highlights how accounting for and exploiting user's social network in the recommender system design is crucial to mediate filter bubble effects while balancing content diversity with personalization. Provably, opinion clusterization is positively correlated with the influence of recommended content on user opinions. Ultimately, the proposed approach shows the power of socially-aware recommender systems in combating opinion polarization and clusterization phenomena.
MPC for momentum counter-balanced and zero-impulse contact with a free-spinning satellite
Dec 10, 2025In on-orbit robotics, a servicer satellite's ability to make contact with a free-spinning target satellite is essential to completing most on-orbit servicing (OOS) tasks. This manuscript develops a nonlinear model predictive control (MPC) framework that generates feasible controls for a servicer satellite to achieve zero-impulse contact with a free-spinning target satellite. The overall maneuver requires coordination between two separately actuated modules of the servicer satellite: (1) a moment generation module and (2) a manipulation module. We apply MPC to control both modules by explicitly modeling the cross-coupling dynamics between them. We demonstrate that the MPC controller can enforce actuation and state constraints that prior control approaches could not account for. We evaluate the performance of the MPC controller by simulating zero-impulse contact scenarios with a free-spinning target satellite via numerical Monte Carlo (MC) trials and comparing the simulation results with prior control approaches. Our simulation results validate the effectiveness of the MPC controller in maintaining spin synchronization and zero-impulse contact under operation constraints, moving contact location, and observation and actuation noise.
Ultrafast Grid Impedance Identification in $dq$-Asymmetric Three-Phase Power Systems
Oct 14, 2025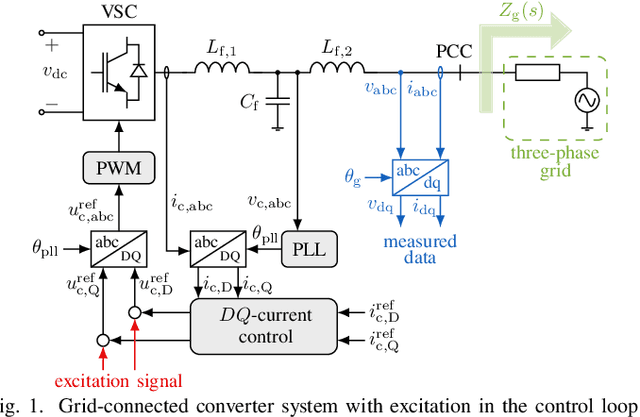


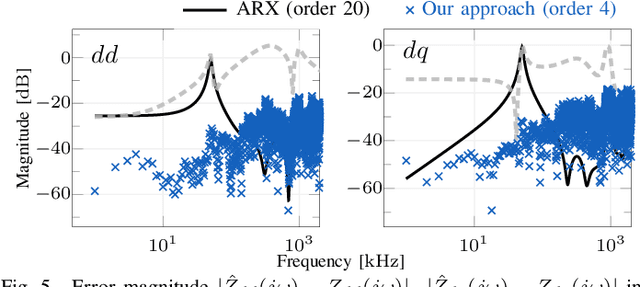
We propose a non-parametric frequency-domain method to identify small-signal $dq$-asymmetric grid impedances, over a wide frequency band, using grid-connected converters. Existing identification methods are faced with significant trade-offs: e.g., passive approaches rely on ambient harmonics and rare grid events and thus can only provide estimates at a few frequencies, while many active approaches that intentionally perturb grid operation require long time series measurement and specialized equipment. Although active time-domain methods reduce the measurement time, they either make crude simplifying assumptions or require laborious model order tuning. Our approach effectively addresses these challenges: it does not require specialized excitation signals or hardware and achieves ultrafast ($<1$ s) identification, drastically reducing measurement time. Being non-parametric, our approach also makes no assumptions on the grid structure. A detailed electromagnetic transient simulation is used to validate the method and demonstrate its clear superiority over existing alternatives.
Learn to Bid as a Price-Maker Wind Power Producer
Mar 20, 2025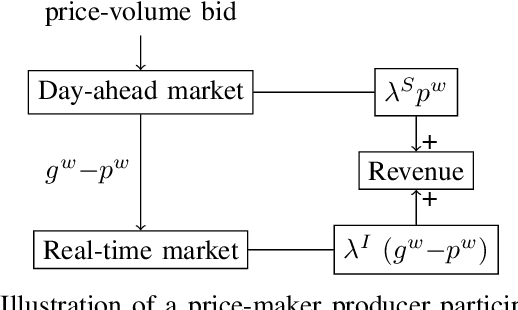
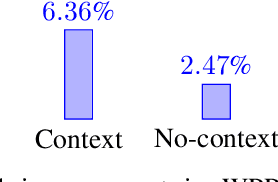
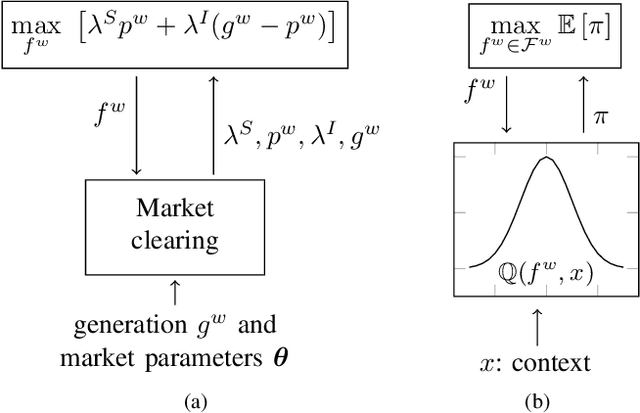
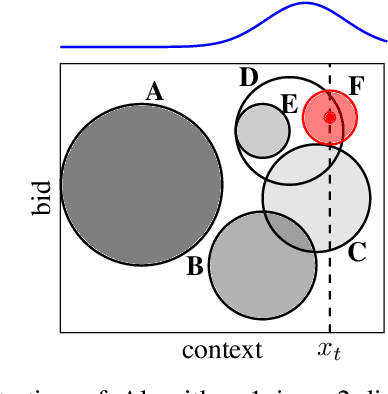
Wind power producers (WPPs) participating in short-term power markets face significant imbalance costs due to their non-dispatchable and variable production. While some WPPs have a large enough market share to influence prices with their bidding decisions, existing optimal bidding methods rarely account for this aspect. Price-maker approaches typically model bidding as a bilevel optimization problem, but these methods require complex market models, estimating other participants' actions, and are computationally demanding. To address these challenges, we propose an online learning algorithm that leverages contextual information to optimize WPP bids in the price-maker setting. We formulate the strategic bidding problem as a contextual multi-armed bandit, ensuring provable regret minimization. The algorithm's performance is evaluated against various benchmark strategies using a numerical simulation of the German day-ahead and real-time markets.
Decision-Dependent Stochastic Optimization: The Role of Distribution Dynamics
Mar 10, 2025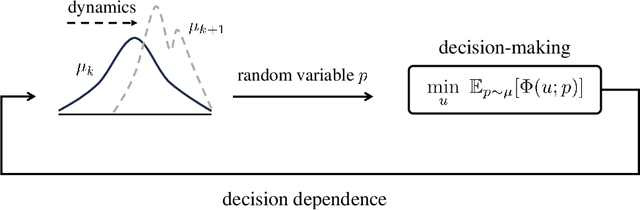
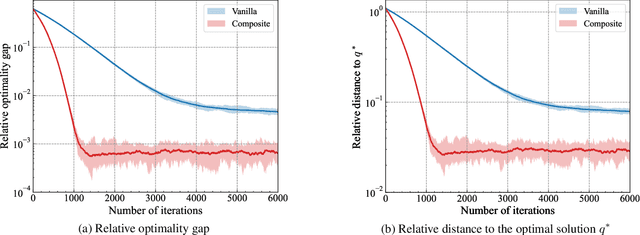
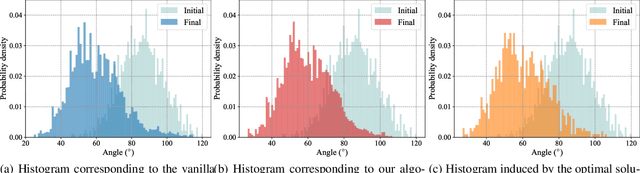
Distribution shifts have long been regarded as troublesome external forces that a decision-maker should either counteract or conform to. An intriguing feedback phenomenon termed decision dependence arises when the deployed decision affects the environment and alters the data-generating distribution. In the realm of performative prediction, this is encoded by distribution maps parameterized by decisions due to strategic behaviors. In contrast, we formalize an endogenous distribution shift as a feedback process featuring nonlinear dynamics that couple the evolving distribution with the decision. Stochastic optimization in this dynamic regime provides a fertile ground to examine the various roles played by dynamics in the composite problem structure. To this end, we develop an online algorithm that achieves optimal decision-making by both adapting to and shaping the dynamic distribution. Throughout the paper, we adopt a distributional perspective and demonstrate how this view facilitates characterizations of distribution dynamics and the optimality and generalization performance of the proposed algorithm. We showcase the theoretical results in an opinion dynamics context, where an opportunistic party maximizes the affinity of a dynamic polarized population, and in a recommender system scenario, featuring performance optimization with discrete distributions in the probability simplex.
An Adaptive Data-Enabled Policy Optimization Approach for Autonomous Bicycle Control
Feb 19, 2025This paper presents a unified control framework that integrates a Feedback Linearization (FL) controller in the inner loop with an adaptive Data-Enabled Policy Optimization (DeePO) controller in the outer loop to balance an autonomous bicycle. While the FL controller stabilizes and partially linearizes the inherently unstable and nonlinear system, its performance is compromised by unmodeled dynamics and time-varying characteristics. To overcome these limitations, the DeePO controller is introduced to enhance adaptability and robustness. The initial control policy of DeePO is obtained from a finite set of offline, persistently exciting input and state data. To improve stability and compensate for system nonlinearities and disturbances, a robustness-promoting regularizer refines the initial policy, while the adaptive section of the DeePO framework is enhanced with a forgetting factor to improve adaptation to time-varying dynamics. The proposed DeePO+FL approach is evaluated through simulations and real-world experiments on an instrumented autonomous bicycle. Results demonstrate its superiority over the FL-only approach, achieving more precise tracking of the reference lean angle and lean rate.
Contractivity and linear convergence in bilinear saddle-point problems: An operator-theoretic approach
Oct 18, 2024
We study the convex-concave bilinear saddle-point problem $\min_x \max_y f(x) + y^\top Ax - g(y)$, where both, only one, or none of the functions $f$ and $g$ are strongly convex, and suitable rank conditions on the matrix $A$ hold. The solution of this problem is at the core of many machine learning tasks. By employing tools from operator theory, we systematically prove the contractivity (in turn, the linear convergence) of several first-order primal-dual algorithms, including the Chambolle-Pock method. Our approach results in concise and elegant proofs, and it yields new convergence guarantees and tighter bounds compared to known results.