 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Soft Robotic Dynamics with Active Exploration
Oct 31, 2025Soft robots offer unmatched adaptability and safety in unstructured environments, yet their compliant, high-dimensional, and nonlinear dynamics make modeling for control notoriously difficult. Existing data-driven approaches often fail to generalize, constrained by narrowly focused task demonstrations or inefficient random exploration. We introduce SoftAE, an uncertainty-aware active exploration framework that autonomously learns task-agnostic and generalizable dynamics models of soft robotic systems. SoftAE employs probabilistic ensemble models to estimate epistemic uncertainty and actively guides exploration toward underrepresented regions of the state-action space, achieving efficient coverage of diverse behaviors without task-specific supervision. We evaluate SoftAE on three simulated soft robotic platforms -- a continuum arm, an articulated fish in fluid, and a musculoskeletal leg with hybrid actuation -- and on a pneumatically actuated continuum soft arm in the real world. Compared with random exploration and task-specific model-based reinforcement learning, SoftAE produces more accurate dynamics models, enables superior zero-shot control on unseen tasks, and maintains robustness under sensing noise, actuation delays, and nonlinear material effects. These results demonstrate that uncertainty-driven active exploration can yield scalable, reusable dynamics models across diverse soft robotic morphologies, representing a step toward more autonomous, adaptable, and data-efficient control in compliant robots.
MaxInfoRL: Boosting exploration in reinforcement learning through information gain maximization
Dec 16, 2024



Reinforcement learning (RL) algorithms aim to balance exploiting the current best strategy with exploring new options that could lead to higher rewards. Most common RL algorithms use undirected exploration, i.e., select random sequences of actions. Exploration can also be directed using intrinsic rewards, such as curiosity or model epistemic uncertainty. However, effectively balancing task and intrinsic rewards is challenging and often task-dependent. In this work, we introduce a framework, MaxInfoRL, for balancing intrinsic and extrinsic exploration. MaxInfoRL steers exploration towards informative transitions, by maximizing intrinsic rewards such as the information gain about the underlying task. When combined with Boltzmann exploration, this approach naturally trades off maximization of the value function with that of the entropy over states, rewards, and actions. We show that our approach achieves sublinear regret in the simplified setting of multi-armed bandits. We then apply this general formulation to a variety of off-policy model-free RL methods for continuous state-action spaces, yielding novel algorithms that achieve superior performance across hard exploration problems and complex scenarios such as visual control tasks.
ActSafe: Active Exploration with Safety Constraints for Reinforcement Learning
Oct 12, 2024



Reinforcement learning (RL) is ubiquitous in the development of modern AI systems. However, state-of-the-art RL agents require extensive, and potentially unsafe, interactions with their environments to learn effectively. These limitations confine RL agents to simulated environments, hindering their ability to learn directly in real-world settings. In this work, we present ActSafe, a novel model-based RL algorithm for safe and efficient exploration. ActSafe learns a well-calibrated probabilistic model of the system and plans optimistically w.r.t. the epistemic uncertainty about the unknown dynamics, while enforcing pessimism w.r.t. the safety constraints. Under regularity assumptions on the constraints and dynamics, we show that ActSafe guarantees safety during learning while also obtaining a near-optimal policy in finite time. In addition, we propose a practical variant of ActSafe that builds on latest model-based RL advancements and enables safe exploration even in high-dimensional settings such as visual control. We empirically show that ActSafe obtains state-of-the-art performance in difficult exploration tasks on standard safe deep RL benchmarks while ensuring safety during learning.
When to Sense and Control? A Time-adaptive Approach for Continuous-Time RL
Jun 04, 2024Reinforcement learning (RL) excels in optimizing policies for discrete-time Markov decision processes (MDP). However, various systems are inherently continuous in time, making discrete-time MDPs an inexact modeling choice. In many applications, such as greenhouse control or medical treatments, each interaction (measurement or switching of action) involves manual intervention and thus is inherently costly. Therefore, we generally prefer a time-adaptive approach with fewer interactions with the system. In this work, we formalize an RL framework, Time-adaptive Control & Sensing (TaCoS), that tackles this challenge by optimizing over policies that besides control predict the duration of its application. Our formulation results in an extended MDP that any standard RL algorithm can solve. We demonstrate that state-of-the-art RL algorithms trained on TaCoS drastically reduce the interaction amount over their discrete-time counterpart while retaining the same or improved performance, and exhibiting robustness over discretization frequency. Finally, we propose OTaCoS, an efficient model-based algorithm for our setting. We show that OTaCoS enjoys sublinear regret for systems with sufficiently smooth dynamics and empirically results in further sample-efficiency gains.
NeoRL: Efficient Exploration for Nonepisodic RL
Jun 04, 2024We study the problem of nonepisodic reinforcement learning (RL) for nonlinear dynamical systems, where the system dynamics are unknown and the RL agent has to learn from a single trajectory, i.e., without resets. We propose Nonepisodic Optimistic RL (NeoRL), an approach based on the principle of optimism in the face of uncertainty. NeoRL uses well-calibrated probabilistic models and plans optimistically w.r.t. the epistemic uncertainty about the unknown dynamics. Under continuity and bounded energy assumptions on the system, we provide a first-of-its-kind regret bound of $\setO(\beta_T \sqrt{T \Gamma_T})$ for general nonlinear systems with Gaussian process dynamics. We compare NeoRL to other baselines on several deep RL environments and empirically demonstrate that NeoRL achieves the optimal average cost while incurring the least regret.
Safe Exploration Using Bayesian World Models and Log-Barrier Optimization
May 09, 2024A major challenge in deploying reinforcement learning in online tasks is ensuring that safety is maintained throughout the learning process. In this work, we propose CERL, a new method for solving constrained Markov decision processes while keeping the policy safe during learning. Our method leverages Bayesian world models and suggests policies that are pessimistic w.r.t. the model's epistemic uncertainty. This makes CERL robust towards model inaccuracies and leads to safe exploration during learning. In our experiments, we demonstrate that CERL outperforms the current state-of-the-art in terms of safety and optimality in solving CMDPs from image observations.
Bridging the Sim-to-Real Gap with Bayesian Inference
Mar 25, 2024We present SIM-FSVGD for learning robot dynamics from data. As opposed to traditional methods, SIM-FSVGD leverages low-fidelity physical priors, e.g., in the form of simulators, to regularize the training of neural network models. While learning accurate dynamics already in the low data regime, SIM-FSVGD scales and excels also when more data is available. We empirically show that learning with implicit physical priors results in accurate mean model estimation as well as precise uncertainty quantification. We demonstrate the effectiveness of SIM-FSVGD in bridging the sim-to-real gap on a high-performance RC racecar system. Using model-based RL, we demonstrate a highly dynamic parking maneuver with drifting, using less than half the data compared to the state of the art.
Information-based Transductive Active Learning
Feb 13, 2024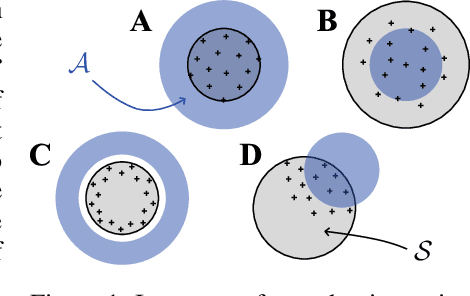
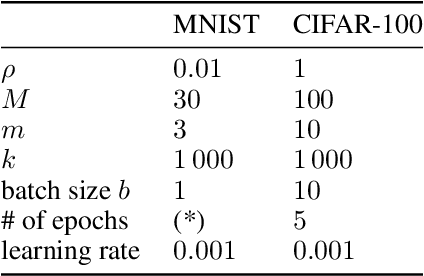
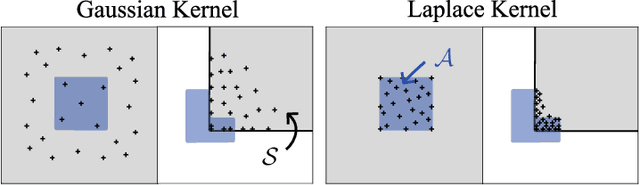
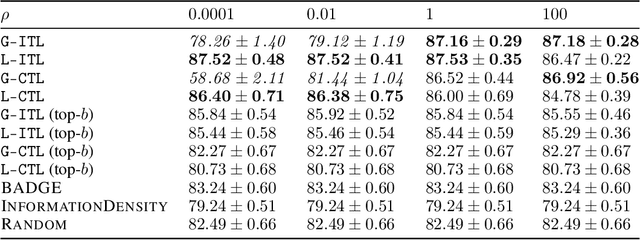
We generalize active learning to address real-world settings where sampling is restricted to an accessible region of the domain, while prediction targets may lie outside this region. To this end, we propose ITL, short for information-based transductive learning, an approach which samples adaptively to maximize the information gained about specified prediction targets. We show, under general regularity assumptions, that ITL converges uniformly to the smallest possible uncertainty obtainable from the accessible data. We demonstrate ITL in two key applications: Few-shot fine-tuning of large neural networks and safe Bayesian optimization, and in both cases, ITL significantly outperforms the state-of-the-art.
Active Few-Shot Fine-Tuning
Feb 13, 2024We study the active few-shot fine-tuning of large neural networks to downstream tasks. We show that few-shot fine-tuning is an instance of a generalization of classical active learning, transductive active learning, and we propose ITL, short for information-based transductive learning, an approach which samples adaptively to maximize the information gained about specified downstream tasks. Under general regularity assumptions, we prove that ITL converges uniformly to the smallest possible uncertainty obtainable from the accessible data. To the best of our knowledge, we are the first to derive generalization bounds of this kind, and they may be of independent interest for active learning. We apply ITL to the few-shot fine-tuning of large neural networks and show that ITL substantially improves upon the state-of-the-art.
Data-Efficient Task Generalization via Probabilistic Model-based Meta Reinforcement Learning
Nov 13, 2023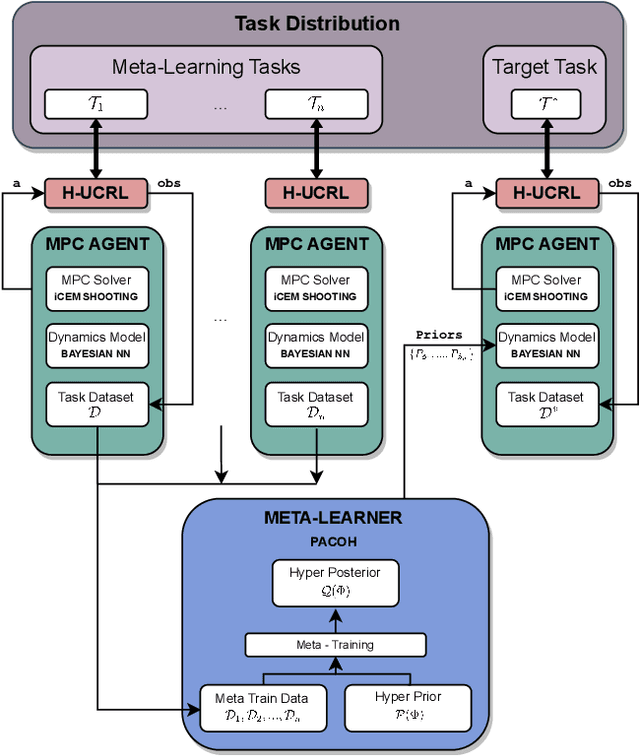


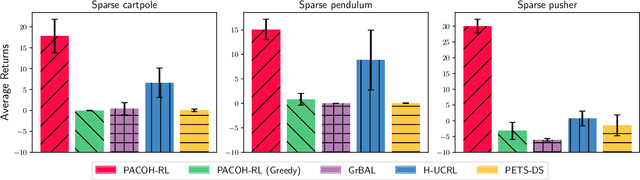
We introduce PACOH-RL, a novel model-based Meta-Reinforcement Learning (Meta-RL) algorithm designed to efficiently adapt control policies to changing dynamics. PACOH-RL meta-learns priors for the dynamics model, allowing swift adaptation to new dynamics with minimal interaction data. Existing Meta-RL methods require abundant meta-learning data, limiting their applicability in settings such as robotics, where data is costly to obtain. To address this, PACOH-RL incorporates regularization and epistemic uncertainty quantification in both the meta-learning and task adaptation stages. When facing new dynamics, we use these uncertainty estimates to effectively guide exploration and data collection. Overall, this enables positive transfer, even when access to data from prior tasks or dynamic settings is severely limited. Our experiment results demonstrate that PACOH-RL outperforms model-based RL and model-based Meta-RL baselines in adapting to new dynamic conditions. Finally, on a real robotic car, we showcase the potential for efficient RL policy adaptation in diverse, data-scarce conditions.