 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Binary: Sim-to-Real Dexterous Manipulation with Physics-Grounded Contact Representation
May 27, 2026A primary bottleneck in contact-rich manipulation is the difficulty of collecting real-world data. Sim-to-real reinforcement learning offers a scalable alternative, but the simulation-reality gap prevents information-dense modalities like touch from being effectively used. Existing sim-to-real methods often mitigate this gap by simplifying tactile data into coarse low-dimensional features -- sacrificing the richness required for complex manipulation. In this work, we introduce Center-of-Pressure (CoP), an effective tactile representation grounded in physical principles that preserves dense contact information while maintaining robustness for sim-to-real transfer. To support this representation, we propose a sensor calibration scheme based on differentiable dynamics, enabling the estimation of taxel orientations without requiring ground-truth force measurements. We evaluate CoP on two blind, challenging contact-rich manipulation tasks: peg-in-hole insertion and ball balancing. Across both tasks, policies conditioned on CoP achieve zero-shot sim-to-real transfer on a multi-fingered hand, and outperform both coarse binary-contact and raw-taxel baselines. Analysis of learned policy states further suggests that CoP-conditioned policies encode task-relevant physical properties, such as object mass, as an emergent byproduct of control.
PAINT: Partner-Agnostic Intent-Aware Cooperative Transport with Legged Robots
Apr 14, 2026Collaborative transport requires robots to infer partner intent through physical interaction while maintaining stable loco-manipulation. This becomes particularly challenging in complex environments, where interaction signals are difficult to capture and model. We present PAINT, a lightweight yet efficient hierarchical learning framework for partner-agonistic intent-aware collaborative legged transport that infers partner intent directly from proprioceptive feedback. PAINT decouples intent understanding from terrain-robust locomotion: A high-level policy infers the partner interaction wrench using an intent estimator and a teacher-student training scheme, while a low-level locomotion backbone ensures robust execution. This enables lightweight deployment without external force-torque sensing or payload tracking. Extensive simulation and real-world experiments demonstrate compliant cooperative transport across diverse terrains, payloads, and partners. Furthermore, we show that PAINT naturally scales to decentralized multi-robot transport and transfers across robot embodiments by swapping the underlying locomotion backbone. Our results suggest that proprioceptive signals in payload-coupled interaction provide a scalable interface for partner-agnostic intent-aware collaborative transport.
Differentiable Environment-Trajectory Co-Optimization for Safe Multi-Agent Navigation
Apr 08, 2026The environment plays a critical role in multi-agent navigation by imposing spatial constraints, rules, and limitations that agents must navigate around. Traditional approaches treat the environment as fixed, without exploring its impact on agents' performance. This work considers environment configurations as decision variables, alongside agent actions, to jointly achieve safe navigation. We formulate a bi-level problem, where the lower-level sub-problem optimizes agent trajectories that minimize navigation cost and the upper-level sub-problem optimizes environment configurations that maximize navigation safety. We develop a differentiable optimization method that iteratively solves the lower-level sub-problem with interior point methods and the upper-level sub-problem with gradient ascent. A key challenge lies in analytically coupling these two levels. We address this by leveraging KKT conditions and the Implicit Function Theorem to compute gradients of agent trajectories w.r.t. environment parameters, enabling differentiation throughout the bi-level structure. Moreover, we propose a novel metric that quantifies navigation safety as a criterion for the upper-level environment optimization, and prove its validity through measure theory. Our experiments validate the effectiveness of the proposed framework in a variety of safety-critical navigation scenarios, inspired from warehouse logistics to urban transportation. The results demonstrate that optimized environments provide navigation guidance, improving both agents' safety and efficiency.
Maximum Entropy Behavior Exploration for Sim2Real Zero-Shot Reinforcement Learning
Mar 26, 2026Zero-shot reinforcement learning (RL) algorithms aim to learn a family of policies from a reward-free dataset, and recover optimal policies for any reward function directly at test time. Naturally, the quality of the pretraining dataset determines the performance of the recovered policies across tasks. However, pre-collecting a relevant, diverse dataset without prior knowledge of the downstream tasks of interest remains a challenge. In this work, we study $\textit{online}$ zero-shot RL for quadrupedal control on real robotic systems, building upon the Forward-Backward (FB) algorithm. We observe that undirected exploration yields low-diversity data, leading to poor downstream performance and rendering policies impractical for direct hardware deployment. Therefore, we introduce FB-MEBE, an online zero-shot RL algorithm that combines an unsupervised behavior exploration strategy with a regularization critic. FB-MEBE promotes exploration by maximizing the entropy of the achieved behavior distribution. Additionally, a regularization critic shapes the recovered policies toward more natural and physically plausible behaviors. We empirically demonstrate that FB-MEBE achieves and improved performance compared to other exploration strategies in a range of simulated downstream tasks, and that it renders natural policies that can be seamlessly deployed to hardware without further finetuning. Videos and code available on our website.
What Matters for Simulation to Online Reinforcement Learning on Real Robots
Feb 23, 2026We investigate what specific design choices enable successful online reinforcement learning (RL) on physical robots. Across 100 real-world training runs on three distinct robotic platforms, we systematically ablate algorithmic, systems, and experimental decisions that are typically left implicit in prior work. We find that some widely used defaults can be harmful, while a set of robust, readily adopted design choices within standard RL practice yield stable learning across tasks and hardware. These results provide the first large-sample empirical study of such design choices, enabling practitioners to deploy online RL with lower engineering effort.
VQ-Style: Disentangling Style and Content in Motion with Residual Quantized Representations
Feb 02, 2026Human motion data is inherently rich and complex, containing both semantic content and subtle stylistic features that are challenging to model. We propose a novel method for effective disentanglement of the style and content in human motion data to facilitate style transfer. Our approach is guided by the insight that content corresponds to coarse motion attributes while style captures the finer, expressive details. To model this hierarchy, we employ Residual Vector Quantized Variational Autoencoders (RVQ-VAEs) to learn a coarse-to-fine representation of motion. We further enhance the disentanglement by integrating contrastive learning and a novel information leakage loss with codebook learning to organize the content and the style across different codebooks. We harness this disentangled representation using our simple and effective inference-time technique Quantized Code Swapping, which enables motion style transfer without requiring any fine-tuning for unseen styles. Our framework demonstrates strong versatility across multiple inference applications, including style transfer, style removal, and motion blending.
Safe Exploration via Policy Priors
Jan 27, 2026Safe exploration is a key requirement for reinforcement learning (RL) agents to learn and adapt online, beyond controlled (e.g. simulated) environments. In this work, we tackle this challenge by utilizing suboptimal yet conservative policies (e.g., obtained from offline data or simulators) as priors. Our approach, SOOPER, uses probabilistic dynamics models to optimistically explore, yet pessimistically fall back to the conservative policy prior if needed. We prove that SOOPER guarantees safety throughout learning, and establish convergence to an optimal policy by bounding its cumulative regret. Extensive experiments on key safe RL benchmarks and real-world hardware demonstrate that SOOPER is scalable, outperforms the state-of-the-art and validate our theoretical guarantees in practice.
Teaching Robots Like Dogs: Learning Agile Navigation from Luring, Gesture, and Speech
Jan 13, 2026In this work, we aim to enable legged robots to learn how to interpret human social cues and produce appropriate behaviors through physical human guidance. However, learning through physical engagement can place a heavy burden on users when the process requires large amounts of human-provided data. To address this, we propose a human-in-the-loop framework that enables robots to acquire navigational behaviors in a data-efficient manner and to be controlled via multimodal natural human inputs, specifically gestural and verbal commands. We reconstruct interaction scenes using a physics-based simulation and aggregate data to mitigate distributional shifts arising from limited demonstration data. Our progressive goal cueing strategy adaptively feeds appropriate commands and navigation goals during training, leading to more accurate navigation and stronger alignment between human input and robot behavior. We evaluate our framework across six real-world agile navigation scenarios, including jumping over or avoiding obstacles. Our experimental results show that our proposed method succeeds in almost all trials across these scenarios, achieving a 97.15% task success rate with less than 1 hour of demonstration data in total.
Multi-Domain Motion Embedding: Expressive Real-Time Mimicry for Legged Robots
Dec 08, 2025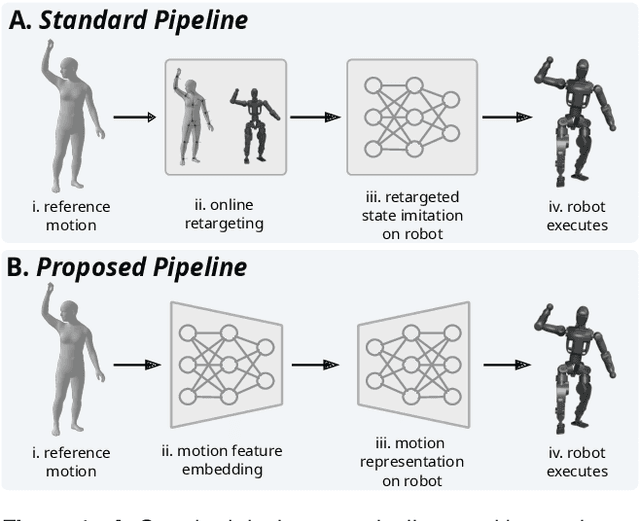

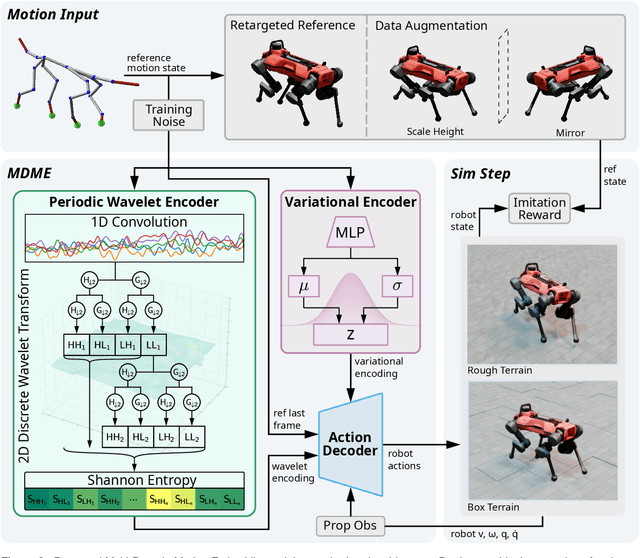

Effective motion representation is crucial for enabling robots to imitate expressive behaviors in real time, yet existing motion controllers often ignore inherent patterns in motion. Previous efforts in representation learning do not attempt to jointly capture structured periodic patterns and irregular variations in human and animal movement. To address this, we present Multi-Domain Motion Embedding (MDME), a motion representation that unifies the embedding of structured and unstructured features using a wavelet-based encoder and a probabilistic embedding in parallel. This produces a rich representation of reference motions from a minimal input set, enabling improved generalization across diverse motion styles and morphologies. We evaluate MDME on retargeting-free real-time motion imitation by conditioning robot control policies on the learned embeddings, demonstrating accurate reproduction of complex trajectories on both humanoid and quadruped platforms. Our comparative studies confirm that MDME outperforms prior approaches in reconstruction fidelity and generalizability to unseen motions. Furthermore, we demonstrate that MDME can reproduce novel motion styles in real-time through zero-shot deployment, eliminating the need for task-specific tuning or online retargeting. These results position MDME as a generalizable and structure-aware foundation for scalable real-time robot imitation.
Collaborative Loco-Manipulation for Pick-and-Place Tasks with Dynamic Reward Curriculum
Sep 16, 2025We present a hierarchical RL pipeline for training one-armed legged robots to perform pick-and-place (P&P) tasks end-to-end -- from approaching the payload to releasing it at a target area -- in both single-robot and cooperative dual-robot settings. We introduce a novel dynamic reward curriculum that enables a single policy to efficiently learn long-horizon P&P operations by progressively guiding the agents through payload-centered sub-objectives. Compared to state-of-the-art approaches for long-horizon RL tasks, our method improves training efficiency by 55% and reduces execution time by 18.6% in simulation experiments. In the dual-robot case, we show that our policy enables each robot to attend to different components of its observation space at distinct task stages, promoting effective coordination via autonomous attention shifts. We validate our method through real-world experiments using ANYmal D platforms in both single- and dual-robot scenarios. To our knowledge, this is the first RL pipeline that tackles the full scope of collaborative P&P with two legged manipulators.