 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Forward-Backward Representations for Zero-shot Reinforcement Learning with General Utilities
Feb 06, 2026Recent advancements in zero-shot reinforcement learning (RL) have facilitated the extraction of diverse behaviors from unlabeled, offline data sources. In particular, forward-backward algorithms (FB) can retrieve a family of policies that can approximately solve any standard RL problem (with additive rewards, linear in the occupancy measure), given sufficient capacity. While retaining zero-shot properties, we tackle the greater problem class of RL with general utilities, in which the objective is an arbitrary differentiable function of the occupancy measure. This setting is strictly more expressive, capturing tasks such as distribution matching or pure exploration, which may not be reduced to additive rewards. We show that this additional complexity can be captured by a novel, maximum entropy (soft) variant of the forward-backward algorithm, which recovers a family of stochastic policies from offline data. When coupled with zero-order search over compact policy embeddings, this algorithm can sidestep iterative optimization schemes, and optimizes general utilities directly at test-time. Across both didactic and high-dimensional experiments, we demonstrate that our method retains favorable properties of FB algorithms, while also extending their range to more general RL problems.
Reinforcement Learning via Self-Distillation
Jan 28, 2026Large language models are increasingly post-trained with reinforcement learning in verifiable domains such as code and math. Yet, current methods for reinforcement learning with verifiable rewards (RLVR) learn only from a scalar outcome reward per attempt, creating a severe credit-assignment bottleneck. Many verifiable environments actually provide rich textual feedback, such as runtime errors or judge evaluations, that explain why an attempt failed. We formalize this setting as reinforcement learning with rich feedback and introduce Self-Distillation Policy Optimization (SDPO), which converts tokenized feedback into a dense learning signal without any external teacher or explicit reward model. SDPO treats the current model conditioned on feedback as a self-teacher and distills its feedback-informed next-token predictions back into the policy. In this way, SDPO leverages the model's ability to retrospectively identify its own mistakes in-context. Across scientific reasoning, tool use, and competitive programming on LiveCodeBench v6, SDPO improves sample efficiency and final accuracy over strong RLVR baselines. Notably, SDPO also outperforms baselines in standard RLVR environments that only return scalar feedback by using successful rollouts as implicit feedback for failed attempts. Finally, applying SDPO to individual questions at test time accelerates discovery on difficult binary-reward tasks, achieving the same discovery probability as best-of-k sampling or multi-turn conversations with 3x fewer attempts.
TD-JEPA: Latent-predictive Representations for Zero-Shot Reinforcement Learning
Oct 01, 2025



Latent prediction--where agents learn by predicting their own latents--has emerged as a powerful paradigm for training general representations in machine learning. In reinforcement learning (RL), this approach has been explored to define auxiliary losses for a variety of settings, including reward-based and unsupervised RL, behavior cloning, and world modeling. While existing methods are typically limited to single-task learning, one-step prediction, or on-policy trajectory data, we show that temporal difference (TD) learning enables learning representations predictive of long-term latent dynamics across multiple policies from offline, reward-free transitions. Building on this, we introduce TD-JEPA, which leverages TD-based latent-predictive representations into unsupervised RL. TD-JEPA trains explicit state and task encoders, a policy-conditioned multi-step predictor, and a set of parameterized policies directly in latent space. This enables zero-shot optimization of any reward function at test time. Theoretically, we show that an idealized variant of TD-JEPA avoids collapse with proper initialization, and learns encoders that capture a low-rank factorization of long-term policy dynamics, while the predictor recovers their successor features in latent space. Empirically, TD-JEPA matches or outperforms state-of-the-art baselines on locomotion, navigation, and manipulation tasks across 13 datasets in ExoRL and OGBench, especially in the challenging setting of zero-shot RL from pixels.
DISCOVER: Automated Curricula for Sparse-Reward Reinforcement Learning
May 26, 2025Sparse-reward reinforcement learning (RL) can model a wide range of highly complex tasks. Solving sparse-reward tasks is RL's core premise - requiring efficient exploration coupled with long-horizon credit assignment - and overcoming these challenges is key for building self-improving agents with superhuman ability. We argue that solving complex and high-dimensional tasks requires solving simpler tasks that are relevant to the target task. In contrast, most prior work designs strategies for selecting exploratory tasks with the objective of solving any task, making exploration of challenging high-dimensional, long-horizon tasks intractable. We find that the sense of direction, necessary for effective exploration, can be extracted from existing RL algorithms, without needing any prior information. Based on this finding, we propose a method for directed sparse-reward goal-conditioned very long-horizon RL (DISCOVER), which selects exploratory goals in the direction of the target task. We connect DISCOVER to principled exploration in bandits, formally bounding the time until the target task becomes achievable in terms of the agent's initial distance to the target, but independent of the volume of the space of all tasks. Empirically, we perform a thorough evaluation in high-dimensional environments. We find that the directed goal selection of DISCOVER solves exploration problems that are beyond the reach of prior state-of-the-art exploration methods in RL.
Problem Space Transformations for Generalisation in Behavioural Cloning
Nov 06, 2024



The combination of behavioural cloning and neural networks has driven significant progress in robotic manipulation. As these algorithms may require a large number of demonstrations for each task of interest, they remain fundamentally inefficient in complex scenarios. This issue is aggravated when the system is treated as a black-box, ignoring its physical properties. This work characterises widespread properties of robotic manipulation, such as pose equivariance and locality. We empirically demonstrate that transformations arising from each of these properties allow neural policies trained with behavioural cloning to better generalise to out-of-distribution problem instances.
Zero-Shot Offline Imitation Learning via Optimal Transport
Oct 11, 2024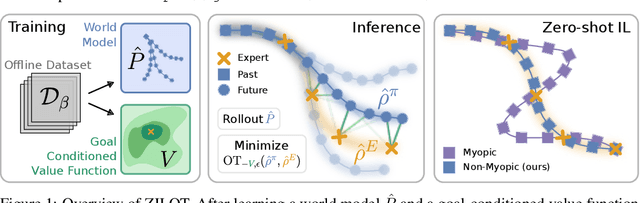
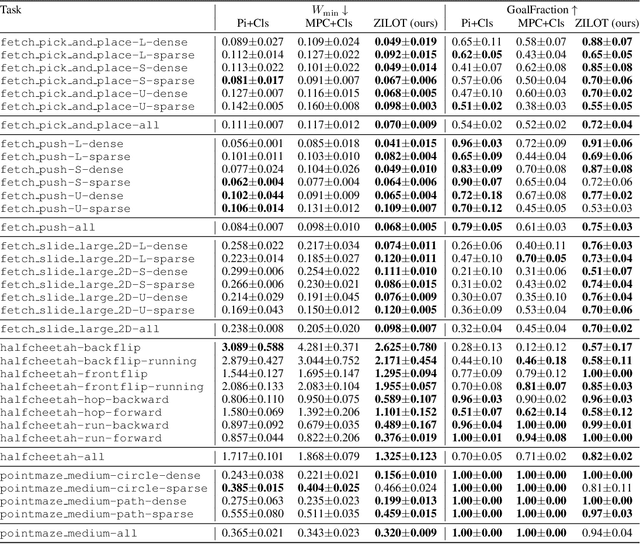
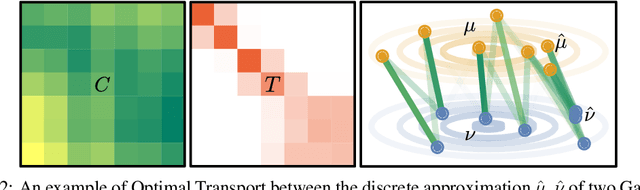
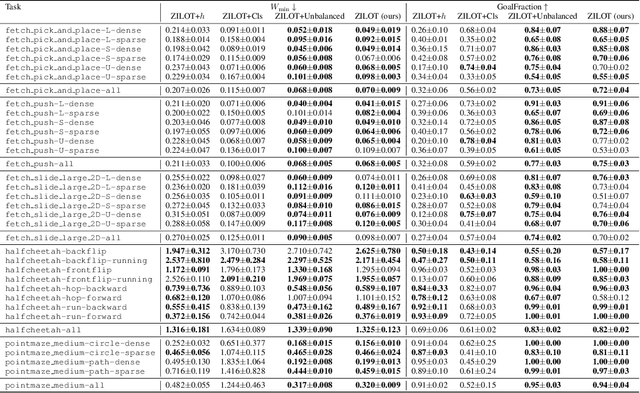
Zero-shot imitation learning algorithms hold the promise of reproducing unseen behavior from as little as a single demonstration at test time. Existing practical approaches view the expert demonstration as a sequence of goals, enabling imitation with a high-level goal selector, and a low-level goal-conditioned policy. However, this framework can suffer from myopic behavior: the agent's immediate actions towards achieving individual goals may undermine long-term objectives. We introduce a novel method that mitigates this issue by directly optimizing the occupancy matching objective that is intrinsic to imitation learning. We propose to lift a goal-conditioned value function to a distance between occupancies, which are in turn approximated via a learned world model. The resulting method can learn from offline, suboptimal data, and is capable of non-myopic, zero-shot imitation, as we demonstrate in complex, continuous benchmarks.
Active Fine-Tuning of Generalist Policies
Oct 07, 2024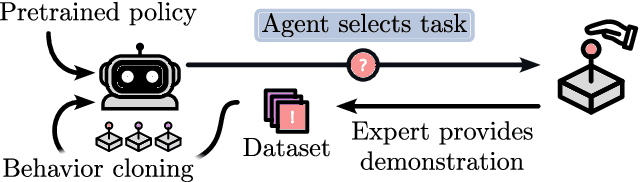
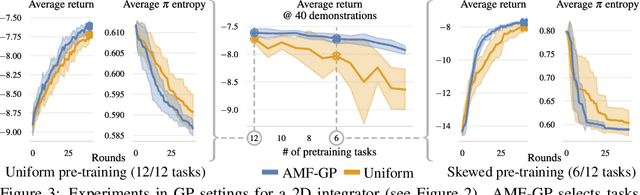
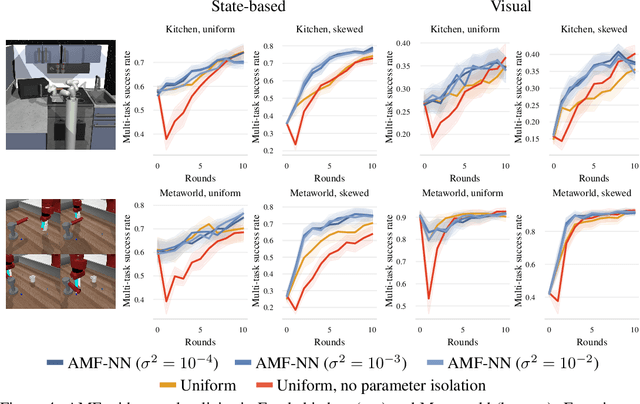
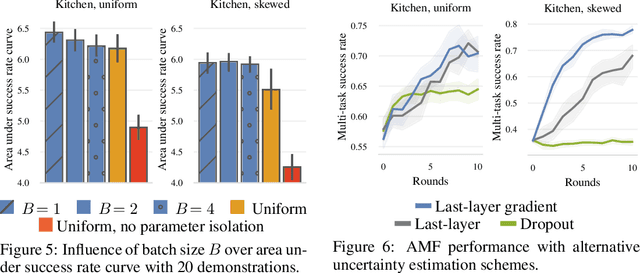
Pre-trained generalist policies are rapidly gaining relevance in robot learning due to their promise of fast adaptation to novel, in-domain tasks. This adaptation often relies on collecting new demonstrations for a specific task of interest and applying imitation learning algorithms, such as behavioral cloning. However, as soon as several tasks need to be learned, we must decide which tasks should be demonstrated and how often? We study this multi-task problem and explore an interactive framework in which the agent adaptively selects the tasks to be demonstrated. We propose AMF (Active Multi-task Fine-tuning), an algorithm to maximize multi-task policy performance under a limited demonstration budget by collecting demonstrations yielding the largest information gain on the expert policy. We derive performance guarantees for AMF under regularity assumptions and demonstrate its empirical effectiveness to efficiently fine-tune neural policies in complex and high-dimensional environments.
Directed Exploration in Reinforcement Learning from Linear Temporal Logic
Aug 18, 2024



Linear temporal logic (LTL) is a powerful language for task specification in reinforcement learning, as it allows describing objectives beyond the expressivity of conventional discounted return formulations. Nonetheless, recent works have shown that LTL formulas can be translated into a variable rewarding and discounting scheme, whose optimization produces a policy maximizing a lower bound on the probability of formula satisfaction. However, the synthesized reward signal remains fundamentally sparse, making exploration challenging. We aim to overcome this limitation, which can prevent current algorithms from scaling beyond low-dimensional, short-horizon problems. We show how better exploration can be achieved by further leveraging the LTL specification and casting its corresponding Limit Deterministic B\"uchi Automaton (LDBA) as a Markov reward process, thus enabling a form of high-level value estimation. By taking a Bayesian perspective over LDBA dynamics and proposing a suitable prior distribution, we show that the values estimated through this procedure can be treated as a shaping potential and mapped to informative intrinsic rewards. Empirically, we demonstrate applications of our method from tabular settings to high-dimensional continuous systems, which have so far represented a significant challenge for LTL-based reinforcement learning algorithms.
Causal Action Influence Aware Counterfactual Data Augmentation
May 29, 2024



Offline data are both valuable and practical resources for teaching robots complex behaviors. Ideally, learning agents should not be constrained by the scarcity of available demonstrations, but rather generalize beyond the training distribution. However, the complexity of real-world scenarios typically requires huge amounts of data to prevent neural network policies from picking up on spurious correlations and learning non-causal relationships. We propose CAIAC, a data augmentation method that can create feasible synthetic transitions from a fixed dataset without having access to online environment interactions. By utilizing principled methods for quantifying causal influence, we are able to perform counterfactual reasoning by swapping $\it{action}$-unaffected parts of the state-space between independent trajectories in the dataset. We empirically show that this leads to a substantial increase in robustness of offline learning algorithms against distributional shift.
Goal-conditioned Offline Planning from Curious Exploration
Nov 28, 2023



Curiosity has established itself as a powerful exploration strategy in deep reinforcement learning. Notably, leveraging expected future novelty as intrinsic motivation has been shown to efficiently generate exploratory trajectories, as well as a robust dynamics model. We consider the challenge of extracting goal-conditioned behavior from the products of such unsupervised exploration techniques, without any additional environment interaction. We find that conventional goal-conditioned reinforcement learning approaches for extracting a value function and policy fall short in this difficult offline setting. By analyzing the geometry of optimal goal-conditioned value functions, we relate this issue to a specific class of estimation artifacts in learned values. In order to mitigate their occurrence, we propose to combine model-based planning over learned value landscapes with a graph-based value aggregation scheme. We show how this combination can correct both local and global artifacts, obtaining significant improvements in zero-shot goal-reaching performance across diverse simulated environments.