 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempoRL: Temporal Priors for Exploration in Off-Policy Reinforcement Learning
Paper and Code
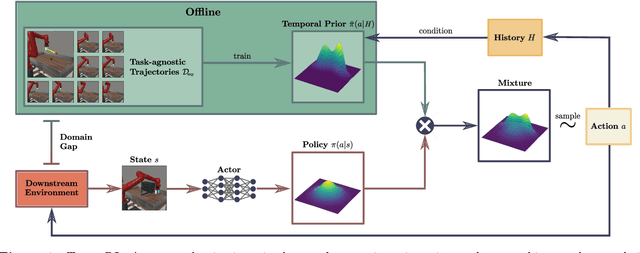

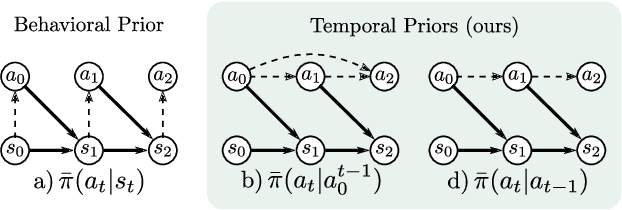

Efficient exploration is a crucial challenge in deep reinforcement learning. Several methods, such as behavioral priors, are able to leverage offline data in order to efficiently accelerate reinforcement learning on complex tasks. However, if the task at hand deviates excessively from the demonstrated task, the effectiveness of such methods is limited. In our work, we propose to learn features from offline data that are shared by a more diverse range of tasks, such as correlation between actions and directedness. Therefore, we introduce state-independent temporal priors, which directly model temporal consistency in demonstrated trajectories, and are capable of driving exploration in complex tasks, even when trained on data collected on simpler tasks. Furthermore, we introduce a novel integration scheme for action priors in off-policy reinforcement learning by dynamically sampling actions from a probabilistic mixture of policy and action prior. We compare our approach against strong baselines and provide empirical evidence that it can accelerate reinforcement learning in long-horizon continuous control tasks under sparse reward settings.