 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegressor-Guided Image Editing Regulates Emotional Response to Reduce Online Engagement
Jan 21, 2025



Emotions are known to mediate the relationship between users' content consumption and their online engagement, with heightened emotional intensity leading to increased engagement. Building on this insight, we propose three regressor-guided image editing approaches aimed at diminishing the emotional impact of images. These include (i) a parameter optimization approach based on global image transformations known to influence emotions, (ii) an optimization approach targeting the style latent space of a generative adversarial network, and (iii) a diffusion-based approach employing classifier guidance and classifier-free guidance. Our findings demonstrate that approaches can effectively alter the emotional properties of images while maintaining high visual quality. Optimization-based methods primarily adjust low-level properties like color hues and brightness, whereas the diffusion-based approach introduces semantic changes, such as altering appearance or facial expressions. Notably, results from a behavioral study reveal that only the diffusion-based approach successfully elicits changes in viewers' emotional responses while preserving high perceived image quality. In future work, we will investigate the impact of these image adaptations on internet user behavior.
WorldPose: A World Cup Dataset for Global 3D Human Pose Estimation
Jan 06, 2025We present WorldPose, a novel dataset for advancing research in multi-person global pose estimation in the wild, featuring footage from the 2022 FIFA World Cup. While previous datasets have primarily focused on local poses, often limited to a single person or in constrained, indoor settings, the infrastructure deployed for this sporting event allows access to multiple fixed and moving cameras in different stadiums. We exploit the static multi-view setup of HD cameras to recover the 3D player poses and motions with unprecedented accuracy given capture areas of more than 1.75 acres. We then leverage the captured players' motions and field markings to calibrate a moving broadcasting camera. The resulting dataset comprises more than 80 sequences with approx 2.5 million 3D poses and a total traveling distance of over 120 km. Subsequently, we conduct an in-depth analysis of the SOTA methods for global pose estimation. Our experiments demonstrate that WorldPose challenges existing multi-person techniques, supporting the potential for new research in this area and others, such as sports analysis. All pose annotations (in SMPL format), broadcasting camera parameters and footage will be released for academic research purposes.
Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models
Oct 03, 2024



Classifier-free guidance (CFG) is crucial for improving both generation quality and alignment between the input condition and final output in diffusion models. While a high guidance scale is generally required to enhance these aspects, it also causes oversaturation and unrealistic artifacts. In this paper, we revisit the CFG update rule and introduce modifications to address this issue. We first decompose the update term in CFG into parallel and orthogonal components with respect to the conditional model prediction and observe that the parallel component primarily causes oversaturation, while the orthogonal component enhances image quality. Accordingly, we propose down-weighting the parallel component to achieve high-quality generations without oversaturation. Additionally, we draw a connection between CFG and gradient ascent and introduce a new rescaling and momentum method for the CFG update rule based on this insight. Our approach, termed adaptive projected guidance (APG), retains the quality-boosting advantages of CFG while enabling the use of higher guidance scales without oversaturation. APG is easy to implement and introduces practically no additional computational overhead to the sampling process. Through extensive experiments, we demonstrate that APG is compatible with various conditional diffusion models and samplers, leading to improved FID, recall, and saturation scores while maintaining precision comparable to CFG, making our method a superior plug-and-play alternative to standard classifier-free guidance.
Cafca: High-quality Novel View Synthesis of Expressive Faces from Casual Few-shot Captures
Oct 01, 2024
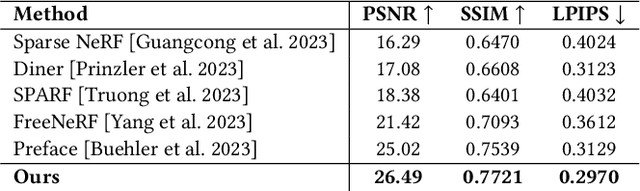

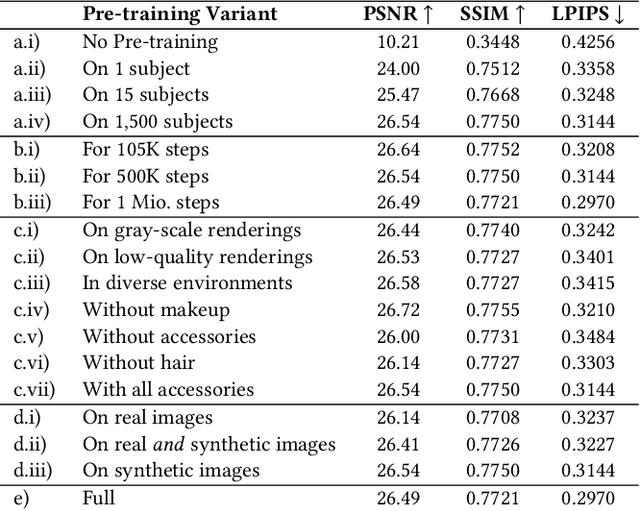
Volumetric modeling and neural radiance field representations have revolutionized 3D face capture and photorealistic novel view synthesis. However, these methods often require hundreds of multi-view input images and are thus inapplicable to cases with less than a handful of inputs. We present a novel volumetric prior on human faces that allows for high-fidelity expressive face modeling from as few as three input views captured in the wild. Our key insight is that an implicit prior trained on synthetic data alone can generalize to extremely challenging real-world identities and expressions and render novel views with fine idiosyncratic details like wrinkles and eyelashes. We leverage a 3D Morphable Face Model to synthesize a large training set, rendering each identity with different expressions, hair, clothing, and other assets. We then train a conditional Neural Radiance Field prior on this synthetic dataset and, at inference time, fine-tune the model on a very sparse set of real images of a single subject. On average, the fine-tuning requires only three inputs to cross the synthetic-to-real domain gap. The resulting personalized 3D model reconstructs strong idiosyncratic facial expressions and outperforms the state-of-the-art in high-quality novel view synthesis of faces from sparse inputs in terms of perceptual and photo-metric quality.
Gaussian Garments: Reconstructing Simulation-Ready Clothing with Photorealistic Appearance from Multi-View Video
Sep 12, 2024We introduce Gaussian Garments, a novel approach for reconstructing realistic simulation-ready garment assets from multi-view videos. Our method represents garments with a combination of a 3D mesh and a Gaussian texture that encodes both the color and high-frequency surface details. This representation enables accurate registration of garment geometries to multi-view videos and helps disentangle albedo textures from lighting effects. Furthermore, we demonstrate how a pre-trained graph neural network (GNN) can be fine-tuned to replicate the real behavior of each garment. The reconstructed Gaussian Garments can be automatically combined into multi-garment outfits and animated with the fine-tuned GNN.
AvatarPose: Avatar-guided 3D Pose Estimation of Close Human Interaction from Sparse Multi-view Videos
Aug 04, 2024



Despite progress in human motion capture, existing multi-view methods often face challenges in estimating the 3D pose and shape of multiple closely interacting people. This difficulty arises from reliance on accurate 2D joint estimations, which are hard to obtain due to occlusions and body contact when people are in close interaction. To address this, we propose a novel method leveraging the personalized implicit neural avatar of each individual as a prior, which significantly improves the robustness and precision of this challenging pose estimation task. Concretely, the avatars are efficiently reconstructed via layered volume rendering from sparse multi-view videos. The reconstructed avatar prior allows for the direct optimization of 3D poses based on color and silhouette rendering loss, bypassing the issues associated with noisy 2D detections. To handle interpenetration, we propose a collision loss on the overlapping shape regions of avatars to add penetration constraints. Moreover, both 3D poses and avatars are optimized in an alternating manner. Our experimental results demonstrate state-of-the-art performance on several public datasets.
No Training, No Problem: Rethinking Classifier-Free Guidance for Diffusion Models
Jul 02, 2024



Classifier-free guidance (CFG) has become the standard method for enhancing the quality of conditional diffusion models. However, employing CFG requires either training an unconditional model alongside the main diffusion model or modifying the training procedure by periodically inserting a null condition. There is also no clear extension of CFG to unconditional models. In this paper, we revisit the core principles of CFG and introduce a new method, independent condition guidance (ICG), which provides the benefits of CFG without the need for any special training procedures. Our approach streamlines the training process of conditional diffusion models and can also be applied during inference on any pre-trained conditional model. Additionally, by leveraging the time-step information encoded in all diffusion networks, we propose an extension of CFG, called time-step guidance (TSG), which can be applied to any diffusion model, including unconditional ones. Our guidance techniques are easy to implement and have the same sampling cost as CFG. Through extensive experiments, we demonstrate that ICG matches the performance of standard CFG across various conditional diffusion models. Moreover, we show that TSG improves generation quality in a manner similar to CFG, without relying on any conditional information.
EgoGaussian: Dynamic Scene Understanding from Egocentric Video with 3D Gaussian Splatting
Jun 28, 2024



Human activities are inherently complex, and even simple household tasks involve numerous object interactions. To better understand these activities and behaviors, it is crucial to model their dynamic interactions with the environment. The recent availability of affordable head-mounted cameras and egocentric data offers a more accessible and efficient means to understand dynamic human-object interactions in 3D environments. However, most existing methods for human activity modeling either focus on reconstructing 3D models of hand-object or human-scene interactions or on mapping 3D scenes, neglecting dynamic interactions with objects. The few existing solutions often require inputs from multiple sources, including multi-camera setups, depth-sensing cameras, or kinesthetic sensors. To this end, we introduce EgoGaussian, the first method capable of simultaneously reconstructing 3D scenes and dynamically tracking 3D object motion from RGB egocentric input alone. We leverage the uniquely discrete nature of Gaussian Splatting and segment dynamic interactions from the background. Our approach employs a clip-level online learning pipeline that leverages the dynamic nature of human activities, allowing us to reconstruct the temporal evolution of the scene in chronological order and track rigid object motion. Additionally, our method automatically segments object and background Gaussians, providing 3D representations for both static scenes and dynamic objects. EgoGaussian outperforms previous NeRF and Dynamic Gaussian methods in challenging in-the-wild videos and we also qualitatively demonstrate the high quality of the reconstructed models.
RILe: Reinforced Imitation Learning
Jun 12, 2024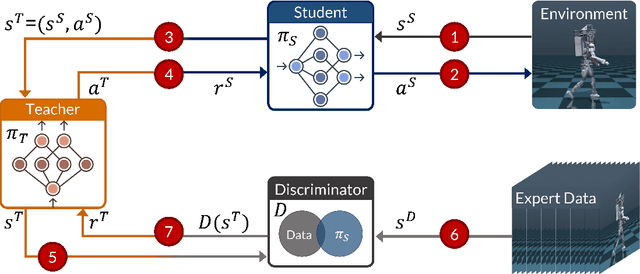
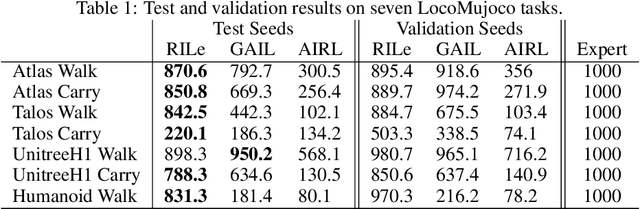
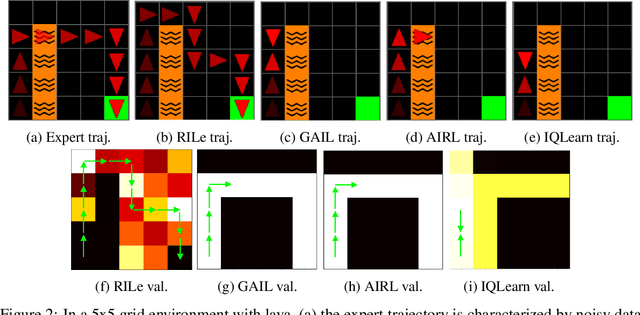
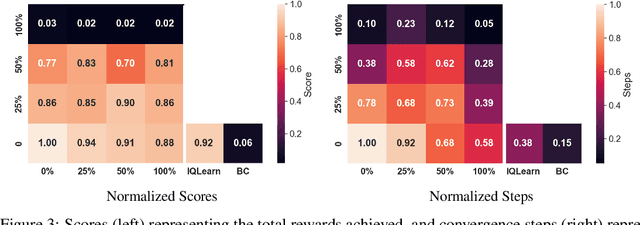
Reinforcement Learning has achieved significant success in generating complex behavior but often requires extensive reward function engineering. Adversarial variants of Imitation Learning and Inverse Reinforcement Learning offer an alternative by learning policies from expert demonstrations via a discriminator. Employing discriminators increases their data- and computational efficiency over the standard approaches; however, results in sensitivity to imperfections in expert data. We propose RILe, a teacher-student system that achieves both robustness to imperfect data and efficiency. In RILe, the student learns an action policy while the teacher dynamically adjusts a reward function based on the student's performance and its alignment with expert demonstrations. By tailoring the reward function to both performance of the student and expert similarity, our system reduces dependence on the discriminator and, hence, increases robustness against data imperfections. Experiments show that RILe outperforms existing methods by 2x in settings with limited or noisy expert data.
MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild
Jun 03, 2024



We present MultiPly, a novel framework to reconstruct multiple people in 3D from monocular in-the-wild videos. Reconstructing multiple individuals moving and interacting naturally from monocular in-the-wild videos poses a challenging task. Addressing it necessitates precise pixel-level disentanglement of individuals without any prior knowledge about the subjects. Moreover, it requires recovering intricate and complete 3D human shapes from short video sequences, intensifying the level of difficulty. To tackle these challenges, we first define a layered neural representation for the entire scene, composited by individual human and background models. We learn the layered neural representation from videos via our layer-wise differentiable volume rendering. This learning process is further enhanced by our hybrid instance segmentation approach which combines the self-supervised 3D segmentation and the promptable 2D segmentation module, yielding reliable instance segmentation supervision even under close human interaction. A confidence-guided optimization formulation is introduced to optimize the human poses and shape/appearance alternately. We incorporate effective objectives to refine human poses via photometric information and impose physically plausible constraints on human dynamics, leading to temporally consistent 3D reconstructions with high fidelity. The evaluation of our method shows the superiority over prior art on publicly available datasets and in-the-wild videos.