 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiGS: History-Guided Sampling for Plug-and-Play Enhancement of Diffusion Models
Sep 26, 2025



While diffusion models have made remarkable progress in image generation, their outputs can still appear unrealistic and lack fine details, especially when using fewer number of neural function evaluations (NFEs) or lower guidance scales. To address this issue, we propose a novel momentum-based sampling technique, termed history-guided sampling (HiGS), which enhances quality and efficiency of diffusion sampling by integrating recent model predictions into each inference step. Specifically, HiGS leverages the difference between the current prediction and a weighted average of past predictions to steer the sampling process toward more realistic outputs with better details and structure. Our approach introduces practically no additional computation and integrates seamlessly into existing diffusion frameworks, requiring neither extra training nor fine-tuning. Extensive experiments show that HiGS consistently improves image quality across diverse models and architectures and under varying sampling budgets and guidance scales. Moreover, using a pretrained SiT model, HiGS achieves a new state-of-the-art FID of 1.61 for unguided ImageNet generation at 256$\times$256 with only 30 sampling steps (instead of the standard 250). We thus present HiGS as a plug-and-play enhancement to standard diffusion sampling that enables faster generation with higher fidelity.
Guidance in the Frequency Domain Enables High-Fidelity Sampling at Low CFG Scales
Jun 24, 2025Classifier-free guidance (CFG) has become an essential component of modern conditional diffusion models. Although highly effective in practice, the underlying mechanisms by which CFG enhances quality, detail, and prompt alignment are not fully understood. We present a novel perspective on CFG by analyzing its effects in the frequency domain, showing that low and high frequencies have distinct impacts on generation quality. Specifically, low-frequency guidance governs global structure and condition alignment, while high-frequency guidance mainly enhances visual fidelity. However, applying a uniform scale across all frequencies -- as is done in standard CFG -- leads to oversaturation and reduced diversity at high scales and degraded visual quality at low scales. Based on these insights, we propose frequency-decoupled guidance (FDG), an effective approach that decomposes CFG into low- and high-frequency components and applies separate guidance strengths to each component. FDG improves image quality at low guidance scales and avoids the drawbacks of high CFG scales by design. Through extensive experiments across multiple datasets and models, we demonstrate that FDG consistently enhances sample fidelity while preserving diversity, leading to improved FID and recall compared to CFG, establishing our method as a plug-and-play alternative to standard classifier-free guidance.
Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models
Oct 03, 2024



Classifier-free guidance (CFG) is crucial for improving both generation quality and alignment between the input condition and final output in diffusion models. While a high guidance scale is generally required to enhance these aspects, it also causes oversaturation and unrealistic artifacts. In this paper, we revisit the CFG update rule and introduce modifications to address this issue. We first decompose the update term in CFG into parallel and orthogonal components with respect to the conditional model prediction and observe that the parallel component primarily causes oversaturation, while the orthogonal component enhances image quality. Accordingly, we propose down-weighting the parallel component to achieve high-quality generations without oversaturation. Additionally, we draw a connection between CFG and gradient ascent and introduce a new rescaling and momentum method for the CFG update rule based on this insight. Our approach, termed adaptive projected guidance (APG), retains the quality-boosting advantages of CFG while enabling the use of higher guidance scales without oversaturation. APG is easy to implement and introduces practically no additional computational overhead to the sampling process. Through extensive experiments, we demonstrate that APG is compatible with various conditional diffusion models and samplers, leading to improved FID, recall, and saturation scores while maintaining precision comparable to CFG, making our method a superior plug-and-play alternative to standard classifier-free guidance.
Reenact Anything: Semantic Video Motion Transfer Using Motion-Textual Inversion
Aug 01, 2024


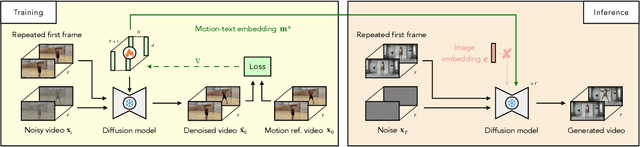
Recent years have seen a tremendous improvement in the quality of video generation and editing approaches. While several techniques focus on editing appearance, few address motion. Current approaches using text, trajectories, or bounding boxes are limited to simple motions, so we specify motions with a single motion reference video instead. We further propose to use a pre-trained image-to-video model rather than a text-to-video model. This approach allows us to preserve the exact appearance and position of a target object or scene and helps disentangle appearance from motion. Our method, called motion-textual inversion, leverages our observation that image-to-video models extract appearance mainly from the (latent) image input, while the text/image embedding injected via cross-attention predominantly controls motion. We thus represent motion using text/image embedding tokens. By operating on an inflated motion-text embedding containing multiple text/image embedding tokens per frame, we achieve a high temporal motion granularity. Once optimized on the motion reference video, this embedding can be applied to various target images to generate videos with semantically similar motions. Our approach does not require spatial alignment between the motion reference video and target image, generalizes across various domains, and can be applied to various tasks such as full-body and face reenactment, as well as controlling the motion of inanimate objects and the camera. We empirically demonstrate the effectiveness of our method in the semantic video motion transfer task, significantly outperforming existing methods in this context.
No Training, No Problem: Rethinking Classifier-Free Guidance for Diffusion Models
Jul 02, 2024



Classifier-free guidance (CFG) has become the standard method for enhancing the quality of conditional diffusion models. However, employing CFG requires either training an unconditional model alongside the main diffusion model or modifying the training procedure by periodically inserting a null condition. There is also no clear extension of CFG to unconditional models. In this paper, we revisit the core principles of CFG and introduce a new method, independent condition guidance (ICG), which provides the benefits of CFG without the need for any special training procedures. Our approach streamlines the training process of conditional diffusion models and can also be applied during inference on any pre-trained conditional model. Additionally, by leveraging the time-step information encoded in all diffusion networks, we propose an extension of CFG, called time-step guidance (TSG), which can be applied to any diffusion model, including unconditional ones. Our guidance techniques are easy to implement and have the same sampling cost as CFG. Through extensive experiments, we demonstrate that ICG matches the performance of standard CFG across various conditional diffusion models. Moreover, we show that TSG improves generation quality in a manner similar to CFG, without relying on any conditional information.
LiteVAE: Lightweight and Efficient Variational Autoencoders for Latent Diffusion Models
May 23, 2024Advances in latent diffusion models (LDMs) have revolutionized high-resolution image generation, but the design space of the autoencoder that is central to these systems remains underexplored. In this paper, we introduce LiteVAE, a family of autoencoders for LDMs that leverage the 2D discrete wavelet transform to enhance scalability and computational efficiency over standard variational autoencoders (VAEs) with no sacrifice in output quality. We also investigate the training methodologies and the decoder architecture of LiteVAE and propose several enhancements that improve the training dynamics and reconstruction quality. Our base LiteVAE model matches the quality of the established VAEs in current LDMs with a six-fold reduction in encoder parameters, leading to faster training and lower GPU memory requirements, while our larger model outperforms VAEs of comparable complexity across all evaluated metrics (rFID, LPIPS, PSNR, and SSIM).
CADS: Unleashing the Diversity of Diffusion Models through Condition-Annealed Sampling
Oct 26, 2023While conditional diffusion models are known to have good coverage of the data distribution, they still face limitations in output diversity, particularly when sampled with a high classifier-free guidance scale for optimal image quality or when trained on small datasets. We attribute this problem to the role of the conditioning signal in inference and offer an improved sampling strategy for diffusion models that can increase generation diversity, especially at high guidance scales, with minimal loss of sample quality. Our sampling strategy anneals the conditioning signal by adding scheduled, monotonically decreasing Gaussian noise to the conditioning vector during inference to balance diversity and condition alignment. Our Condition-Annealed Diffusion Sampler (CADS) can be used with any pretrained model and sampling algorithm, and we show that it boosts the diversity of diffusion models in various conditional generation tasks. Further, using an existing pretrained diffusion model, CADS achieves a new state-of-the-art FID of 1.70 and 2.31 for class-conditional ImageNet generation at 256$\times$256 and 512$\times$512 respectively.
The Score-Difference Flow for Implicit Generative Modeling
Apr 25, 2023Implicit generative modeling (IGM) aims to produce samples of synthetic data matching the characteristics of a target data distribution. Recent work (e.g. score-matching networks, diffusion models) has approached the IGM problem from the perspective of pushing synthetic source data toward the target distribution via dynamical perturbations or flows in the ambient space. We introduce the score difference (SD) between arbitrary target and source distributions as a flow that optimally reduces the Kullback-Leibler divergence between them while also solving the Schr\"odinger bridge problem. We apply the SD flow to convenient proxy distributions, which are aligned if and only if the original distributions are aligned. We demonstrate the formal equivalence of this formulation to denoising diffusion models under certain conditions. However, unlike diffusion models, SD flow places no restrictions on the prior distribution. We also show that the training of generative adversarial networks includes a hidden data-optimization sub-problem, which induces the SD flow under certain choices of loss function when the discriminator is optimal. As a result, the SD flow provides a theoretical link between model classes that, taken together, address all three challenges of the "generative modeling trilemma": high sample quality, mode coverage, and fast sampling.
Controllable Inversion of Black-Box Face-Recognition Models via Diffusion
Mar 23, 2023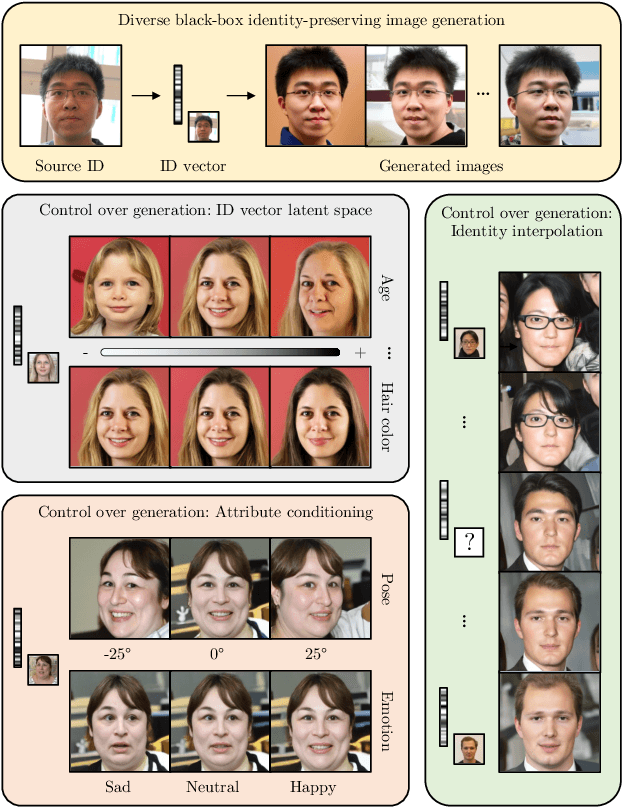
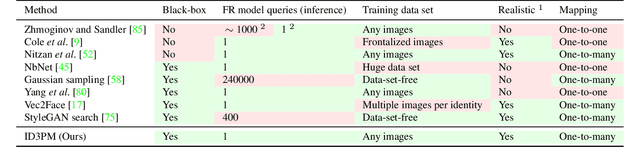
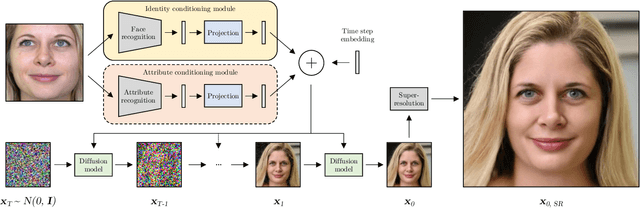

Face recognition models embed a face image into a low-dimensional identity vector containing abstract encodings of identity-specific facial features that allow individuals to be distinguished from one another. We tackle the challenging task of inverting the latent space of pre-trained face recognition models without full model access (i.e. black-box setting). A variety of methods have been proposed in literature for this task, but they have serious shortcomings such as a lack of realistic outputs, long inference times, and strong requirements for the data set and accessibility of the face recognition model. Through an analysis of the black-box inversion problem, we show that the conditional diffusion model loss naturally emerges and that we can effectively sample from the inverse distribution even without an identity-specific loss. Our method, named identity denoising diffusion probabilistic model (ID3PM), leverages the stochastic nature of the denoising diffusion process to produce high-quality, identity-preserving face images with various backgrounds, lighting, poses, and expressions. We demonstrate state-of-the-art performance in terms of identity preservation and diversity both qualitatively and quantitatively. Our method is the first black-box face recognition model inversion method that offers intuitive control over the generation process and does not suffer from any of the common shortcomings from competing methods.
The Hidden Tasks of Generative Adversarial Networks: An Alternative Perspective on GAN Training
Jan 29, 2021

We present an alternative perspective on the training of generative adversarial networks (GANs), showing that the training step for a GAN generator decomposes into two implicit sub-problems. In the first, the discriminator provides new target data to the generator in the form of "inverse examples" produced by approximately inverting classifier labels. In the second, these examples are used as targets to update the generator via least-squares regression, regardless of the main loss specified to train the network. We experimentally validate our main theoretical result and discuss implications for alternative training methods that are made possible by making these sub-problems explicit. We also introduce a simple representation of inductive bias in networks, which we apply to describing the generator's output relative to its regression targets.