 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastGHA: Generalized Few-Shot 3D Gaussian Head Avatars with Real-Time Animation
Jan 20, 2026Despite recent progress in 3D Gaussian-based head avatar modeling, efficiently generating high fidelity avatars remains a challenge. Current methods typically rely on extensive multi-view capture setups or monocular videos with per-identity optimization during inference, limiting their scalability and ease of use on unseen subjects. To overcome these efficiency drawbacks, we propose \OURS, a feed-forward method to generate high-quality Gaussian head avatars from only a few input images while supporting real-time animation. Our approach directly learns a per-pixel Gaussian representation from the input images, and aggregates multi-view information using a transformer-based encoder that fuses image features from both DINOv3 and Stable Diffusion VAE. For real-time animation, we extend the explicit Gaussian representations with per-Gaussian features and introduce a lightweight MLP-based dynamic network to predict 3D Gaussian deformations from expression codes. Furthermore, to enhance geometric smoothness of the 3D head, we employ point maps from a pre-trained large reconstruction model as geometry supervision. Experiments show that our approach significantly outperforms existing methods in both rendering quality and inference efficiency, while supporting real-time dynamic avatar animation.
Reenact Anything: Semantic Video Motion Transfer Using Motion-Textual Inversion
Aug 01, 2024


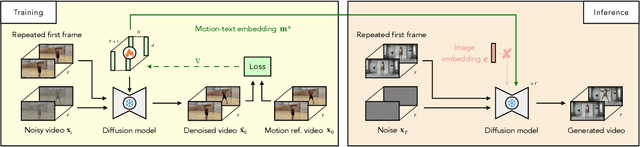
Recent years have seen a tremendous improvement in the quality of video generation and editing approaches. While several techniques focus on editing appearance, few address motion. Current approaches using text, trajectories, or bounding boxes are limited to simple motions, so we specify motions with a single motion reference video instead. We further propose to use a pre-trained image-to-video model rather than a text-to-video model. This approach allows us to preserve the exact appearance and position of a target object or scene and helps disentangle appearance from motion. Our method, called motion-textual inversion, leverages our observation that image-to-video models extract appearance mainly from the (latent) image input, while the text/image embedding injected via cross-attention predominantly controls motion. We thus represent motion using text/image embedding tokens. By operating on an inflated motion-text embedding containing multiple text/image embedding tokens per frame, we achieve a high temporal motion granularity. Once optimized on the motion reference video, this embedding can be applied to various target images to generate videos with semantically similar motions. Our approach does not require spatial alignment between the motion reference video and target image, generalizes across various domains, and can be applied to various tasks such as full-body and face reenactment, as well as controlling the motion of inanimate objects and the camera. We empirically demonstrate the effectiveness of our method in the semantic video motion transfer task, significantly outperforming existing methods in this context.
No Training, No Problem: Rethinking Classifier-Free Guidance for Diffusion Models
Jul 02, 2024



Classifier-free guidance (CFG) has become the standard method for enhancing the quality of conditional diffusion models. However, employing CFG requires either training an unconditional model alongside the main diffusion model or modifying the training procedure by periodically inserting a null condition. There is also no clear extension of CFG to unconditional models. In this paper, we revisit the core principles of CFG and introduce a new method, independent condition guidance (ICG), which provides the benefits of CFG without the need for any special training procedures. Our approach streamlines the training process of conditional diffusion models and can also be applied during inference on any pre-trained conditional model. Additionally, by leveraging the time-step information encoded in all diffusion networks, we propose an extension of CFG, called time-step guidance (TSG), which can be applied to any diffusion model, including unconditional ones. Our guidance techniques are easy to implement and have the same sampling cost as CFG. Through extensive experiments, we demonstrate that ICG matches the performance of standard CFG across various conditional diffusion models. Moreover, we show that TSG improves generation quality in a manner similar to CFG, without relying on any conditional information.
Controllable Inversion of Black-Box Face-Recognition Models via Diffusion
Mar 23, 2023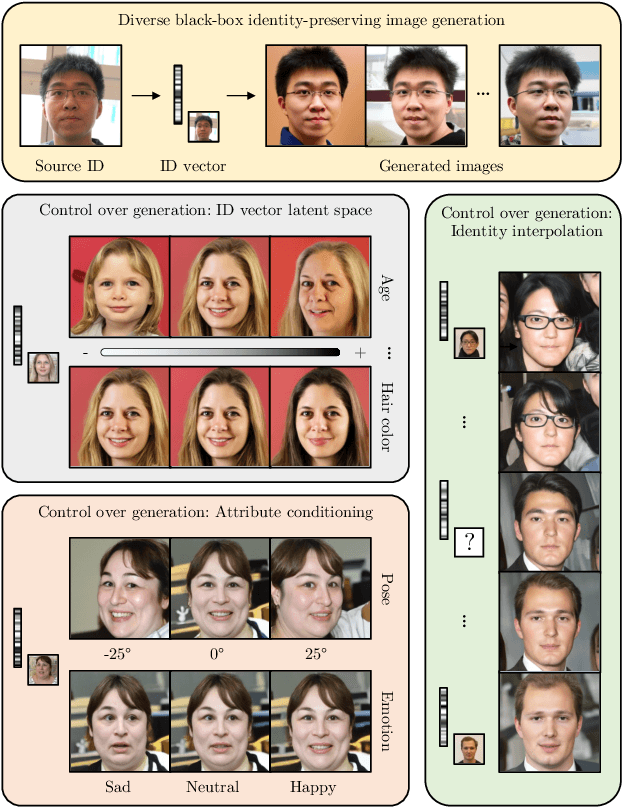
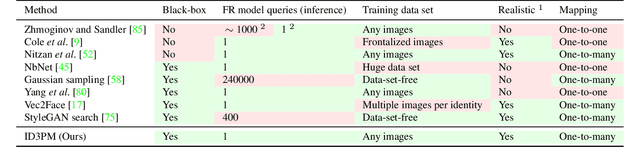
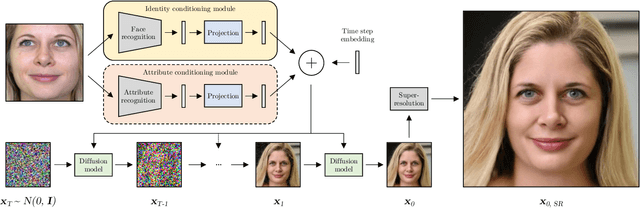

Face recognition models embed a face image into a low-dimensional identity vector containing abstract encodings of identity-specific facial features that allow individuals to be distinguished from one another. We tackle the challenging task of inverting the latent space of pre-trained face recognition models without full model access (i.e. black-box setting). A variety of methods have been proposed in literature for this task, but they have serious shortcomings such as a lack of realistic outputs, long inference times, and strong requirements for the data set and accessibility of the face recognition model. Through an analysis of the black-box inversion problem, we show that the conditional diffusion model loss naturally emerges and that we can effectively sample from the inverse distribution even without an identity-specific loss. Our method, named identity denoising diffusion probabilistic model (ID3PM), leverages the stochastic nature of the denoising diffusion process to produce high-quality, identity-preserving face images with various backgrounds, lighting, poses, and expressions. We demonstrate state-of-the-art performance in terms of identity preservation and diversity both qualitatively and quantitatively. Our method is the first black-box face recognition model inversion method that offers intuitive control over the generation process and does not suffer from any of the common shortcomings from competing methods.