 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-Adaptive Generative Compression with Spatially Varying Diffusion Models
Apr 01, 2026Generative image codecs aim to optimize perceptual quality, producing realistic and detailed reconstructions. However, they often overlook a key property of human vision: our tendency to focus on particular aspects of a visual scene (e.g., salient objects) while giving less importance to other regions. An ideal perceptual codec should be able to exploit this property by allocating more representational capacity to perceptually important areas. To this end, we propose a region-adaptive diffusion-based image codec that supports non-uniform bit allocation within an image. We design a novel spatially varying diffusion model capable of denoising varying amounts of noise per pixel according to arbitrary importance maps. We further identify that these maps can serve as effective priors on the latent representation, and integrate them into our entropy model, improving rate-distortion performance. Built on these contributions, our spatially-adaptive diffusion-based codec outperforms state-of-the-art ROI-controllable baselines in both full-image and ROI-masked perceptual quality.
RenderFlow: Single-Step Neural Rendering via Flow Matching
Jan 11, 2026Conventional physically based rendering (PBR) pipelines generate photorealistic images through computationally intensive light transport simulations. Although recent deep learning approaches leverage diffusion model priors with geometry buffers (G-buffers) to produce visually compelling results without explicit scene geometry or light simulation, they remain constrained by two major limitations. First, the iterative nature of the diffusion process introduces substantial latency. Second, the inherent stochasticity of these generative models compromises physical accuracy and temporal consistency. In response to these challenges, we propose a novel, end-to-end, deterministic, single-step neural rendering framework, RenderFlow, built upon a flow matching paradigm. To further strengthen both rendering quality and generalization, we propose an efficient and effective module for sparse keyframe guidance. Our method significantly accelerates the rendering process and, by optionally incorporating sparsely rendered keyframes as guidance, enhances both the physical plausibility and overall visual quality of the output. The resulting pipeline achieves near real-time performance with photorealistic rendering quality, effectively bridging the gap between the efficiency of modern generative models and the precision of traditional physically based rendering. Furthermore, we demonstrate the versatility of our framework by introducing a lightweight, adapter-based module that efficiently repurposes the pretrained forward model for the inverse rendering task of intrinsic decomposition.
StableDPT: Temporal Stable Monocular Video Depth Estimation
Jan 06, 2026Applying single image Monocular Depth Estimation (MDE) models to video sequences introduces significant temporal instability and flickering artifacts. We propose a novel approach that adapts any state-of-the-art image-based (depth) estimation model for video processing by integrating a new temporal module - trainable on a single GPU in a few days. Our architecture StableDPT builds upon an off-the-shelf Vision Transformer (ViT) encoder and enhances the Dense Prediction Transformer (DPT) head. The core of our contribution lies in the temporal layers within the head, which use an efficient cross-attention mechanism to integrate information from keyframes sampled across the entire video sequence. This allows the model to capture global context and inter-frame relationships leading to more accurate and temporally stable depth predictions. Furthermore, we propose a novel inference strategy for processing videos of arbitrary length avoiding the scale misalignment and redundant computations associated with overlapping windows used in other methods. Evaluations on multiple benchmark datasets demonstrate improved temporal consistency, competitive state-of-the-art performance and on top 2x faster processing in real-world scenarios.
Guardians of the Hair: Rescuing Soft Boundaries in Depth, Stereo, and Novel Views
Jan 06, 2026Soft boundaries, like thin hairs, are commonly observed in natural and computer-generated imagery, but they remain challenging for 3D vision due to the ambiguous mixing of foreground and background cues. This paper introduces Guardians of the Hair (HairGuard), a framework designed to recover fine-grained soft boundary details in 3D vision tasks. Specifically, we first propose a novel data curation pipeline that leverages image matting datasets for training and design a depth fixer network to automatically identify soft boundary regions. With a gated residual module, the depth fixer refines depth precisely around soft boundaries while maintaining global depth quality, allowing plug-and-play integration with state-of-the-art depth models. For view synthesis, we perform depth-based forward warping to retain high-fidelity textures, followed by a generative scene painter that fills disoccluded regions and eliminates redundant background artifacts within soft boundaries. Finally, a color fuser adaptively combines warped and inpainted results to produce novel views with consistent geometry and fine-grained details. Extensive experiments demonstrate that HairGuard achieves state-of-the-art performance across monocular depth estimation, stereo image/video conversion, and novel view synthesis, with significant improvements in soft boundary regions.
Efficient Correlation Volume Sampling for Ultra-High-Resolution Optical Flow Estimation
May 22, 2025Recent optical flow estimation methods often employ local cost sampling from a dense all-pairs correlation volume. This results in quadratic computational and memory complexity in the number of pixels. Although an alternative memory-efficient implementation with on-demand cost computation exists, this is slower in practice and therefore prior methods typically process images at reduced resolutions, missing fine-grained details. To address this, we propose a more efficient implementation of the all-pairs correlation volume sampling, still matching the exact mathematical operator as defined by RAFT. Our approach outperforms on-demand sampling by up to 90% while maintaining low memory usage, and performs on par with the default implementation with up to 95% lower memory usage. As cost sampling makes up a significant portion of the overall runtime, this can translate to up to 50% savings for the total end-to-end model inference in memory-constrained environments. Our evaluation of existing methods includes an 8K ultra-high-resolution dataset and an additional inference-time modification of the recent SEA-RAFT method. With this, we achieve state-of-the-art results at high resolutions both in accuracy and efficiency.
Bridging the Gap between Gaussian Diffusion Models and Universal Quantization for Image Compression
Apr 03, 2025Generative neural image compression supports data representation at extremely low bitrate, synthesizing details at the client and consistently producing highly realistic images. By leveraging the similarities between quantization error and additive noise, diffusion-based generative image compression codecs can be built using a latent diffusion model to "denoise" the artifacts introduced by quantization. However, we identify three critical gaps in previous approaches following this paradigm (namely, the noise level, noise type, and discretization gaps) that result in the quantized data falling out of the data distribution known by the diffusion model. In this work, we propose a novel quantization-based forward diffusion process with theoretical foundations that tackles all three aforementioned gaps. We achieve this through universal quantization with a carefully tailored quantization schedule and a diffusion model trained with uniform noise. Compared to previous work, our proposal produces consistently realistic and detailed reconstructions, even at very low bitrates. In such a regime, we achieve the best rate-distortion-realism performance, outperforming previous related works.
High-Fidelity Novel View Synthesis via Splatting-Guided Diffusion
Feb 18, 2025



Despite recent advances in Novel View Synthesis (NVS), generating high-fidelity views from single or sparse observations remains a significant challenge. Existing splatting-based approaches often produce distorted geometry due to splatting errors. While diffusion-based methods leverage rich 3D priors to achieve improved geometry, they often suffer from texture hallucination. In this paper, we introduce SplatDiff, a pixel-splatting-guided video diffusion model designed to synthesize high-fidelity novel views from a single image. Specifically, we propose an aligned synthesis strategy for precise control of target viewpoints and geometry-consistent view synthesis. To mitigate texture hallucination, we design a texture bridge module that enables high-fidelity texture generation through adaptive feature fusion. In this manner, SplatDiff leverages the strengths of splatting and diffusion to generate novel views with consistent geometry and high-fidelity details. Extensive experiments verify the state-of-the-art performance of SplatDiff in single-view NVS. Additionally, without extra training, SplatDiff shows remarkable zero-shot performance across diverse tasks, including sparse-view NVS and stereo video conversion.
Reenact Anything: Semantic Video Motion Transfer Using Motion-Textual Inversion
Aug 01, 2024


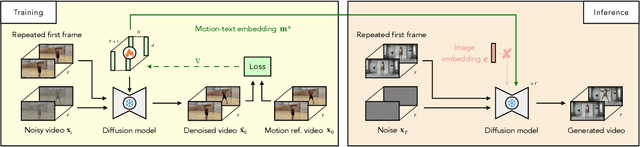
Recent years have seen a tremendous improvement in the quality of video generation and editing approaches. While several techniques focus on editing appearance, few address motion. Current approaches using text, trajectories, or bounding boxes are limited to simple motions, so we specify motions with a single motion reference video instead. We further propose to use a pre-trained image-to-video model rather than a text-to-video model. This approach allows us to preserve the exact appearance and position of a target object or scene and helps disentangle appearance from motion. Our method, called motion-textual inversion, leverages our observation that image-to-video models extract appearance mainly from the (latent) image input, while the text/image embedding injected via cross-attention predominantly controls motion. We thus represent motion using text/image embedding tokens. By operating on an inflated motion-text embedding containing multiple text/image embedding tokens per frame, we achieve a high temporal motion granularity. Once optimized on the motion reference video, this embedding can be applied to various target images to generate videos with semantically similar motions. Our approach does not require spatial alignment between the motion reference video and target image, generalizes across various domains, and can be applied to various tasks such as full-body and face reenactment, as well as controlling the motion of inanimate objects and the camera. We empirically demonstrate the effectiveness of our method in the semantic video motion transfer task, significantly outperforming existing methods in this context.
BetterDepth: Plug-and-Play Diffusion Refiner for Zero-Shot Monocular Depth Estimation
Jul 25, 2024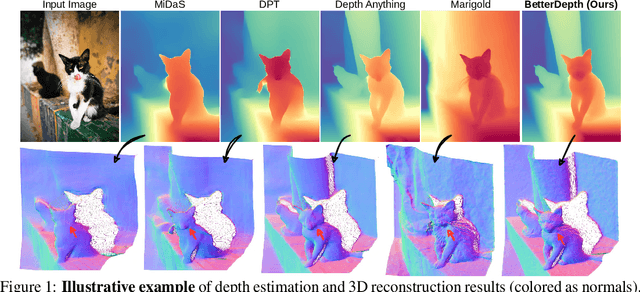

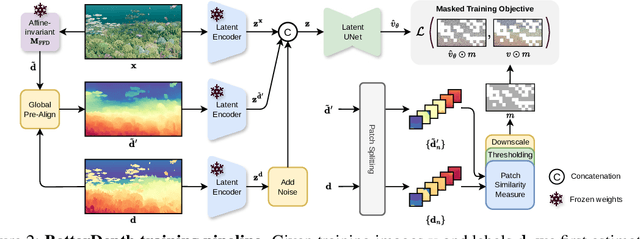
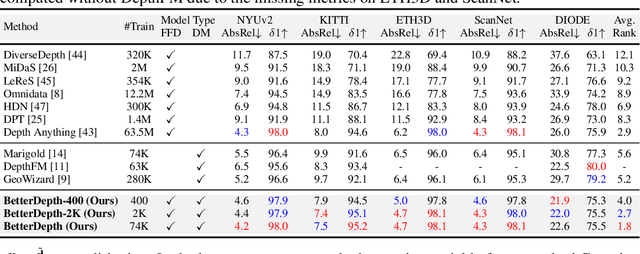
By training over large-scale datasets, zero-shot monocular depth estimation (MDE) methods show robust performance in the wild but often suffer from insufficiently precise details. Although recent diffusion-based MDE approaches exhibit appealing detail extraction ability, they still struggle in geometrically challenging scenes due to the difficulty of gaining robust geometric priors from diverse datasets. To leverage the complementary merits of both worlds, we propose BetterDepth to efficiently achieve geometrically correct affine-invariant MDE performance while capturing fine-grained details. Specifically, BetterDepth is a conditional diffusion-based refiner that takes the prediction from pre-trained MDE models as depth conditioning, in which the global depth context is well-captured, and iteratively refines details based on the input image. For the training of such a refiner, we propose global pre-alignment and local patch masking methods to ensure the faithfulness of BetterDepth to depth conditioning while learning to capture fine-grained scene details. By efficient training on small-scale synthetic datasets, BetterDepth achieves state-of-the-art zero-shot MDE performance on diverse public datasets and in-the-wild scenes. Moreover, BetterDepth can improve the performance of other MDE models in a plug-and-play manner without additional re-training.
CoARF: Controllable 3D Artistic Style Transfer for Radiance Fields
Apr 23, 2024Creating artistic 3D scenes can be time-consuming and requires specialized knowledge. To address this, recent works such as ARF, use a radiance field-based approach with style constraints to generate 3D scenes that resemble a style image provided by the user. However, these methods lack fine-grained control over the resulting scenes. In this paper, we introduce Controllable Artistic Radiance Fields (CoARF), a novel algorithm for controllable 3D scene stylization. CoARF enables style transfer for specified objects, compositional 3D style transfer and semantic-aware style transfer. We achieve controllability using segmentation masks with different label-dependent loss functions. We also propose a semantic-aware nearest neighbor matching algorithm to improve the style transfer quality. Our extensive experiments demonstrate that CoARF provides user-specified controllability of style transfer and superior style transfer quality with more precise feature matching.