 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiV-INR: Extreme Low-Bitrate Diffusion Video Compression with INR Conditioning
Apr 09, 2026We present a perceptually-driven video compression framework integrating implicit neural representations (INRs) and pre-trained video diffusion models to address the extremely low bitrate regime (<0.05 bpp). Our approach exploits the complementary strengths of INRs, which provide a compact video representation, and diffusion models, which offer rich generative priors learned from large-scale datasets. The INR-based conditioning replaces traditional intra-coded keyframes with bit-efficient neural representations trained to estimate latent features and guide the diffusion process. Our joint optimization of INR weights and parameter-efficient adapters for diffusion models allows the model to learn reliable conditioning signals while encoding video-specific information with minimal parameter overhead. Our experiments on UVG, MCL-JCV, and JVET Class-B benchmarks demonstrate substantial improvements in perceptual metrics (LPIPS, DISTS, and FID) at extremely low bitrates, including improvements on BD-LPIPS up to 0.214 and BD-FID up to 91.14 relative to HEVC, while also outperforming VVC and previous strong state-of-the-art neural and INR-only video codecs. Moreover, our analysis shows that INR-conditioned diffusion-based video compression first composes the scene layout and object identities before refining textural accuracy, exposing the semantic-to-visual hierarchy that enables perceptually faithful compression at extremely low bitrates.
Region-Adaptive Generative Compression with Spatially Varying Diffusion Models
Apr 01, 2026Generative image codecs aim to optimize perceptual quality, producing realistic and detailed reconstructions. However, they often overlook a key property of human vision: our tendency to focus on particular aspects of a visual scene (e.g., salient objects) while giving less importance to other regions. An ideal perceptual codec should be able to exploit this property by allocating more representational capacity to perceptually important areas. To this end, we propose a region-adaptive diffusion-based image codec that supports non-uniform bit allocation within an image. We design a novel spatially varying diffusion model capable of denoising varying amounts of noise per pixel according to arbitrary importance maps. We further identify that these maps can serve as effective priors on the latent representation, and integrate them into our entropy model, improving rate-distortion performance. Built on these contributions, our spatially-adaptive diffusion-based codec outperforms state-of-the-art ROI-controllable baselines in both full-image and ROI-masked perceptual quality.
Bridging the Gap between Gaussian Diffusion Models and Universal Quantization for Image Compression
Apr 03, 2025Generative neural image compression supports data representation at extremely low bitrate, synthesizing details at the client and consistently producing highly realistic images. By leveraging the similarities between quantization error and additive noise, diffusion-based generative image compression codecs can be built using a latent diffusion model to "denoise" the artifacts introduced by quantization. However, we identify three critical gaps in previous approaches following this paradigm (namely, the noise level, noise type, and discretization gaps) that result in the quantized data falling out of the data distribution known by the diffusion model. In this work, we propose a novel quantization-based forward diffusion process with theoretical foundations that tackles all three aforementioned gaps. We achieve this through universal quantization with a carefully tailored quantization schedule and a diffusion model trained with uniform noise. Compared to previous work, our proposal produces consistently realistic and detailed reconstructions, even at very low bitrates. In such a regime, we achieve the best rate-distortion-realism performance, outperforming previous related works.
Lossy Image Compression with Foundation Diffusion Models
Apr 12, 2024



Incorporating diffusion models in the image compression domain has the potential to produce realistic and detailed reconstructions, especially at extremely low bitrates. Previous methods focus on using diffusion models as expressive decoders robust to quantization errors in the conditioning signals, yet achieving competitive results in this manner requires costly training of the diffusion model and long inference times due to the iterative generative process. In this work we formulate the removal of quantization error as a denoising task, using diffusion to recover lost information in the transmitted image latent. Our approach allows us to perform less than 10\% of the full diffusion generative process and requires no architectural changes to the diffusion model, enabling the use of foundation models as a strong prior without additional fine tuning of the backbone. Our proposed codec outperforms previous methods in quantitative realism metrics, and we verify that our reconstructions are qualitatively preferred by end users, even when other methods use twice the bitrate.
Microdosing: Knowledge Distillation for GAN based Compression
Jan 07, 2022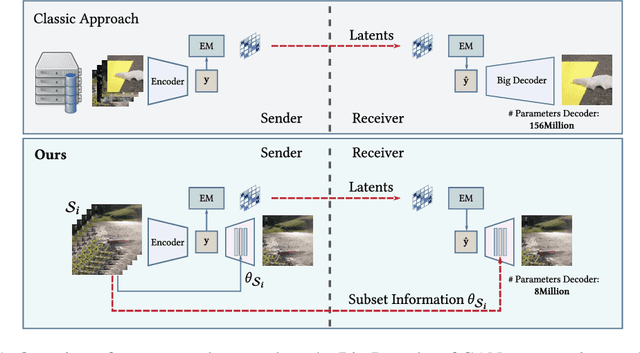
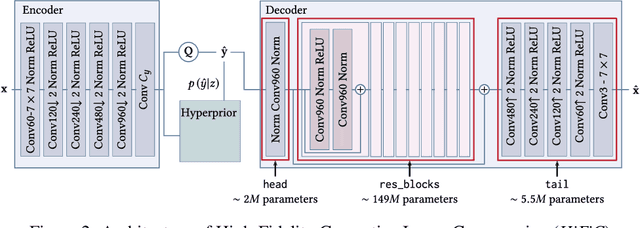
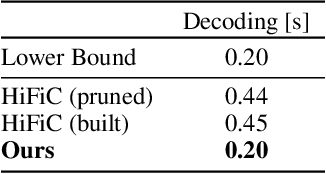

Recently, significant progress has been made in learned image and video compression. In particular the usage of Generative Adversarial Networks has lead to impressive results in the low bit rate regime. However, the model size remains an important issue in current state-of-the-art proposals and existing solutions require significant computation effort on the decoding side. This limits their usage in realistic scenarios and the extension to video compression. In this paper, we demonstrate how to leverage knowledge distillation to obtain equally capable image decoders at a fraction of the original number of parameters. We investigate several aspects of our solution including sequence specialization with side information for image coding. Finally, we also show how to transfer the obtained benefits into the setting of video compression. Overall, this allows us to reduce the model size by a factor of 20 and to achieve 50% reduction in decoding time.
Bridging the Gap between Semantics and Multimedia Processing
Dec 02, 2019
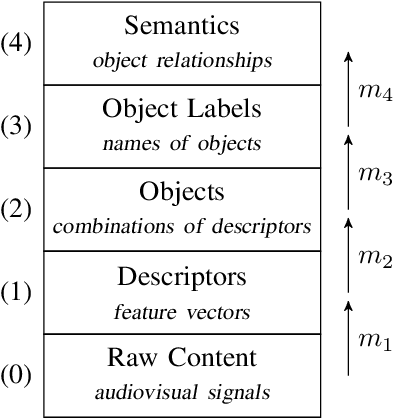
In this paper, we give an overview of the semantic gap problem in multimedia and discuss how machine learning and symbolic AI can be combined to narrow this gap. We describe the gap in terms of a classical architecture for multimedia processing and discuss a structured approach to bridge it. This approach combines machine learning (for mapping signals to objects) and symbolic AI (for linking objects to meanings). Our main goal is to raise awareness and discuss the challenges involved in this structured approach to multimedia understanding, especially in the view of the latest developments in machine learning and symbolic AI.