 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegacyAvatars: Volumetric Face Avatars For Traditional Graphics Pipelines
Jan 18, 2026We introduce a novel representation for efficient classical rendering of photorealistic 3D face avatars. Leveraging recent advances in radiance fields anchored to parametric face models, our approach achieves controllable volumetric rendering of complex facial features, including hair, skin, and eyes. At enrollment time, we learn a set of radiance manifolds in 3D space to extract an explicit layered mesh, along with appearance and warp textures. During deployment, this allows us to control and animate the face through simple linear blending and alpha compositing of textures over a static mesh. This explicit representation also enables the generated avatar to be efficiently streamed online and then rendered using classical mesh and shader-based rendering on legacy graphics platforms, eliminating the need for any custom engineering or integration.
Text To 3D Object Generation For Scalable Room Assembly
Apr 12, 2025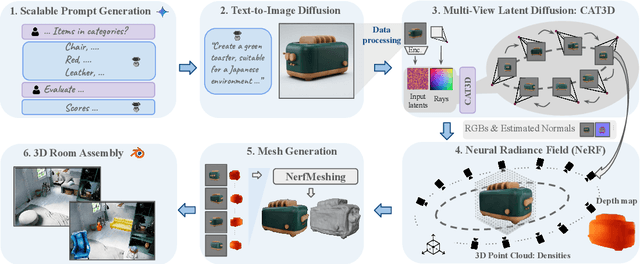



Modern machine learning models for scene understanding, such as depth estimation and object tracking, rely on large, high-quality datasets that mimic real-world deployment scenarios. To address data scarcity, we propose an end-to-end system for synthetic data generation for scalable, high-quality, and customizable 3D indoor scenes. By integrating and adapting text-to-image and multi-view diffusion models with Neural Radiance Field-based meshing, this system generates highfidelity 3D object assets from text prompts and incorporates them into pre-defined floor plans using a rendering tool. By introducing novel loss functions and training strategies into existing methods, the system supports on-demand scene generation, aiming to alleviate the scarcity of current available data, generally manually crafted by artists. This system advances the role of synthetic data in addressing machine learning training limitations, enabling more robust and generalizable models for real-world applications.
Cafca: High-quality Novel View Synthesis of Expressive Faces from Casual Few-shot Captures
Oct 01, 2024
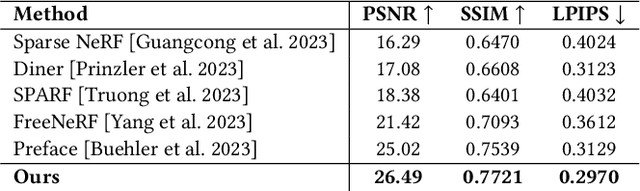

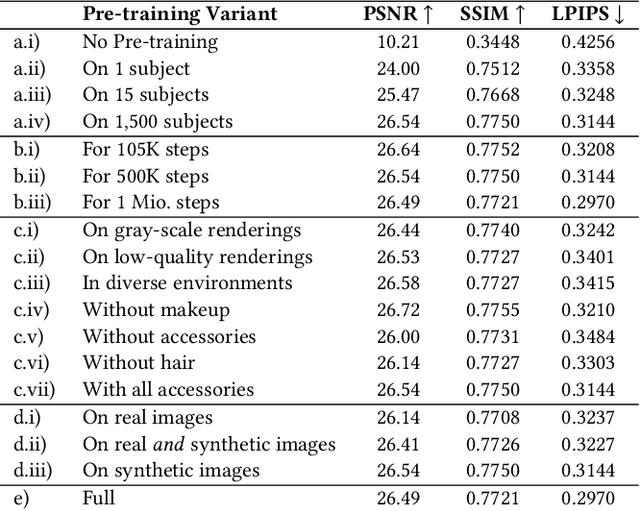
Volumetric modeling and neural radiance field representations have revolutionized 3D face capture and photorealistic novel view synthesis. However, these methods often require hundreds of multi-view input images and are thus inapplicable to cases with less than a handful of inputs. We present a novel volumetric prior on human faces that allows for high-fidelity expressive face modeling from as few as three input views captured in the wild. Our key insight is that an implicit prior trained on synthetic data alone can generalize to extremely challenging real-world identities and expressions and render novel views with fine idiosyncratic details like wrinkles and eyelashes. We leverage a 3D Morphable Face Model to synthesize a large training set, rendering each identity with different expressions, hair, clothing, and other assets. We then train a conditional Neural Radiance Field prior on this synthetic dataset and, at inference time, fine-tune the model on a very sparse set of real images of a single subject. On average, the fine-tuning requires only three inputs to cross the synthetic-to-real domain gap. The resulting personalized 3D model reconstructs strong idiosyncratic facial expressions and outperforms the state-of-the-art in high-quality novel view synthesis of faces from sparse inputs in terms of perceptual and photo-metric quality.
Preface: A Data-driven Volumetric Prior for Few-shot Ultra High-resolution Face Synthesis
Sep 28, 2023NeRFs have enabled highly realistic synthesis of human faces including complex appearance and reflectance effects of hair and skin. These methods typically require a large number of multi-view input images, making the process hardware intensive and cumbersome, limiting applicability to unconstrained settings. We propose a novel volumetric human face prior that enables the synthesis of ultra high-resolution novel views of subjects that are not part of the prior's training distribution. This prior model consists of an identity-conditioned NeRF, trained on a dataset of low-resolution multi-view images of diverse humans with known camera calibration. A simple sparse landmark-based 3D alignment of the training dataset allows our model to learn a smooth latent space of geometry and appearance despite a limited number of training identities. A high-quality volumetric representation of a novel subject can be obtained by model fitting to 2 or 3 camera views of arbitrary resolution. Importantly, our method requires as few as two views of casually captured images as input at inference time.
Microdosing: Knowledge Distillation for GAN based Compression
Jan 07, 2022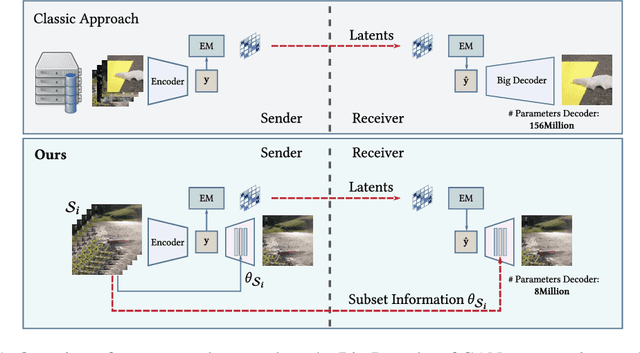
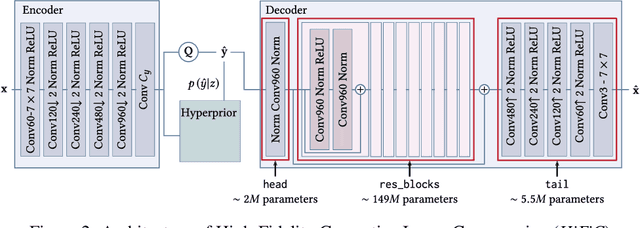
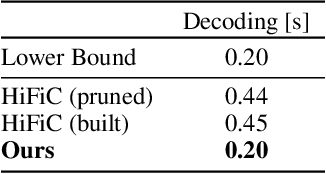

Recently, significant progress has been made in learned image and video compression. In particular the usage of Generative Adversarial Networks has lead to impressive results in the low bit rate regime. However, the model size remains an important issue in current state-of-the-art proposals and existing solutions require significant computation effort on the decoding side. This limits their usage in realistic scenarios and the extension to video compression. In this paper, we demonstrate how to leverage knowledge distillation to obtain equally capable image decoders at a fraction of the original number of parameters. We investigate several aspects of our solution including sequence specialization with side information for image coding. Finally, we also show how to transfer the obtained benefits into the setting of video compression. Overall, this allows us to reduce the model size by a factor of 20 and to achieve 50% reduction in decoding time.
Blind Image Restoration with Flow Based Priors
Sep 09, 2020



Image restoration has seen great progress in the last years thanks to the advances in deep neural networks. Most of these existing techniques are trained using full supervision with suitable image pairs to tackle a specific degradation. However, in a blind setting with unknown degradations this is not possible and a good prior remains crucial. Recently, neural network based approaches have been proposed to model such priors by leveraging either denoising autoencoders or the implicit regularization captured by the neural network structure itself. In contrast to this, we propose using normalizing flows to model the distribution of the target content and to use this as a prior in a maximum a posteriori (MAP) formulation. By expressing the MAP optimization process in the latent space through the learned bijective mapping, we are able to obtain solutions through gradient descent. To the best of our knowledge, this is the first work that explores normalizing flows as prior in image enhancement problems. Furthermore, we present experimental results for a number of different degradations on data sets varying in complexity and show competitive results when comparing with the deep image prior approach.
Lossy Image Compression with Normalizing Flows
Aug 24, 2020



Deep learning based image compression has recently witnessed exciting progress and in some cases even managed to surpass transform coding based approaches that have been established and refined over many decades. However, state-of-the-art solutions for deep image compression typically employ autoencoders which map the input to a lower dimensional latent space and thus irreversibly discard information already before quantization. Due to that, they inherently limit the range of quality levels that can be covered. In contrast, traditional approaches in image compression allow for a larger range of quality levels. Interestingly, they employ an invertible transformation before performing the quantization step which explicitly discards information. Inspired by this, we propose a deep image compression method that is able to go from low bit-rates to near lossless quality by leveraging normalizing flows to learn a bijective mapping from the image space to a latent representation. In addition to this, we demonstrate further advantages unique to our solution, such as the ability to maintain constant quality results through re-encoding, even when performed multiple times. To the best of our knowledge, this is the first work to explore the opportunities for leveraging normalizing flows for lossy image compression.
Disentangled Dynamic Representations from Unordered Data
Dec 10, 2018



We present a deep generative model that learns disentangled static and dynamic representations of data from unordered input. Our approach exploits regularities in sequential data that exist regardless of the order in which the data is viewed. The result of our factorized graphical model is a well-organized and coherent latent space for data dynamics. We demonstrate our method on several synthetic dynamic datasets and real video data featuring various facial expressions and head poses.
Unsupervised Deep Representations for Learning Audience Facial Behaviors
May 10, 2018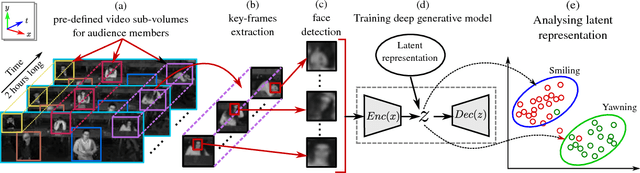
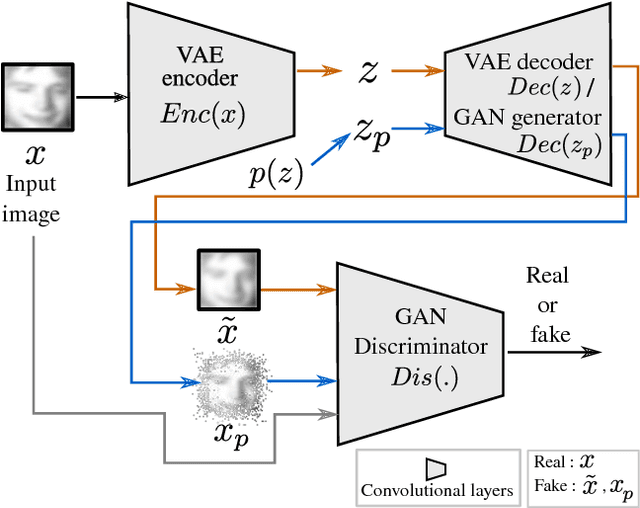

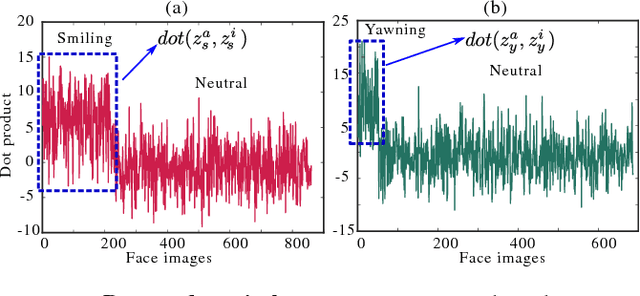
In this paper, we present an unsupervised learning approach for analyzing facial behavior based on a deep generative model combined with a convolutional neural network (CNN). We jointly train a variational auto-encoder (VAE) and a generative adversarial network (GAN) to learn a powerful latent representation from footage of audiences viewing feature-length movies. We show that the learned latent representation successfully encodes meaningful signatures of behaviors related to audience engagement (smiling & laughing) and disengagement (yawning). Our results provide a proof of concept for a more general methodology for annotating hard-to-label multimedia data featuring sparse examples of signals of interest.