 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicrodosing: Knowledge Distillation for GAN based Compression
Jan 07, 2022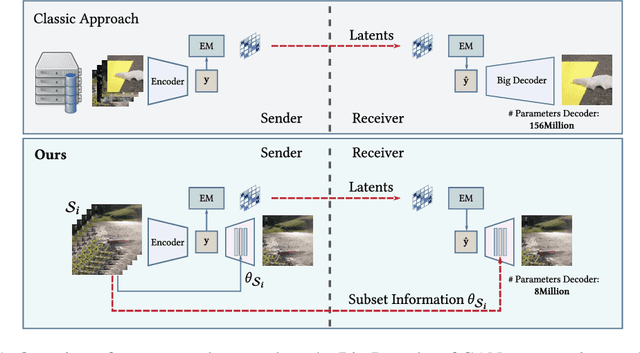
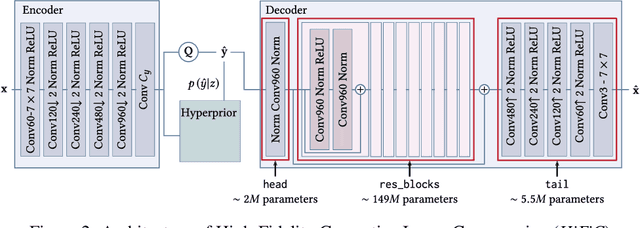
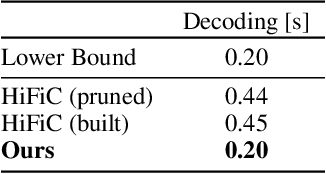

Recently, significant progress has been made in learned image and video compression. In particular the usage of Generative Adversarial Networks has lead to impressive results in the low bit rate regime. However, the model size remains an important issue in current state-of-the-art proposals and existing solutions require significant computation effort on the decoding side. This limits their usage in realistic scenarios and the extension to video compression. In this paper, we demonstrate how to leverage knowledge distillation to obtain equally capable image decoders at a fraction of the original number of parameters. We investigate several aspects of our solution including sequence specialization with side information for image coding. Finally, we also show how to transfer the obtained benefits into the setting of video compression. Overall, this allows us to reduce the model size by a factor of 20 and to achieve 50% reduction in decoding time.
Blind Image Restoration with Flow Based Priors
Sep 09, 2020



Image restoration has seen great progress in the last years thanks to the advances in deep neural networks. Most of these existing techniques are trained using full supervision with suitable image pairs to tackle a specific degradation. However, in a blind setting with unknown degradations this is not possible and a good prior remains crucial. Recently, neural network based approaches have been proposed to model such priors by leveraging either denoising autoencoders or the implicit regularization captured by the neural network structure itself. In contrast to this, we propose using normalizing flows to model the distribution of the target content and to use this as a prior in a maximum a posteriori (MAP) formulation. By expressing the MAP optimization process in the latent space through the learned bijective mapping, we are able to obtain solutions through gradient descent. To the best of our knowledge, this is the first work that explores normalizing flows as prior in image enhancement problems. Furthermore, we present experimental results for a number of different degradations on data sets varying in complexity and show competitive results when comparing with the deep image prior approach.
Lossy Image Compression with Normalizing Flows
Aug 24, 2020



Deep learning based image compression has recently witnessed exciting progress and in some cases even managed to surpass transform coding based approaches that have been established and refined over many decades. However, state-of-the-art solutions for deep image compression typically employ autoencoders which map the input to a lower dimensional latent space and thus irreversibly discard information already before quantization. Due to that, they inherently limit the range of quality levels that can be covered. In contrast, traditional approaches in image compression allow for a larger range of quality levels. Interestingly, they employ an invertible transformation before performing the quantization step which explicitly discards information. Inspired by this, we propose a deep image compression method that is able to go from low bit-rates to near lossless quality by leveraging normalizing flows to learn a bijective mapping from the image space to a latent representation. In addition to this, we demonstrate further advantages unique to our solution, such as the ability to maintain constant quality results through re-encoding, even when performed multiple times. To the best of our knowledge, this is the first work to explore the opportunities for leveraging normalizing flows for lossy image compression.
Content Adaptive Optimization for Neural Image Compression
Jun 05, 2019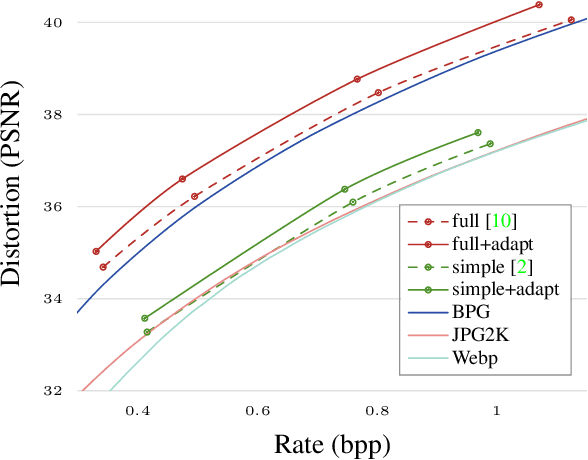

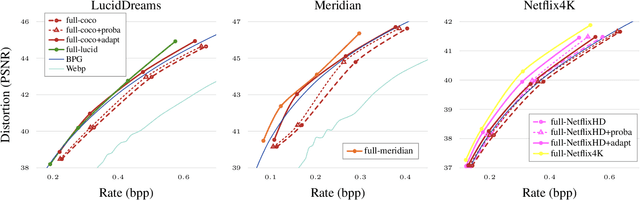
The field of neural image compression has witnessed exciting progress as recently proposed architectures already surpass the established transform coding based approaches. While, so far, research has mainly focused on architecture and model improvements, in this work we explore content adaptive optimization. To this end, we introduce an iterative procedure which adapts the latent representation to the specific content we wish to compress while keeping the parameters of the network and the predictive model fixed. Our experiments show that this allows for an overall increase in rate-distortion performance, independently of the specific architecture used. Furthermore, we also evaluate this strategy in the context of adapting a pretrained network to other content that is different in visual appearance or resolution. Here, our experiments show that our adaptation strategy can largely close the gap as compared to models specifically trained for the given content while having the benefit that no additional data in the form of model parameter updates has to be transmitted.
Disentangled Dynamic Representations from Unordered Data
Dec 10, 2018



We present a deep generative model that learns disentangled static and dynamic representations of data from unordered input. Our approach exploits regularities in sequential data that exist regardless of the order in which the data is viewed. The result of our factorized graphical model is a well-organized and coherent latent space for data dynamics. We demonstrate our method on several synthetic dynamic datasets and real video data featuring various facial expressions and head poses.
Deep Video Color Propagation
Aug 09, 2018
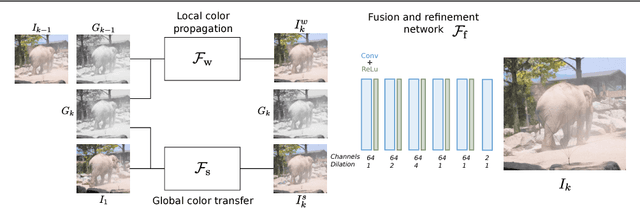
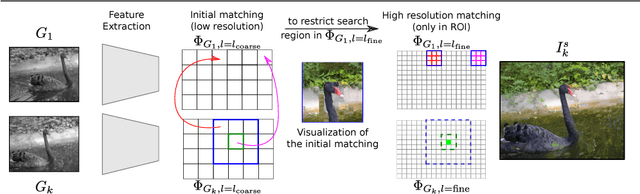

Traditional approaches for color propagation in videos rely on some form of matching between consecutive video frames. Using appearance descriptors, colors are then propagated both spatially and temporally. These methods, however, are computationally expensive and do not take advantage of semantic information of the scene. In this work we propose a deep learning framework for color propagation that combines a local strategy, to propagate colors frame-by-frame ensuring temporal stability, and a global strategy, using semantics for color propagation within a longer range. Our evaluation shows the superiority of our strategy over existing video and image color propagation methods as well as neural photo-realistic style transfer approaches.
On Regularized Losses for Weakly-supervised CNN Segmentation
Apr 10, 2018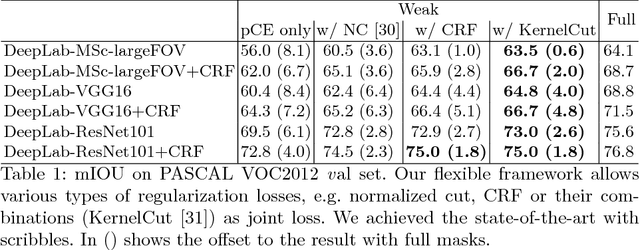
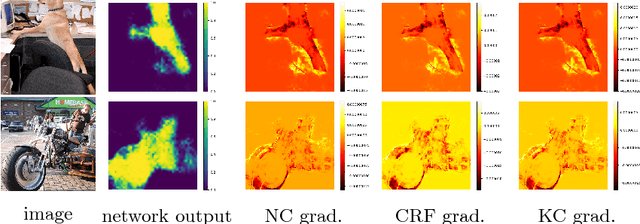
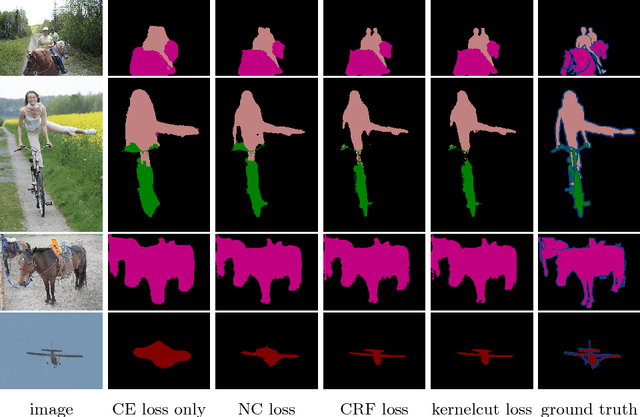
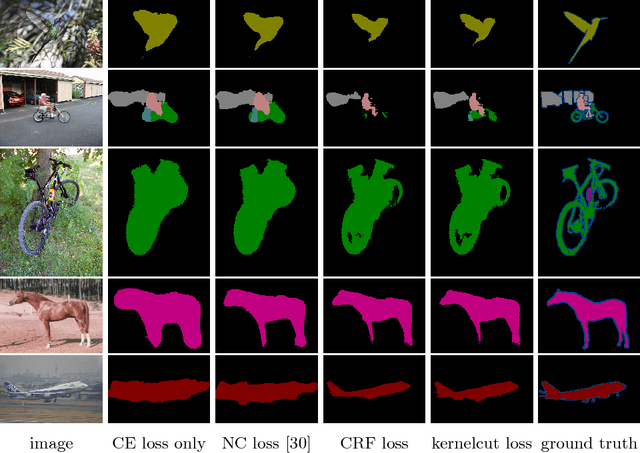
Minimization of regularized losses is a principled approach to weak supervision well-established in deep learning, in general. However, it is largely overlooked in semantic segmentation currently dominated by methods mimicking full supervision via "fake" fully-labeled training masks (proposals) generated from available partial input. To obtain such full masks the typical methods explicitly use standard regularization techniques for "shallow" segmentation, e.g. graph cuts or dense CRFs. In contrast, we integrate such standard regularizers directly into the loss functions over partial input. This approach simplifies weakly-supervised training by avoiding extra MRF/CRF inference steps or layers explicitly generating full masks, while improving both the quality and efficiency of training. This paper proposes and experimentally compares different losses integrating MRF/CRF regularization terms. We juxtapose our regularized losses with earlier proposal-generation methods using explicit regularization steps or layers. Our approach achieves state-of-the-art accuracy in semantic segmentation with near full-supervision quality.
Normalized Cut Loss for Weakly-supervised CNN Segmentation
Apr 04, 2018
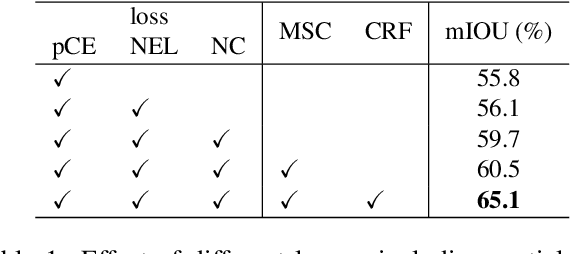
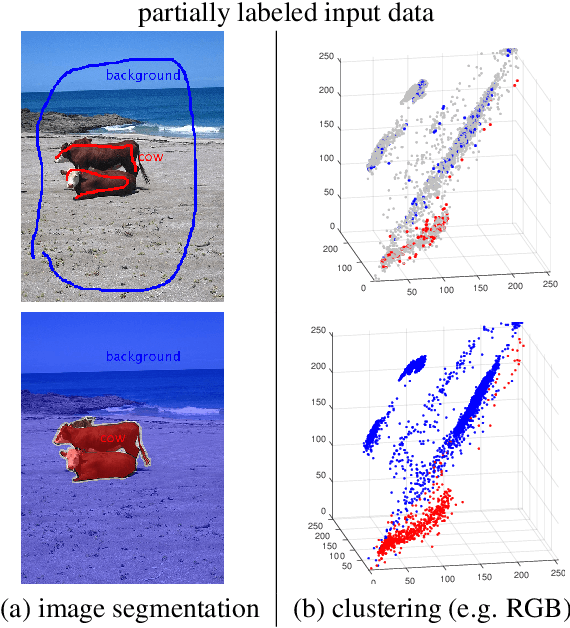
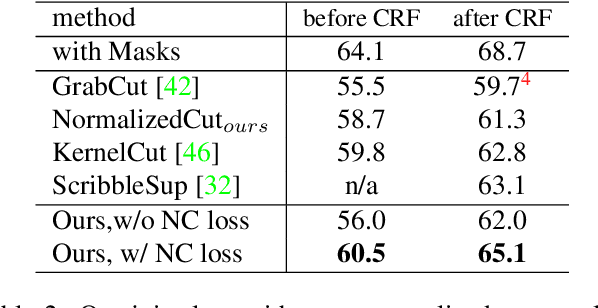
Most recent semantic segmentation methods train deep convolutional neural networks with fully annotated masks requiring pixel-accuracy for good quality training. Common weakly-supervised approaches generate full masks from partial input (e.g. scribbles or seeds) using standard interactive segmentation methods as preprocessing. But, errors in such masks result in poorer training since standard loss functions (e.g. cross-entropy) do not distinguish seeds from potentially mislabeled other pixels. Inspired by the general ideas in semi-supervised learning, we address these problems via a new principled loss function evaluating network output with criteria standard in "shallow" segmentation, e.g. normalized cut. Unlike prior work, the cross entropy part of our loss evaluates only seeds where labels are known while normalized cut softly evaluates consistency of all pixels. We focus on normalized cut loss where dense Gaussian kernel is efficiently implemented in linear time by fast Bilateral filtering. Our normalized cut loss approach to segmentation brings the quality of weakly-supervised training significantly closer to fully supervised methods.
PhaseNet for Video Frame Interpolation
Apr 03, 2018
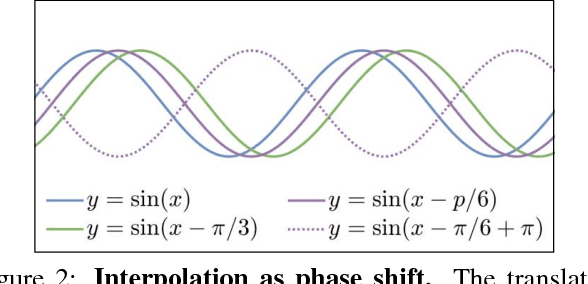
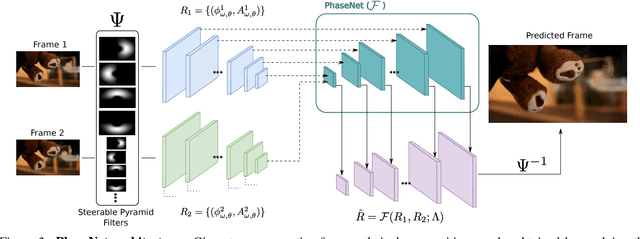
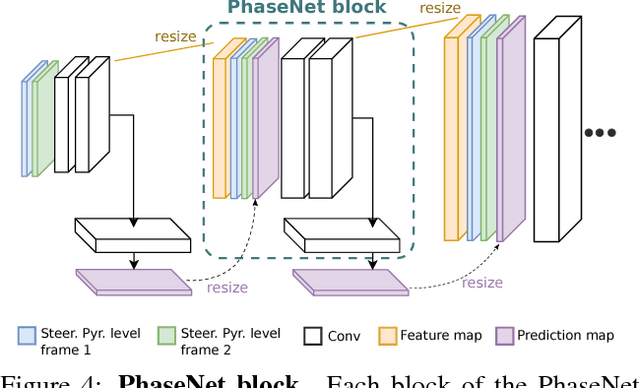
Most approaches for video frame interpolation require accurate dense correspondences to synthesize an in-between frame. Therefore, they do not perform well in challenging scenarios with e.g. lighting changes or motion blur. Recent deep learning approaches that rely on kernels to represent motion can only alleviate these problems to some extent. In those cases, methods that use a per-pixel phase-based motion representation have been shown to work well. However, they are only applicable for a limited amount of motion. We propose a new approach, PhaseNet, that is designed to robustly handle challenging scenarios while also coping with larger motion. Our approach consists of a neural network decoder that directly estimates the phase decomposition of the intermediate frame. We show that this is superior to the hand-crafted heuristics previously used in phase-based methods and also compares favorably to recent deep learning based approaches for video frame interpolation on challenging datasets.