 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIME: Efficient Headshot Image Super-Resolution with Multiple Exemplars
Mar 28, 2022
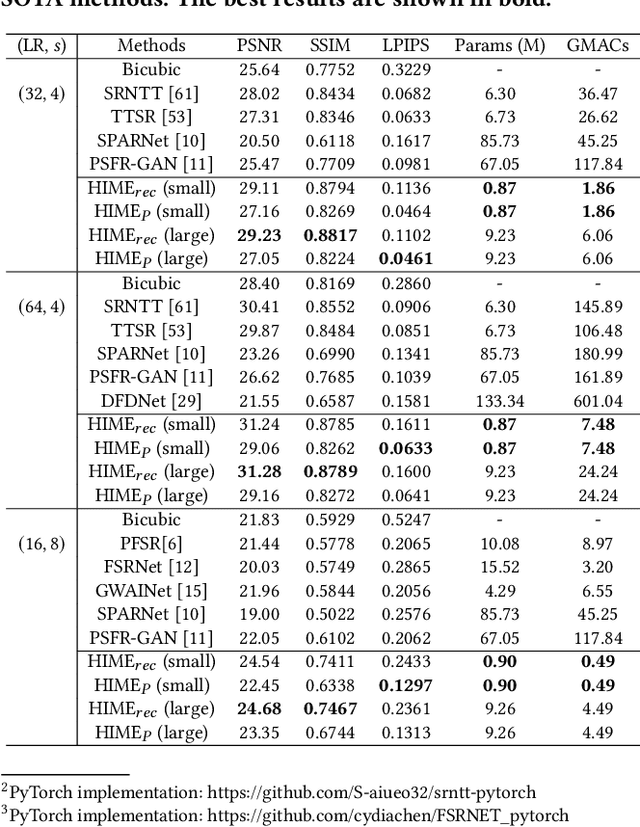
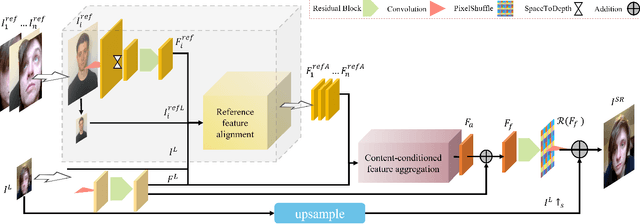
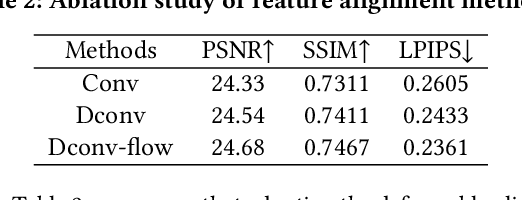
A promising direction for recovering the lost information in low-resolution headshot images is utilizing a set of high-resolution exemplars from the same identity. Complementary images in the reference set can improve the generated headshot quality across many different views and poses. However, it is challenging to make the best use of multiple exemplars: the quality and alignment of each exemplar cannot be guaranteed. Using low-quality and mismatched images as references will impair the output results. To overcome these issues, we propose an efficient Headshot Image Super-Resolution with Multiple Exemplars network (HIME) method. Compared with previous methods, our network can effectively handle the misalignment between the input and the reference without requiring facial priors and learn the aggregated reference set representation in an end-to-end manner. Furthermore, to reconstruct more detailed facial features, we propose a correlation loss that provides a rich representation of the local texture in a controllable spatial range. Experimental results demonstrate that the proposed framework not only has significantly fewer computation cost than recent exemplar-guided methods but also achieves better qualitative and quantitative performance.
APES: Audiovisual Person Search in Untrimmed Video
Jun 03, 2021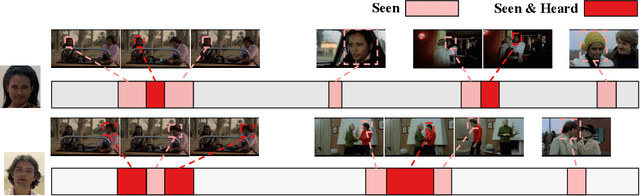
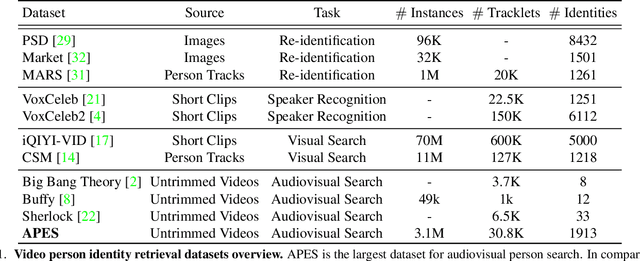


Humans are arguably one of the most important subjects in video streams, many real-world applications such as video summarization or video editing workflows often require the automatic search and retrieval of a person of interest. Despite tremendous efforts in the person reidentification and retrieval domains, few works have developed audiovisual search strategies. In this paper, we present the Audiovisual Person Search dataset (APES), a new dataset composed of untrimmed videos whose audio (voices) and visual (faces) streams are densely annotated. APES contains over 1.9K identities labeled along 36 hours of video, making it the largest dataset available for untrimmed audiovisual person search. A key property of APES is that it includes dense temporal annotations that link faces to speech segments of the same identity. To showcase the potential of our new dataset, we propose an audiovisual baseline and benchmark for person retrieval. Our study shows that modeling audiovisual cues benefits the recognition of people's identities. To enable reproducibility and promote future research, the dataset annotations and baseline code are available at: https://github.com/fuankarion/audiovisual-person-search
Content-Aware GAN Compression
Apr 06, 2021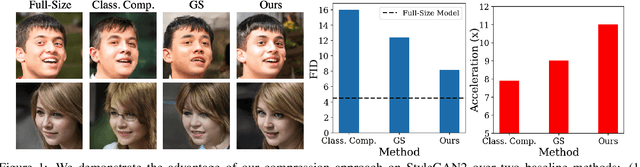
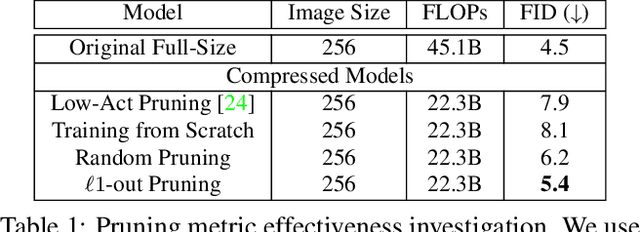
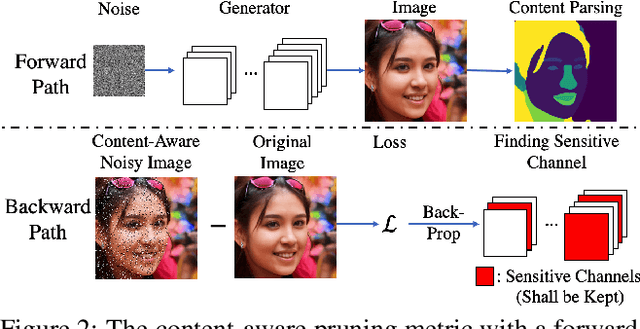
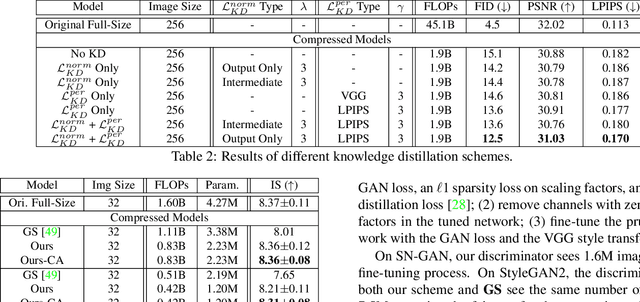
Generative adversarial networks (GANs), e.g., StyleGAN2, play a vital role in various image generation and synthesis tasks, yet their notoriously high computational cost hinders their efficient deployment on edge devices. Directly applying generic compression approaches yields poor results on GANs, which motivates a number of recent GAN compression works. While prior works mainly accelerate conditional GANs, e.g., pix2pix and CycleGAN, compressing state-of-the-art unconditional GANs has rarely been explored and is more challenging. In this paper, we propose novel approaches for unconditional GAN compression. We first introduce effective channel pruning and knowledge distillation schemes specialized for unconditional GANs. We then propose a novel content-aware method to guide the processes of both pruning and distillation. With content-awareness, we can effectively prune channels that are unimportant to the contents of interest, e.g., human faces, and focus our distillation on these regions, which significantly enhances the distillation quality. On StyleGAN2 and SN-GAN, we achieve a substantial improvement over the state-of-the-art compression method. Notably, we reduce the FLOPs of StyleGAN2 by 11x with visually negligible image quality loss compared to the full-size model. More interestingly, when applied to various image manipulation tasks, our compressed model forms a smoother and better disentangled latent manifold, making it more effective for image editing.
Deep Denoising of Flash and No-Flash Pairs for Photography in Low-Light Environments
Dec 09, 2020
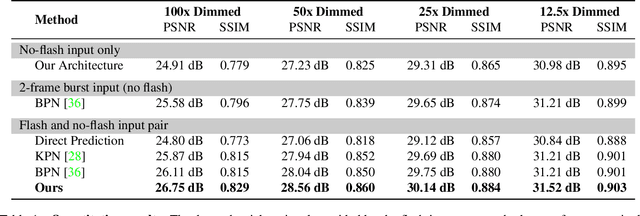
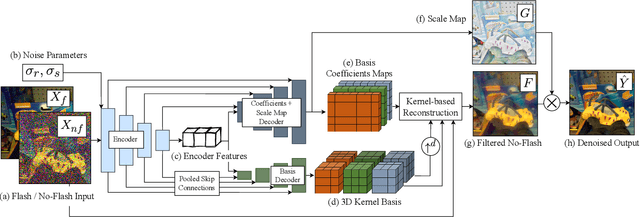
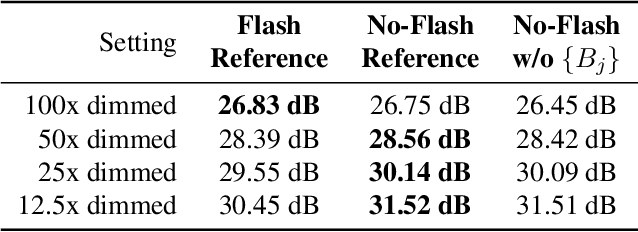
We introduce a neural network-based method to denoise pairs of images taken in quick succession in low-light environments, with and without a flash. Our goal is to produce a high-quality rendering of the scene that preserves the color and mood from the ambient illumination of the noisy no-flash image, while recovering surface texture and detail revealed by the flash. Our network outputs a gain map and a field of kernels, the latter obtained by linearly mixing elements of a per-image low-rank kernel basis. We first apply the kernel field to the no-flash image, and then multiply the result with the gain map to create the final output. We show our network effectively learns to produce high-quality images by combining a smoothed out estimate of the scene's ambient appearance from the no-flash image, with high-frequency albedo details extracted from the flash input. Our experiments show significant improvements over alternative captures without a flash, and baseline denoisers that use flash no-flash pairs. In particular, our method produces images that are both noise-free and contain accurate ambient colors without the sharp shadows or strong specular highlights visible in the flash image.
Deep Image Compositing
Nov 04, 2020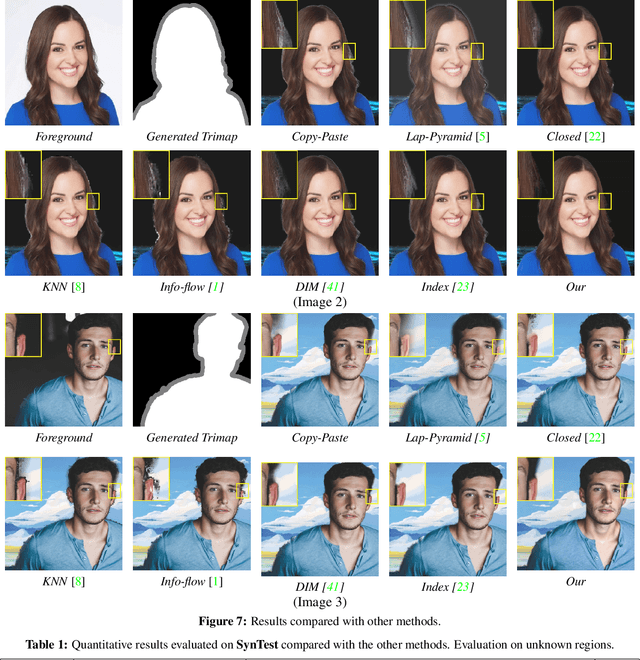

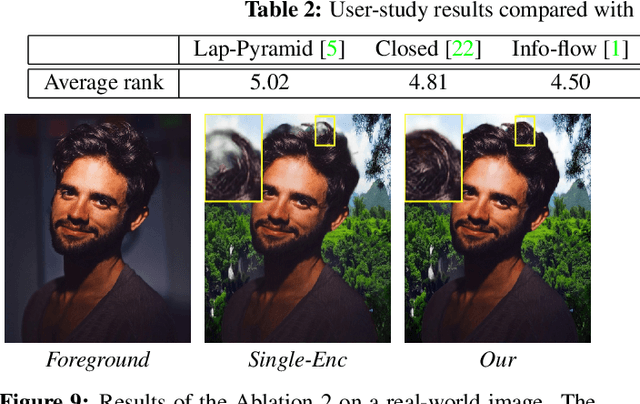
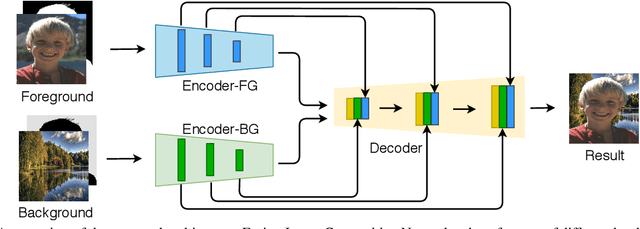
Image compositing is a task of combining regions from different images to compose a new image. A common use case is background replacement of portrait images. To obtain high quality composites, professionals typically manually perform multiple editing steps such as segmentation, matting and foreground color decontamination, which is very time consuming even with sophisticated photo editing tools. In this paper, we propose a new method which can automatically generate high-quality image compositing without any user input. Our method can be trained end-to-end to optimize exploitation of contextual and color information of both foreground and background images, where the compositing quality is considered in the optimization. Specifically, inspired by Laplacian pyramid blending, a dense-connected multi-stream fusion network is proposed to effectively fuse the information from the foreground and background images at different scales. In addition, we introduce a self-taught strategy to progressively train from easy to complex cases to mitigate the lack of training data. Experiments show that the proposed method can automatically generate high-quality composites and outperforms existing methods both qualitatively and quantitatively.
Single View Metrology in the Wild
Aug 11, 2020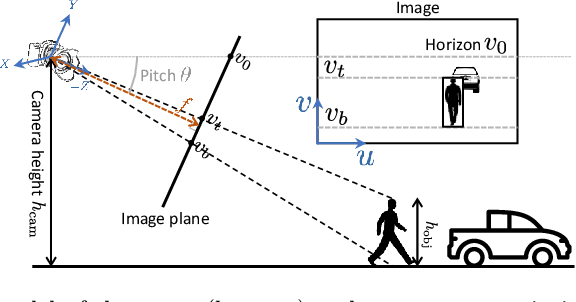

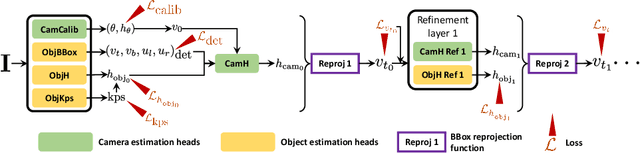
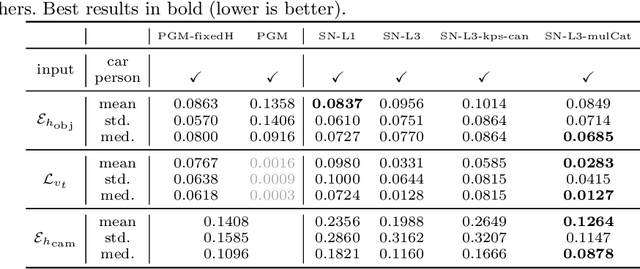
Most 3D reconstruction methods may only recover scene properties up to a global scale ambiguity. We present a novel approach to single view metrology that can recover the absolute scale of a scene represented by 3D heights of objects or camera height above the ground as well as camera parameters of orientation and field of view, using just a monocular image acquired in unconstrained condition. Our method relies on data-driven priors learned by a deep network specifically designed to imbibe weakly supervised constraints from the interplay of the unknown camera with 3D entities such as object heights, through estimation of bounding box projections. We leverage categorical priors for objects such as humans or cars that commonly occur in natural images, as references for scale estimation. We demonstrate state-of-the-art qualitative and quantitative results on several datasets as well as applications including virtual object insertion. Furthermore, the perceptual quality of our outputs is validated by a user study.
Shape Adaptor: A Learnable Resizing Module
Aug 10, 2020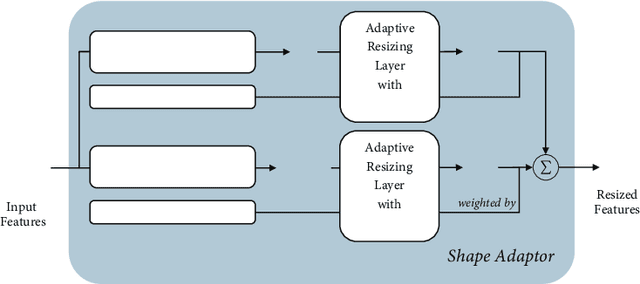
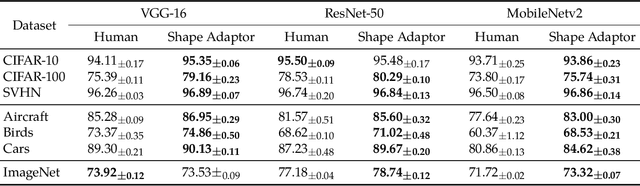

We present a novel resizing module for neural networks: shape adaptor, a drop-in enhancement built on top of traditional resizing layers, such as pooling, bilinear sampling, and strided convolution. Whilst traditional resizing layers have fixed and deterministic reshaping factors, our module allows for a learnable reshaping factor. Our implementation enables shape adaptors to be trained end-to-end without any additional supervision, through which network architectures can be optimised for each individual task, in a fully automated way. We performed experiments across seven image classification datasets, and results show that by simply using a set of our shape adaptors instead of the original resizing layers, performance increases consistently over human-designed networks, across all datasets. Additionally, we show the effectiveness of shape adaptors on two other applications: network compression and transfer learning. The source code is available at: https://github.com/lorenmt/shape-adaptor.
Real-time Semantic Segmentation with Fast Attention
Jul 09, 2020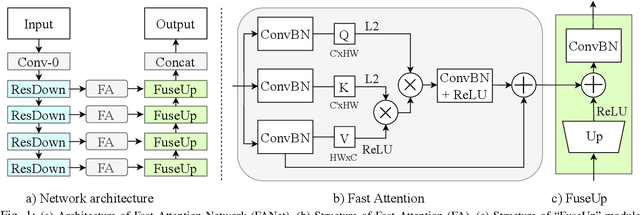
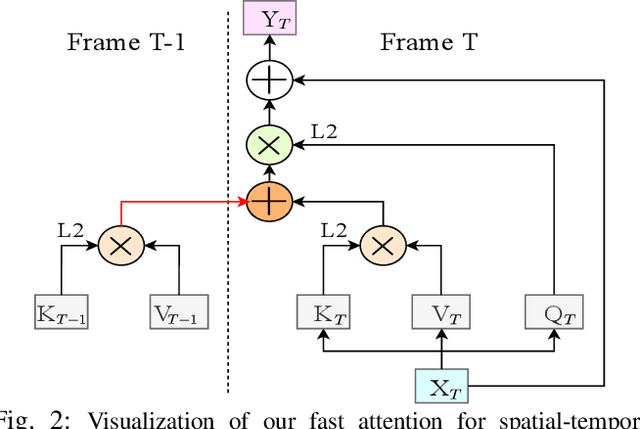
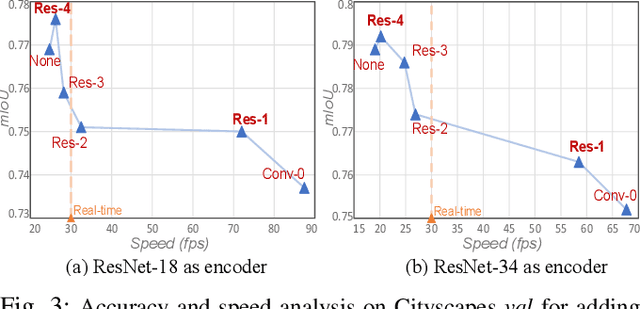

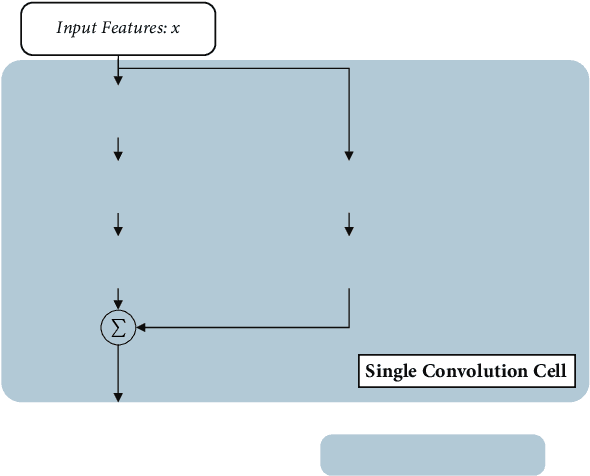
In deep CNN based models for semantic segmentation, high accuracy relies on rich spatial context (large receptive fields) and fine spatial details (high resolution), both of which incur high computational costs. In this paper, we propose a novel architecture that addresses both challenges and achieves state-of-the-art performance for semantic segmentation of high-resolution images and videos in real-time. The proposed architecture relies on our fast spatial attention, which is a simple yet efficient modification of the popular self-attention mechanism and captures the same rich spatial context at a small fraction of the computational cost, by changing the order of operations. Moreover, to efficiently process high-resolution input, we apply an additional spatial reduction to intermediate feature stages of the network with minimal loss in accuracy thanks to the use of the fast attention module to fuse features. We validate our method with a series of experiments, and show that results on multiple datasets demonstrate superior performance with better accuracy and speed compared to existing approaches for real-time semantic segmentation. On Cityscapes, our network achieves 74.4$\%$ mIoU at 72 FPS and 75.5$\%$ mIoU at 58 FPS on a single Titan X GPU, which is~$\sim$50$\%$ faster than the state-of-the-art while retaining the same accuracy.
Active Speakers in Context
May 20, 2020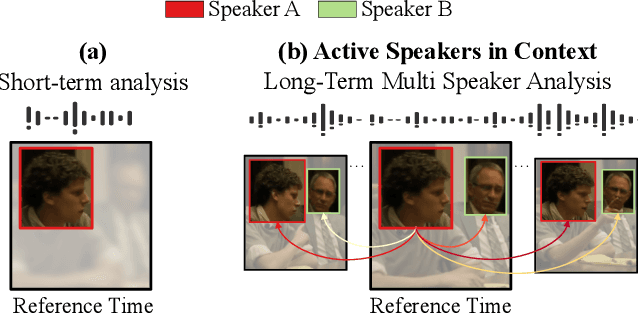
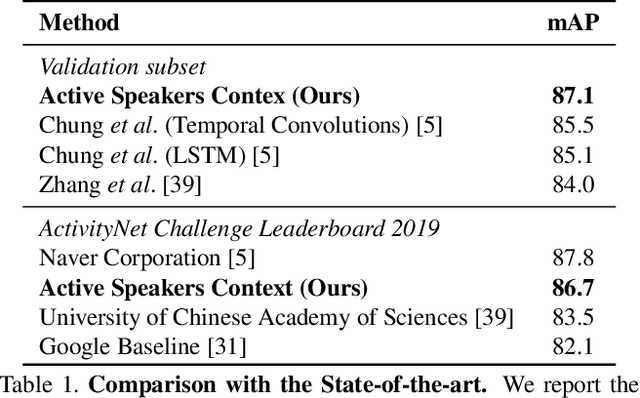
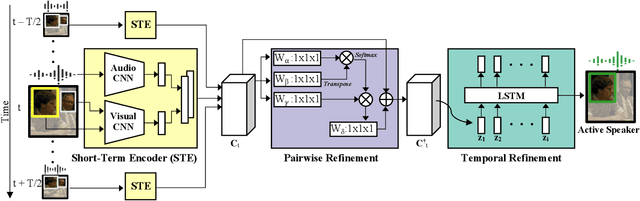

Current methods for active speak er detection focus on modeling short-term audiovisual information from a single speaker. Although this strategy can be enough for addressing single-speaker scenarios, it prevents accurate detection when the task is to identify who of many candidate speakers are talking. This paper introduces the Active Speaker Context, a novel representation that models relationships between multiple speakers over long time horizons. Our Active Speaker Context is designed to learn pairwise and temporal relations from an structured ensemble of audio-visual observations. Our experiments show that a structured feature ensemble already benefits the active speaker detection performance. Moreover, we find that the proposed Active Speaker Context improves the state-of-the-art on the AVA-ActiveSpeaker dataset achieving a mAP of 87.1%. We present ablation studies that verify that this result is a direct consequence of our long-term multi-speaker analysis.
Temporally Distributed Networks for Fast Video Semantic Segmentation
Apr 07, 2020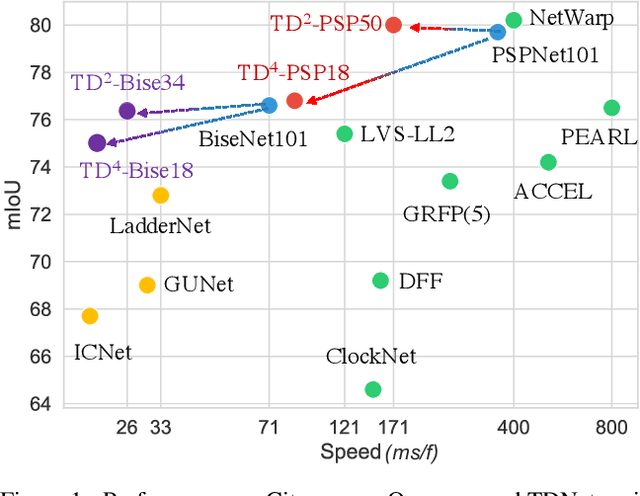
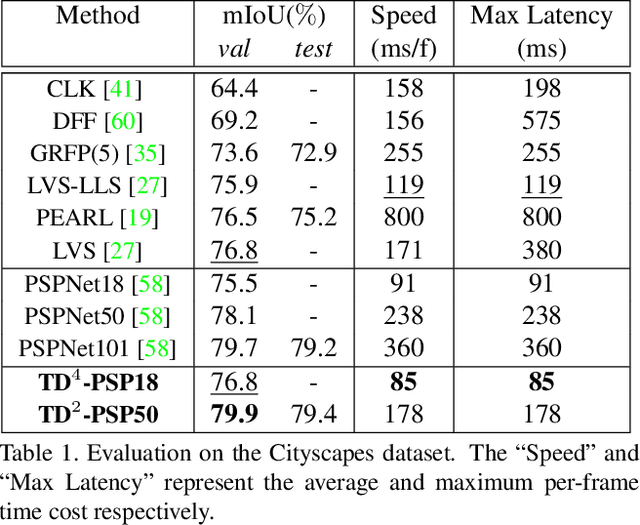
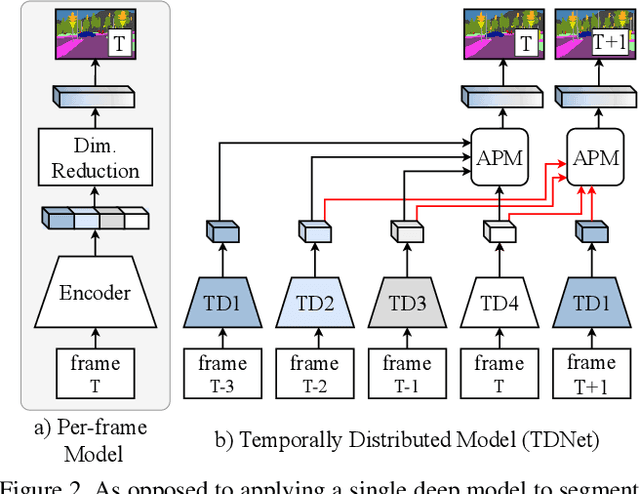
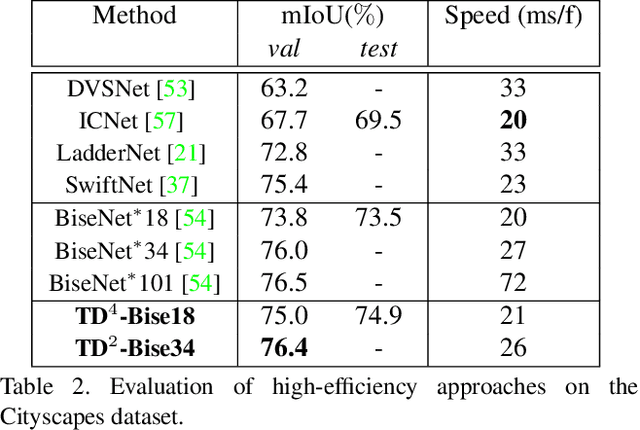
We present TDNet, a temporally distributed network designed for fast and accurate video semantic segmentation. We observe that features extracted from a certain high-level layer of a deep CNN can be approximated by composing features extracted from several shallower sub-networks. Leveraging the inherent temporal continuity in videos, we distribute these sub-networks over sequential frames. Therefore, at each time step, we only need to perform a lightweight computation to extract a sub-features group from a single sub-network. The full features used for segmentation are then recomposed by application of a novel attention propagation module that compensates for geometry deformation between frames. A grouped knowledge distillation loss is also introduced to further improve the representation power at both full and sub-feature levels. Experiments on Cityscapes, CamVid, and NYUD-v2 demonstrate that our method achieves state-of-the-art accuracy with significantly faster speed and lower latency.