 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthICL: Scalable In-context Imitation Learning with Synthetic Data
Jun 06, 2026In-context imitation learning (ICIL) enables robots to learn new tasks from a small number of demonstrations by conditioning a pre-trained policy on task-specific examples, without retraining at test time. Despite this promise, training generalizable and scalable in-context imitation policies remains an open challenge. We present SynthICL, a scalable framework that trains ICIL policies entirely from RGB-only synthetic data. Specifically, we build a data generation pipeline to produce high-fidelity ICIL data and train a flow-matching transformer policy on the resulting dataset. SynthICL avoids the need for depth sensing, precise camera calibration, and real-world training data in prior approaches, offering a simpler and more scalable alternative. We further incorporate subgoal prediction by training the model to predict the next subgoal images, enabling more precise and visually grounded control. Evaluated on 16 unseen real-world manipulation tasks, SynthICL achieves an average success rate of 79% with only one demonstration provided at test time and outperforms prior methods. Project page: https://synth-icl.github.io
Instant-Fold: In-Context Imitation Learning for Deformable Object Manipulation
Jun 02, 2026Deformable object manipulation (DOM) is challenging due to high-dimensional, partially observable states that evolve through long-horizon, topology-changing interactions with multiple valid manipulation modes. We introduce Instant-Fold, an in-context imitation learning framework for DOM. Given a single human demonstration, our policy infers and executes diverse manipulation modes directly from the demonstration, including variations in spatial execution and ordering, without requiring gradient updates. Our approach first learns deformation-aware visual representations via temporal contrastive pretraining, after which a flow-matching transformer policy conditioned on the demonstration predicts actions to execute the intended manipulation mode. Trained entirely in simulation, Instant-Fold generalizes across diverse folding modes and transfers zero-shot to real-world settings without additional data collection or finetuning. Videos are available at https://instant-fold.github.io.
Learning a Thousand Tasks in a Day
Nov 13, 2025Humans are remarkably efficient at learning tasks from demonstrations, but today's imitation learning methods for robot manipulation often require hundreds or thousands of demonstrations per task. We investigate two fundamental priors for improving learning efficiency: decomposing manipulation trajectories into sequential alignment and interaction phases, and retrieval-based generalisation. Through 3,450 real-world rollouts, we systematically study this decomposition. We compare different design choices for the alignment and interaction phases, and examine generalisation and scaling trends relative to today's dominant paradigm of behavioural cloning with a single-phase monolithic policy. In the few-demonstrations-per-task regime (<10 demonstrations), decomposition achieves an order of magnitude improvement in data efficiency over single-phase learning, with retrieval consistently outperforming behavioural cloning for both alignment and interaction. Building on these insights, we develop Multi-Task Trajectory Transfer (MT3), an imitation learning method based on decomposition and retrieval. MT3 learns everyday manipulation tasks from as little as a single demonstration each, whilst also generalising to novel object instances. This efficiency enables us to teach a robot 1,000 distinct everyday tasks in under 24 hours of human demonstrator time. Through 2,200 additional real-world rollouts, we reveal MT3's capabilities and limitations across different task families. Videos of our experiments can be found on at https://www.robot-learning.uk/learning-1000-tasks.
* This is the author's version of the work. It is posted here by permission of the AAAS for personal use, not for redistribution. The definitive version was published in Science Robotics on 12 November 2025, DOI: https://www.science.org/doi/10.1126/scirobotics.adv7594. Link to project website: https://www.robot-learning.uk/learning-1000-tasks
Neural Stochastic Flows: Solver-Free Modelling and Inference for SDE Solutions
Oct 29, 2025Stochastic differential equations (SDEs) are well suited to modelling noisy and irregularly sampled time series found in finance, physics, and machine learning. Traditional approaches require costly numerical solvers to sample between arbitrary time points. We introduce Neural Stochastic Flows (NSFs) and their latent variants, which directly learn (latent) SDE transition laws using conditional normalising flows with architectural constraints that preserve properties inherited from stochastic flows. This enables one-shot sampling between arbitrary states and yields up to two orders of magnitude speed-ups at large time gaps. Experiments on synthetic SDE simulations and on real-world tracking and video data show that NSFs maintain distributional accuracy comparable to numerical approaches while dramatically reducing computation for arbitrary time-point sampling.
One-Shot Dual-Arm Imitation Learning
Mar 10, 2025
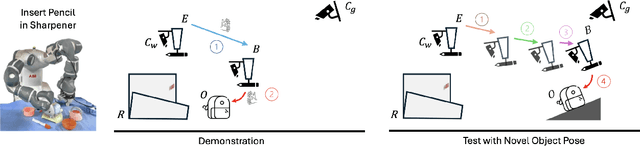
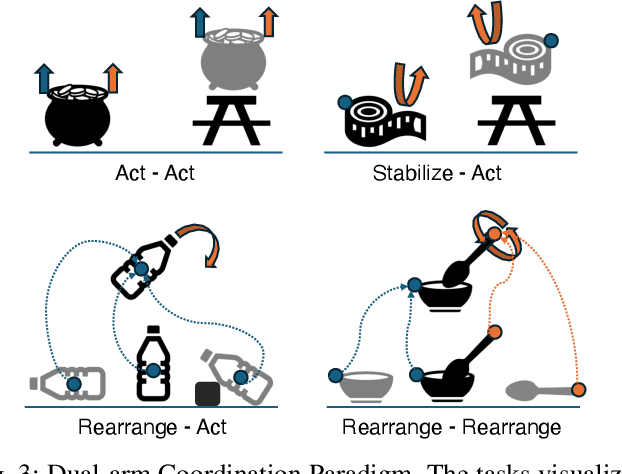

We introduce One-Shot Dual-Arm Imitation Learning (ODIL), which enables dual-arm robots to learn precise and coordinated everyday tasks from just a single demonstration of the task. ODIL uses a new three-stage visual servoing (3-VS) method for precise alignment between the end-effector and target object, after which replay of the demonstration trajectory is sufficient to perform the task. This is achieved without requiring prior task or object knowledge, or additional data collection and training following the single demonstration. Furthermore, we propose a new dual-arm coordination paradigm for learning dual-arm tasks from a single demonstration. ODIL was tested on a real-world dual-arm robot, demonstrating state-of-the-art performance across six precise and coordinated tasks in both 4-DoF and 6-DoF settings, and showing robustness in the presence of distractor objects and partial occlusions. Videos are available at: https://www.robot-learning.uk/one-shot-dual-arm.
Instant Policy: In-Context Imitation Learning via Graph Diffusion
Nov 19, 2024



Following the impressive capabilities of in-context learning with large transformers, In-Context Imitation Learning (ICIL) is a promising opportunity for robotics. We introduce Instant Policy, which learns new tasks instantly (without further training) from just one or two demonstrations, achieving ICIL through two key components. First, we introduce inductive biases through a graph representation and model ICIL as a graph generation problem with a learned diffusion process, enabling structured reasoning over demonstrations, observations, and actions. Second, we show that such a model can be trained using pseudo-demonstrations - arbitrary trajectories generated in simulation - as a virtually infinite pool of training data. Simulated and real experiments show that Instant Policy enables rapid learning of various everyday robot tasks. We also show how it can serve as a foundation for cross-embodiment and zero-shot transfer to language-defined tasks. Code and videos are available at https://www.robot-learning.uk/instant-policy.
MILES: Making Imitation Learning Easy with Self-Supervision
Oct 25, 2024



Data collection in imitation learning often requires significant, laborious human supervision, such as numerous demonstrations, and/or frequent environment resets for methods that incorporate reinforcement learning. In this work, we propose an alternative approach, MILES: a fully autonomous, self-supervised data collection paradigm, and we show that this enables efficient policy learning from just a single demonstration and a single environment reset. MILES autonomously learns a policy for returning to and then following the single demonstration, whilst being self-guided during data collection, eliminating the need for additional human interventions. We evaluated MILES across several real-world tasks, including tasks that require precise contact-rich manipulation such as locking a lock with a key. We found that, under the constraints of a single demonstration and no repeated environment resetting, MILES significantly outperforms state-of-the-art alternatives like imitation learning methods that leverage reinforcement learning. Videos of our experiments and code can be found on our webpage: www.robot-learning.uk/miles.
Adapting Skills to Novel Grasps: A Self-Supervised Approach
Jul 31, 2024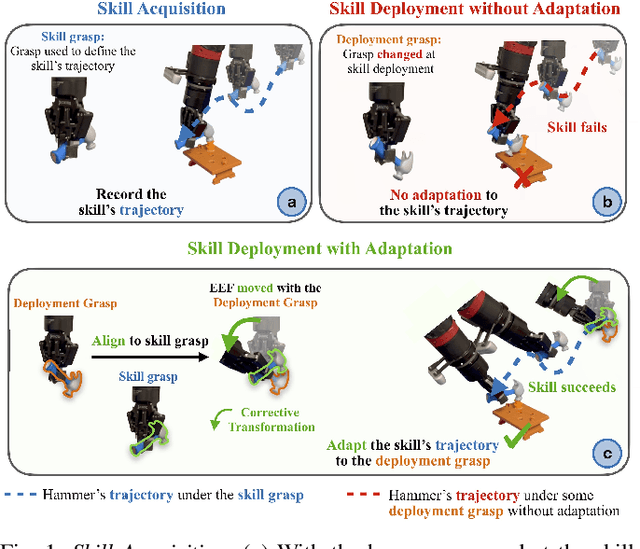
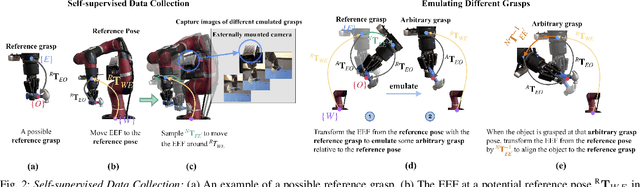
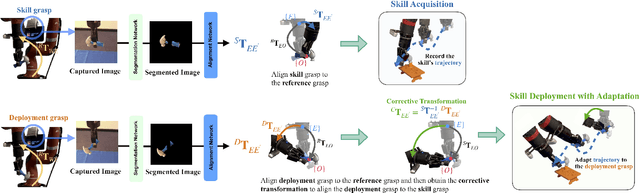
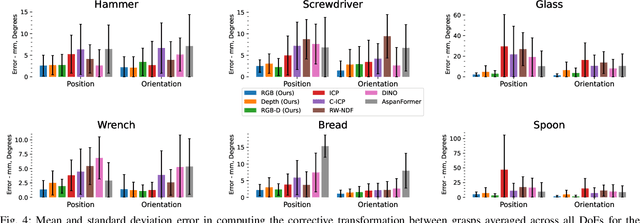
In this paper, we study the problem of adapting manipulation trajectories involving grasped objects (e.g. tools) defined for a single grasp pose to novel grasp poses. A common approach to address this is to define a new trajectory for each possible grasp explicitly, but this is highly inefficient. Instead, we propose a method to adapt such trajectories directly while only requiring a period of self-supervised data collection, during which a camera observes the robot's end-effector moving with the object rigidly grasped. Importantly, our method requires no prior knowledge of the grasped object (such as a 3D CAD model), it can work with RGB images, depth images, or both, and it requires no camera calibration. Through a series of real-world experiments involving 1360 evaluations, we find that self-supervised RGB data consistently outperforms alternatives that rely on depth images including several state-of-the-art pose estimation methods. Compared to the best-performing baseline, our method results in an average of 28.5% higher success rate when adapting manipulation trajectories to novel grasps on several everyday tasks. Videos of the experiments are available on our webpage at https://www.robot-learning.uk/adapting-skills
R+X: Retrieval and Execution from Everyday Human Videos
Jul 17, 2024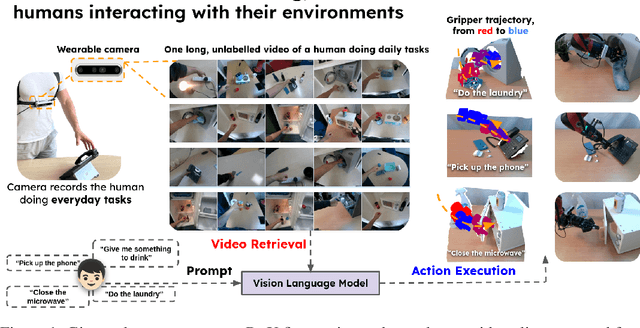
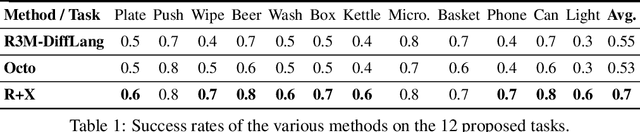

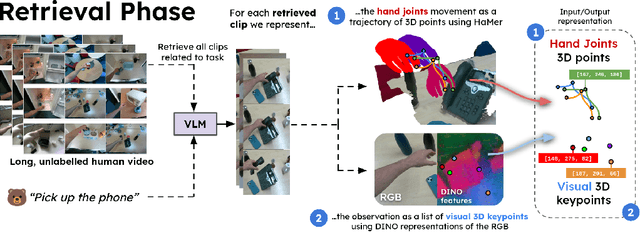
We present R+X, a framework which enables robots to learn skills from long, unlabelled, first-person videos of humans performing everyday tasks. Given a language command from a human, R+X first retrieves short video clips containing relevant behaviour, and then executes the skill by conditioning an in-context imitation learning method on this behaviour. By leveraging a Vision Language Model (VLM) for retrieval, R+X does not require any manual annotation of the videos, and by leveraging in-context learning for execution, robots can perform commanded skills immediately, without requiring a period of training on the retrieved videos. Experiments studying a range of everyday household tasks show that R+X succeeds at translating unlabelled human videos into robust robot skills, and that R+X outperforms several recent alternative methods. Videos are available at https://www.robot-learning.uk/r-plus-x.
Keypoint Action Tokens Enable In-Context Imitation Learning in Robotics
Mar 28, 2024



We show that off-the-shelf text-based Transformers, with no additional training, can perform few-shot in-context visual imitation learning, mapping visual observations to action sequences that emulate the demonstrator's behaviour. We achieve this by transforming visual observations (inputs) and trajectories of actions (outputs) into sequences of tokens that a text-pretrained Transformer (GPT-4 Turbo) can ingest and generate, via a framework we call Keypoint Action Tokens (KAT). Despite being trained only on language, we show that these Transformers excel at translating tokenised visual keypoint observations into action trajectories, performing on par or better than state-of-the-art imitation learning (diffusion policies) in the low-data regime on a suite of real-world, everyday tasks. Rather than operating in the language domain as is typical, KAT leverages text-based Transformers to operate in the vision and action domains to learn general patterns in demonstration data for highly efficient imitation learning, indicating promising new avenues for repurposing natural language models for embodied tasks. Videos are available at https://www.robot-learning.uk/keypoint-action-tokens.