 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Thousand Tasks in a Day
Nov 13, 2025Humans are remarkably efficient at learning tasks from demonstrations, but today's imitation learning methods for robot manipulation often require hundreds or thousands of demonstrations per task. We investigate two fundamental priors for improving learning efficiency: decomposing manipulation trajectories into sequential alignment and interaction phases, and retrieval-based generalisation. Through 3,450 real-world rollouts, we systematically study this decomposition. We compare different design choices for the alignment and interaction phases, and examine generalisation and scaling trends relative to today's dominant paradigm of behavioural cloning with a single-phase monolithic policy. In the few-demonstrations-per-task regime (<10 demonstrations), decomposition achieves an order of magnitude improvement in data efficiency over single-phase learning, with retrieval consistently outperforming behavioural cloning for both alignment and interaction. Building on these insights, we develop Multi-Task Trajectory Transfer (MT3), an imitation learning method based on decomposition and retrieval. MT3 learns everyday manipulation tasks from as little as a single demonstration each, whilst also generalising to novel object instances. This efficiency enables us to teach a robot 1,000 distinct everyday tasks in under 24 hours of human demonstrator time. Through 2,200 additional real-world rollouts, we reveal MT3's capabilities and limitations across different task families. Videos of our experiments can be found on at https://www.robot-learning.uk/learning-1000-tasks.
* This is the author's version of the work. It is posted here by permission of the AAAS for personal use, not for redistribution. The definitive version was published in Science Robotics on 12 November 2025, DOI: https://www.science.org/doi/10.1126/scirobotics.adv7594. Link to project website: https://www.robot-learning.uk/learning-1000-tasks
R+X: Retrieval and Execution from Everyday Human Videos
Jul 17, 2024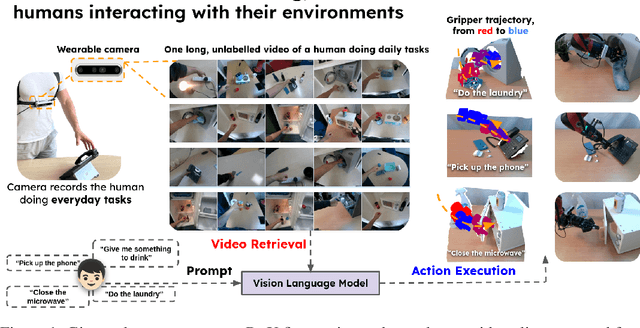
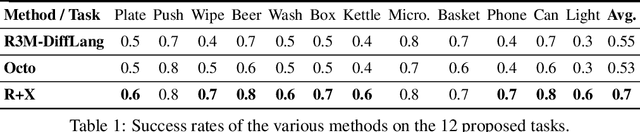

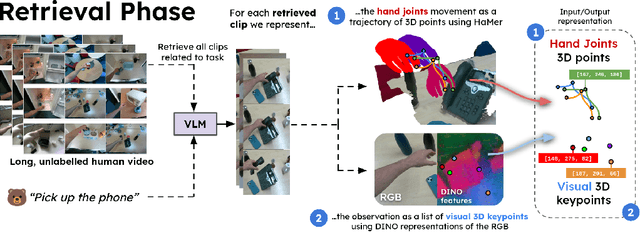
We present R+X, a framework which enables robots to learn skills from long, unlabelled, first-person videos of humans performing everyday tasks. Given a language command from a human, R+X first retrieves short video clips containing relevant behaviour, and then executes the skill by conditioning an in-context imitation learning method on this behaviour. By leveraging a Vision Language Model (VLM) for retrieval, R+X does not require any manual annotation of the videos, and by leveraging in-context learning for execution, robots can perform commanded skills immediately, without requiring a period of training on the retrieved videos. Experiments studying a range of everyday household tasks show that R+X succeeds at translating unlabelled human videos into robust robot skills, and that R+X outperforms several recent alternative methods. Videos are available at https://www.robot-learning.uk/r-plus-x.
One-Shot Imitation Learning: A Pose Estimation Perspective
Oct 18, 2023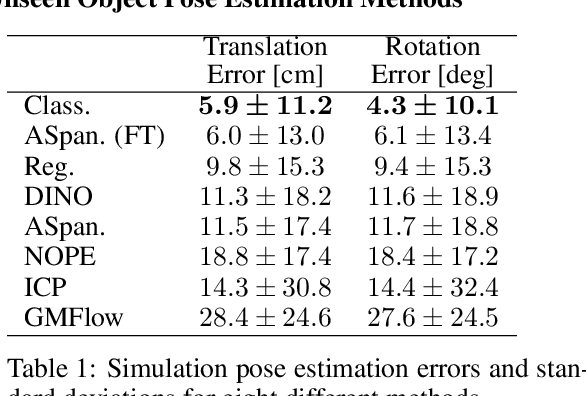
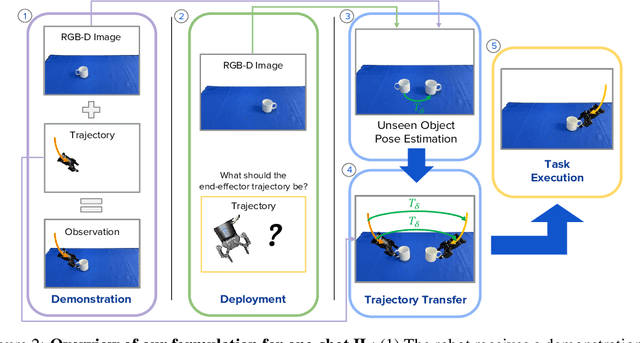
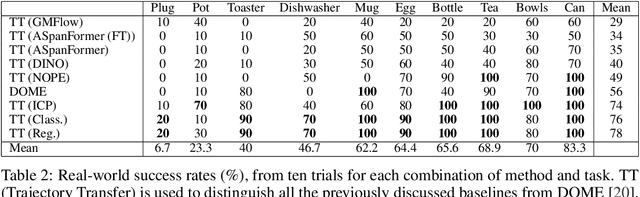

In this paper, we study imitation learning under the challenging setting of: (1) only a single demonstration, (2) no further data collection, and (3) no prior task or object knowledge. We show how, with these constraints, imitation learning can be formulated as a combination of trajectory transfer and unseen object pose estimation. To explore this idea, we provide an in-depth study on how state-of-the-art unseen object pose estimators perform for one-shot imitation learning on ten real-world tasks, and we take a deep dive into the effects that camera calibration, pose estimation error, and spatial generalisation have on task success rates. For videos, please visit https://www.robot-learning.uk/pose-estimation-perspective.