 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMILES: Making Imitation Learning Easy with Self-Supervision
Oct 25, 2024



Data collection in imitation learning often requires significant, laborious human supervision, such as numerous demonstrations, and/or frequent environment resets for methods that incorporate reinforcement learning. In this work, we propose an alternative approach, MILES: a fully autonomous, self-supervised data collection paradigm, and we show that this enables efficient policy learning from just a single demonstration and a single environment reset. MILES autonomously learns a policy for returning to and then following the single demonstration, whilst being self-guided during data collection, eliminating the need for additional human interventions. We evaluated MILES across several real-world tasks, including tasks that require precise contact-rich manipulation such as locking a lock with a key. We found that, under the constraints of a single demonstration and no repeated environment resetting, MILES significantly outperforms state-of-the-art alternatives like imitation learning methods that leverage reinforcement learning. Videos of our experiments and code can be found on our webpage: www.robot-learning.uk/miles.
Adapting Skills to Novel Grasps: A Self-Supervised Approach
Jul 31, 2024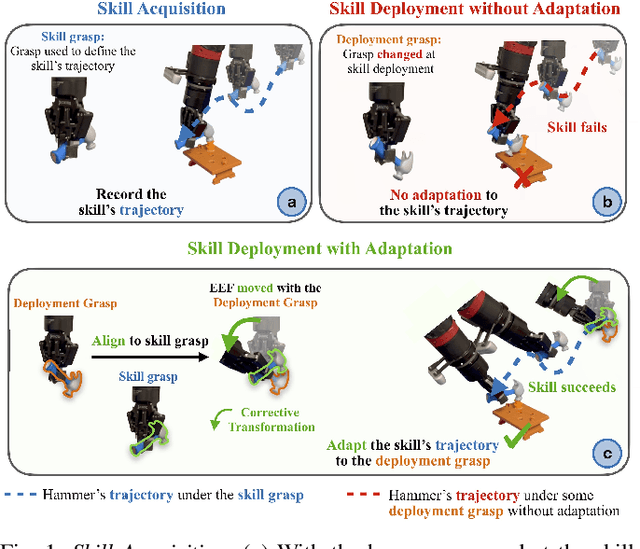
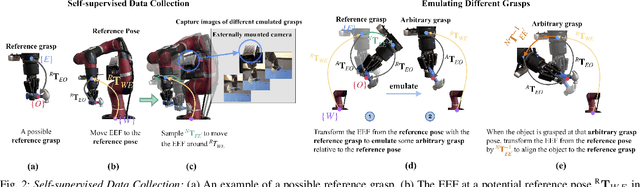
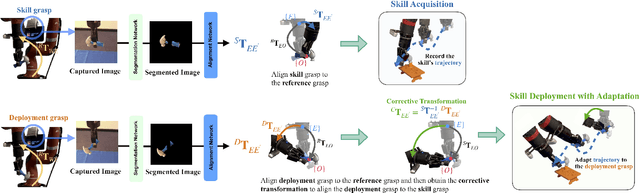
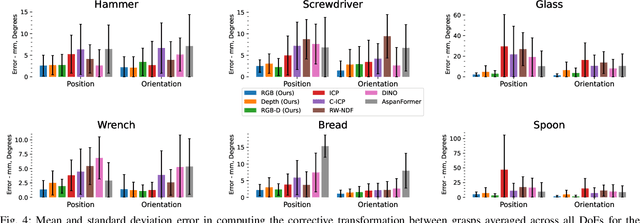
In this paper, we study the problem of adapting manipulation trajectories involving grasped objects (e.g. tools) defined for a single grasp pose to novel grasp poses. A common approach to address this is to define a new trajectory for each possible grasp explicitly, but this is highly inefficient. Instead, we propose a method to adapt such trajectories directly while only requiring a period of self-supervised data collection, during which a camera observes the robot's end-effector moving with the object rigidly grasped. Importantly, our method requires no prior knowledge of the grasped object (such as a 3D CAD model), it can work with RGB images, depth images, or both, and it requires no camera calibration. Through a series of real-world experiments involving 1360 evaluations, we find that self-supervised RGB data consistently outperforms alternatives that rely on depth images including several state-of-the-art pose estimation methods. Compared to the best-performing baseline, our method results in an average of 28.5% higher success rate when adapting manipulation trajectories to novel grasps on several everyday tasks. Videos of the experiments are available on our webpage at https://www.robot-learning.uk/adapting-skills
R+X: Retrieval and Execution from Everyday Human Videos
Jul 17, 2024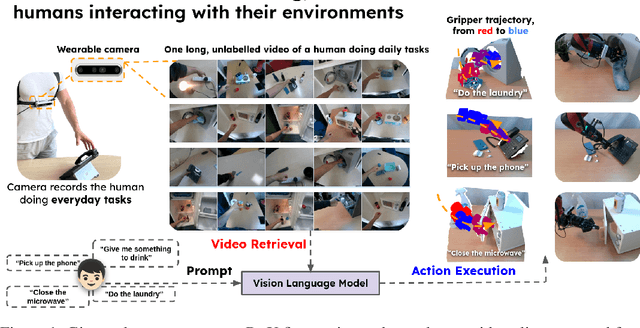
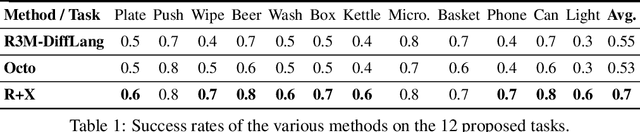

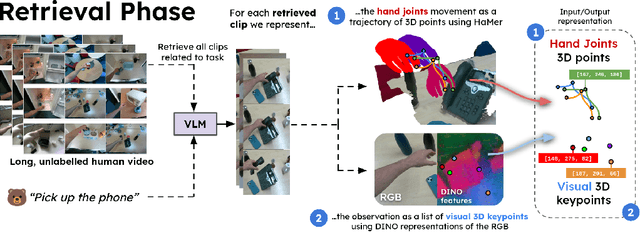
We present R+X, a framework which enables robots to learn skills from long, unlabelled, first-person videos of humans performing everyday tasks. Given a language command from a human, R+X first retrieves short video clips containing relevant behaviour, and then executes the skill by conditioning an in-context imitation learning method on this behaviour. By leveraging a Vision Language Model (VLM) for retrieval, R+X does not require any manual annotation of the videos, and by leveraging in-context learning for execution, robots can perform commanded skills immediately, without requiring a period of training on the retrieved videos. Experiments studying a range of everyday household tasks show that R+X succeeds at translating unlabelled human videos into robust robot skills, and that R+X outperforms several recent alternative methods. Videos are available at https://www.robot-learning.uk/r-plus-x.
Demonstrate Once, Imitate Immediately (DOME): Learning Visual Servoing for One-Shot Imitation Learning
Apr 06, 2022
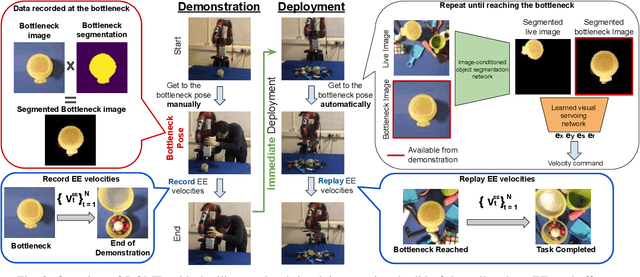


We present DOME, a novel method for one-shot imitation learning, where a task can be learned from just a single demonstration and then be deployed immediately, without any further data collection or training. DOME does not require prior task or object knowledge, and can perform the task in novel object configurations and with distractors. At its core, DOME uses an image-conditioned object segmentation network followed by a learned visual servoing network, to move the robot's end-effector to the same relative pose to the object as during the demonstration, after which the task can be completed by replaying the demonstration's end-effector velocities. We show that DOME achieves near 100% success rate on 7 real-world everyday tasks, and we perform several studies to thoroughly understand each individual component of DOME.
End-To-End Semi-supervised Learning for Differentiable Particle Filters
Nov 11, 2020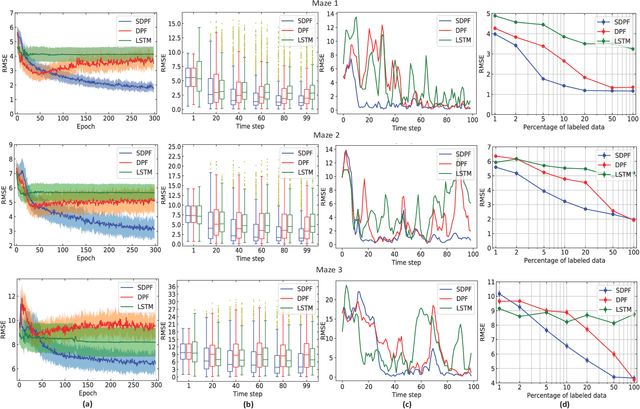
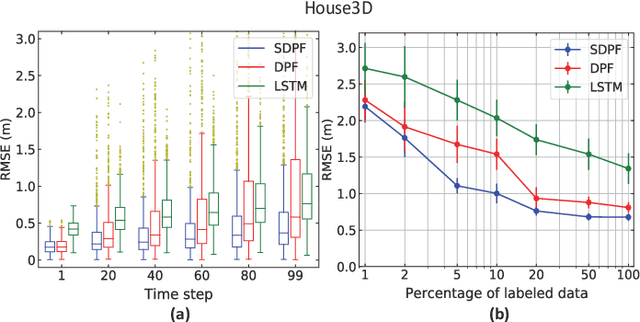
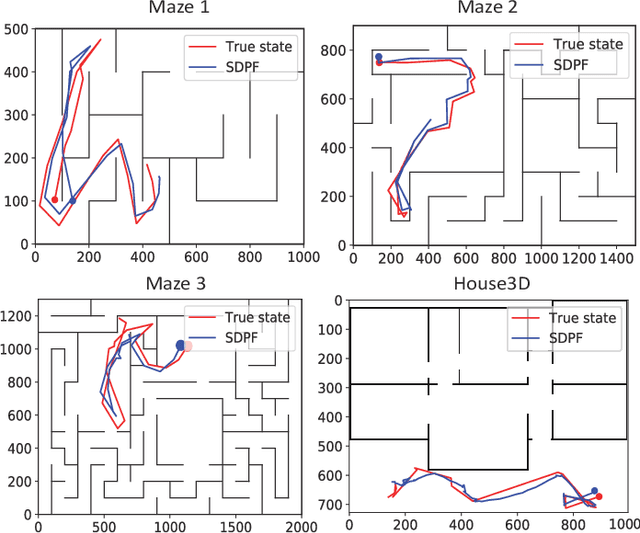
Recent advances in incorporating neural networks into particle filters provide the desired flexibility to apply particle filters in large-scale real-world applications. The dynamic and measurement models in this framework are learnable through the differentiable implementation of particle filters. Past efforts in optimising such models often require the knowledge of true states which can be expensive to obtain or even unavailable in practice. In this paper, in order to reduce the demand for annotated data, we present an end-to-end learning objective based upon the maximisation of a pseudo-likelihood function which can improve the estimation of states when large portion of true states are unknown. We assess performance of the proposed method in state estimation tasks in robotics with simulated and real-world datasets.
Imitation Learning with Sinkhorn Distances
Aug 20, 2020



Imitation learning algorithms have been interpreted as variants of divergence minimization problems. The ability to compare occupancy measures between experts and learners is crucial in their effectiveness in learning from demonstrations. In this paper, we present tractable solutions by formulating imitation learning as minimization of the Sinkhorn distance between occupancy measures. The formulation combines the valuable properties of optimal transport metrics in comparing non-overlapping distributions with a cosine distance cost defined in an adversarially learned feature space. This leads to a highly discriminative critic network and optimal transport plan that subsequently guide imitation learning. We evaluate the proposed approach using both the reward metric and the Sinkhorn distance metric on a number of MuJoCo experiments.
Deep Reinforcement Learning for Control of Probabilistic Boolean Networks
Sep 10, 2019
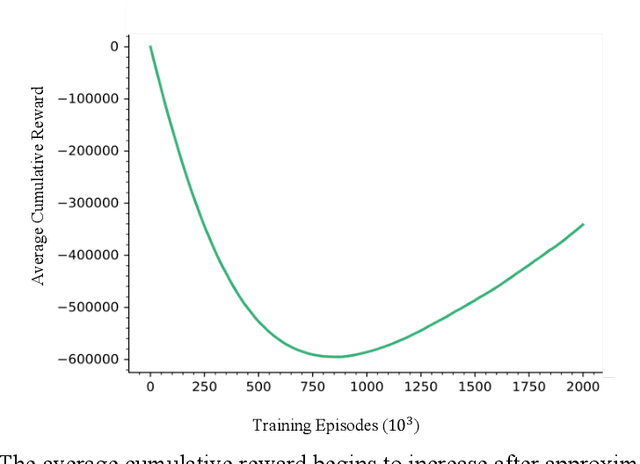
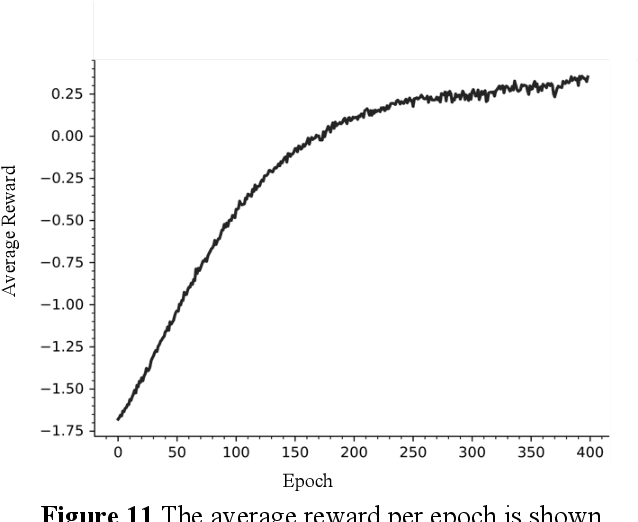

Probabilistic Boolean Networks (PBNs) were introduced as a computational model for studying gene interactions in Gene Regulatory Networks (GRNs). Controllability of PBNs, and hence GRNs, is the process of making strategic interventions to a network in order to drive it from a particular state towards some other potentially more desirable state. This is of significant importance to systems biology as successful control could be used to obtain potential gene treatments by making therapeutic interventions. Recent advancements in Deep Reinforcement Learning have enabled systems to develop policies merely by interacting with the environment, without complete knowledge of the underlying Markov Decision Process (MDP). In this paper we have implemented a Deep Q Network with Double Q Learning, that directly interacts with the environment -that is, a Probabilistic Boolean Network. Our approach develops a control policy by sampling experiences obtained from the environment using Prioritized Experience Replay which successfully drives a PBN from any state towards the desired one. This novel approach sets the foundations for overcoming the inability to scale to larger PBNs and opens up the spectrum in which to consider control of GRNs without the need of a computational model, i.e. by direct interventions to the GRN.
A Bayesian Ensemble Regression Framework on the Angry Birds Game
Aug 25, 2014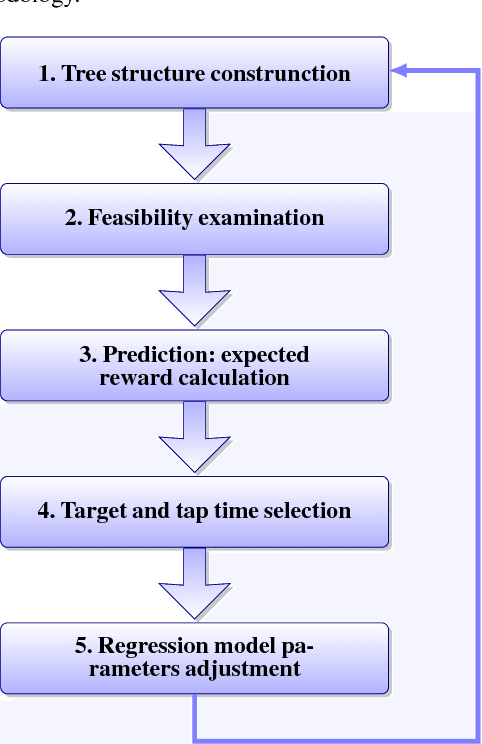
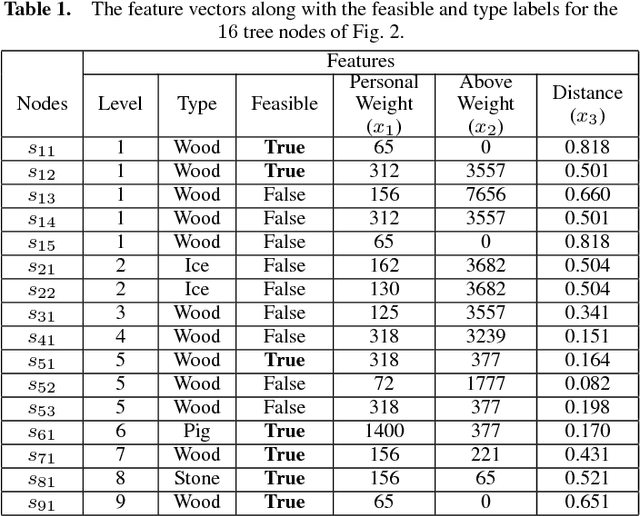
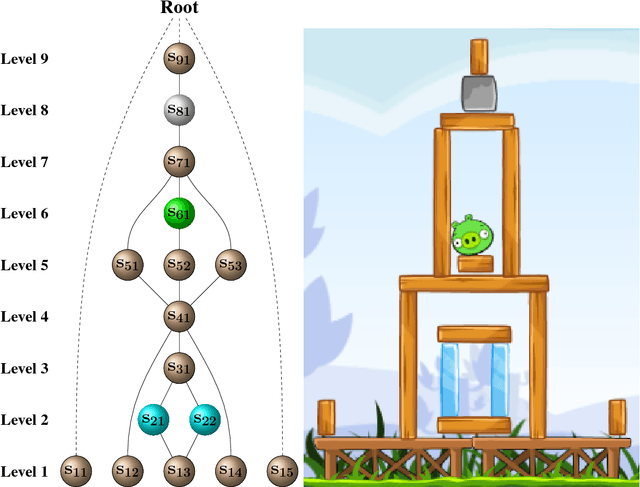
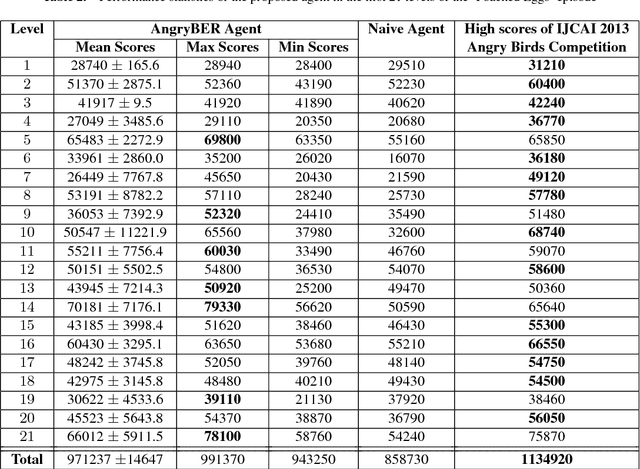
An ensemble inference mechanism is proposed on the Angry Birds domain. It is based on an efficient tree structure for encoding and representing game screenshots, where it exploits its enhanced modeling capability. This has the advantage to establish an informative feature space and modify the task of game playing to a regression analysis problem. To this direction, we assume that each type of object material and bird pair has its own Bayesian linear regression model. In this way, a multi-model regression framework is designed that simultaneously calculates the conditional expectations of several objects and makes a target decision through an ensemble of regression models. Learning procedure is performed according to an online estimation strategy for the model parameters. We provide comparative experimental results on several game levels that empirically illustrate the efficiency of the proposed methodology.