 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Sampling based on Local Label Imbalance
May 19, 2020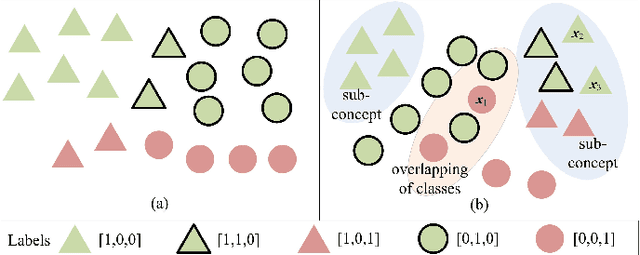


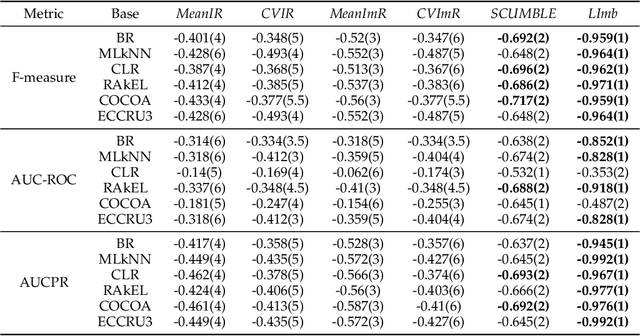
Class imbalance is an inherent characteristic of multi-label data that hinders most multi-label learning methods. One efficient and flexible strategy to deal with this problem is to employ sampling techniques before training a multi-label learning model. Although existing multi-label sampling approaches alleviate the global imbalance of multi-label datasets, it is actually the imbalance level within the local neighbourhood of minority class examples that plays a key role in performance degradation. To address this issue, we propose a novel measure to assess the local label imbalance of multi-label datasets, as well as two multi-label sampling approaches based on the local label imbalance, namely MLSOL and MLUL. By considering all informative labels, MLSOL creates more diverse and better labeled synthetic instances for difficult examples, while MLUL eliminates instances that are harmful to their local region. Experimental results on 13 multi-label datasets demonstrate the effectiveness of the proposed measure and sampling approaches for a variety of evaluation metrics, particularly in the case of an ensemble of classifiers trained on repeated samples of the original data.
Resolving Congestions in the Air Traffic Management Domain via Multiagent Reinforcement Learning Methods
Dec 14, 2019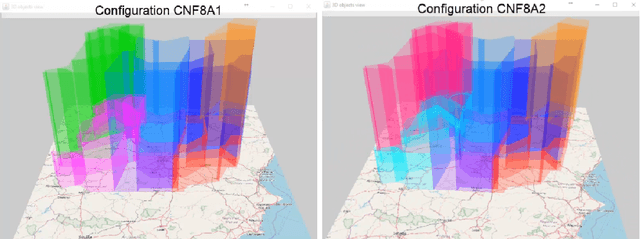
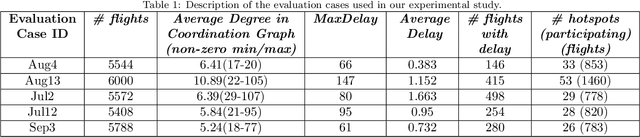
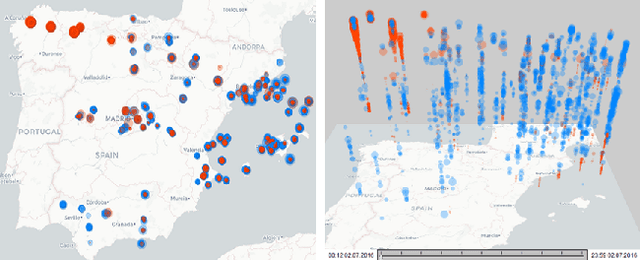
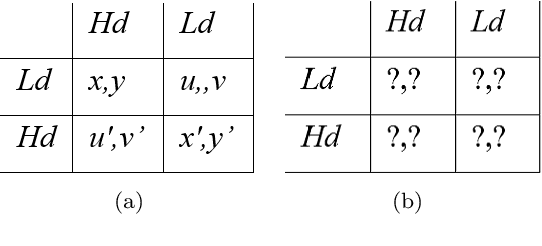
In this article, we report on the efficiency and effectiveness of multiagent reinforcement learning methods (MARL) for the computation of flight delays to resolve congestion problems in the Air Traffic Management (ATM) domain. Specifically, we aim to resolve cases where demand of airspace use exceeds capacity (demand-capacity problems), via imposing ground delays to flights at the pre-tactical stage of operations (i.e. few days to few hours before operation). Casting this into the multiagent domain, agents, representing flights, need to decide on own delays w.r.t. own preferences, having no information about others' payoffs, preferences and constraints, while they plan to execute their trajectories jointly with others, adhering to operational constraints. Specifically, we formalize the problem as a multiagent Markov Decision Process (MA-MDP) and we show that it can be considered as a Markov game in which interacting agents need to reach an equilibrium: What makes the problem more interesting is the dynamic setting in which agents operate, which is also due to the unforeseen, emergent effects of their decisions in the whole system. We propose collaborative multiagent reinforcement learning methods to resolve demand-capacity imbalances: Extensive experimental study on real-world cases, shows the potential of the proposed approaches in resolving problems, while advanced visualizations provide detailed views towards understanding the quality of solutions provided.
A Bayesian Ensemble Regression Framework on the Angry Birds Game
Aug 25, 2014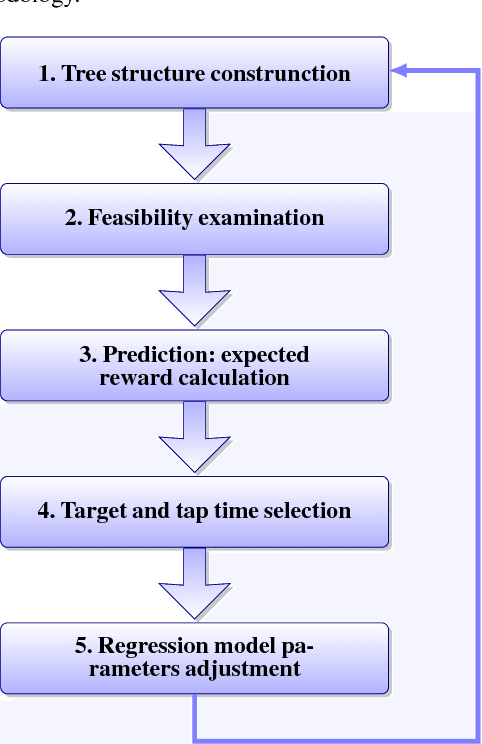
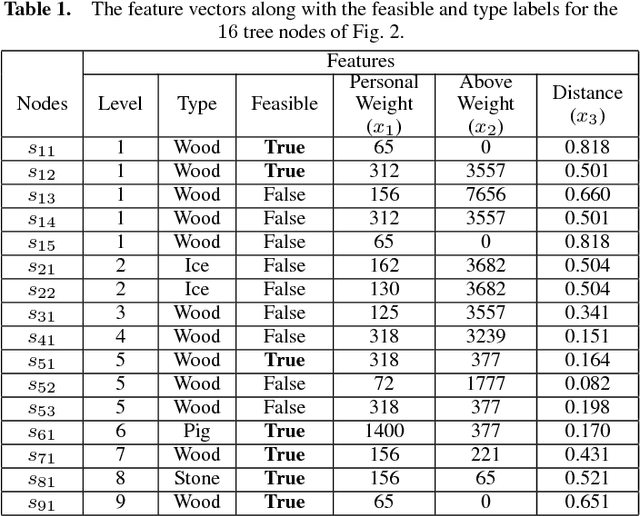
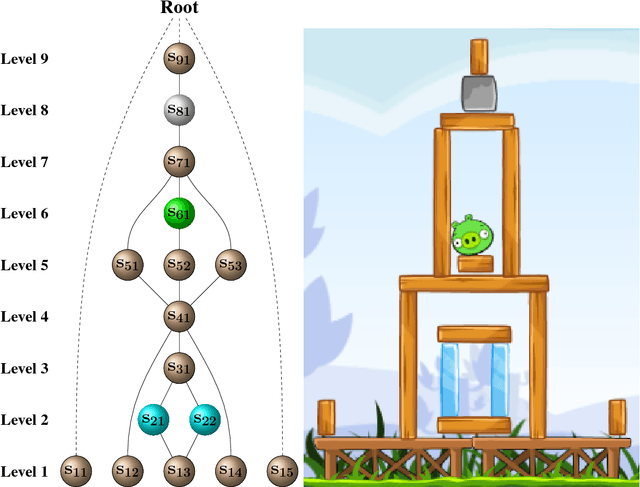
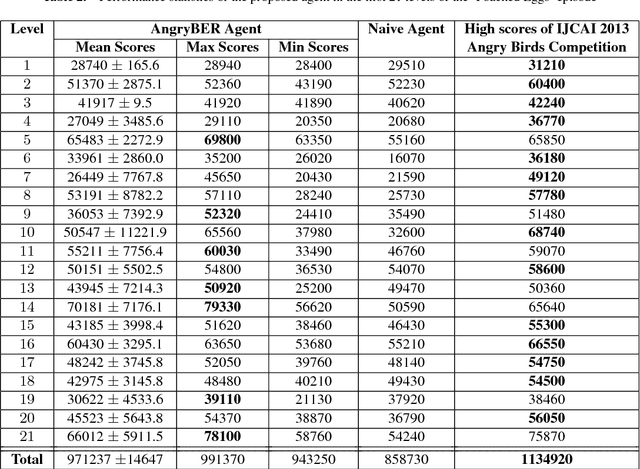
An ensemble inference mechanism is proposed on the Angry Birds domain. It is based on an efficient tree structure for encoding and representing game screenshots, where it exploits its enhanced modeling capability. This has the advantage to establish an informative feature space and modify the task of game playing to a regression analysis problem. To this direction, we assume that each type of object material and bird pair has its own Bayesian linear regression model. In this way, a multi-model regression framework is designed that simultaneously calculates the conditional expectations of several objects and makes a target decision through an ensemble of regression models. Learning procedure is performed according to an online estimation strategy for the model parameters. We provide comparative experimental results on several game levels that empirically illustrate the efficiency of the proposed methodology.
Cover Tree Bayesian Reinforcement Learning
May 02, 2014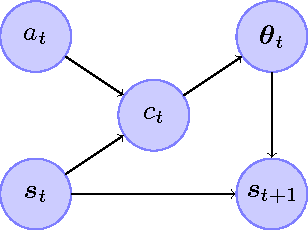
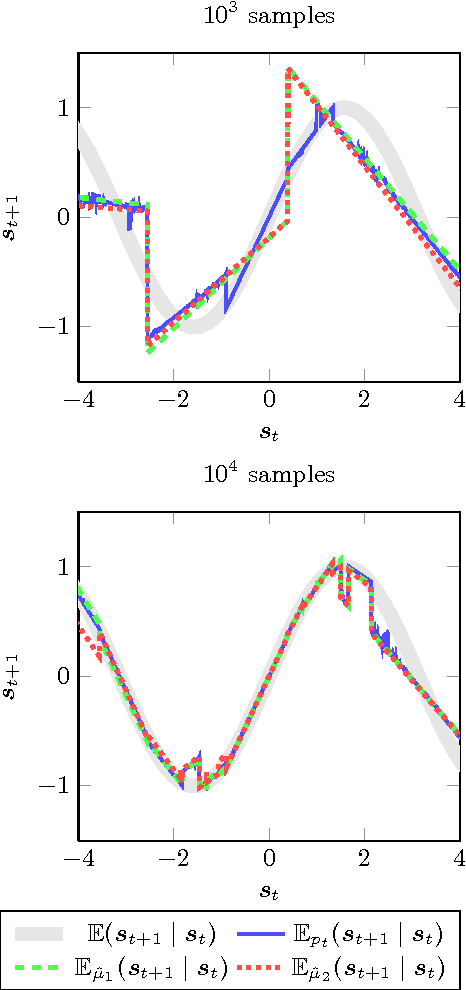
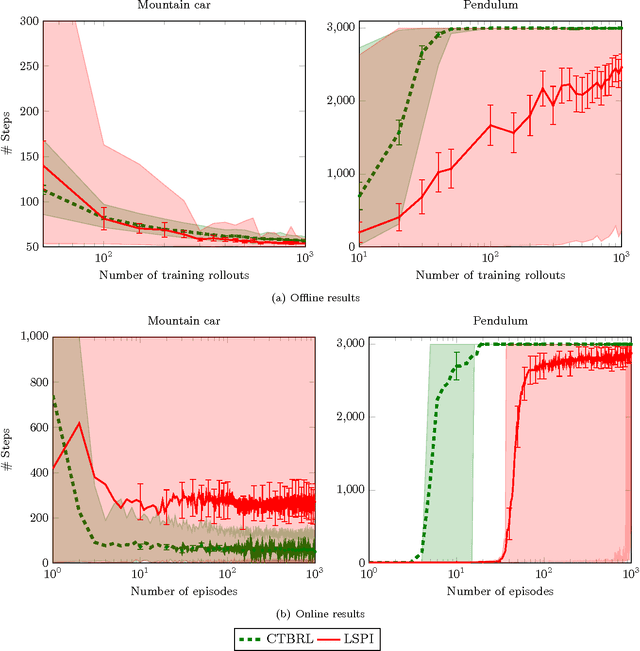
This paper proposes an online tree-based Bayesian approach for reinforcement learning. For inference, we employ a generalised context tree model. This defines a distribution on multivariate Gaussian piecewise-linear models, which can be updated in closed form. The tree structure itself is constructed using the cover tree method, which remains efficient in high dimensional spaces. We combine the model with Thompson sampling and approximate dynamic programming to obtain effective exploration policies in unknown environments. The flexibility and computational simplicity of the model render it suitable for many reinforcement learning problems in continuous state spaces. We demonstrate this in an experimental comparison with least squares policy iteration.