 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Sampling based on Local Label Imbalance
Paper and Code
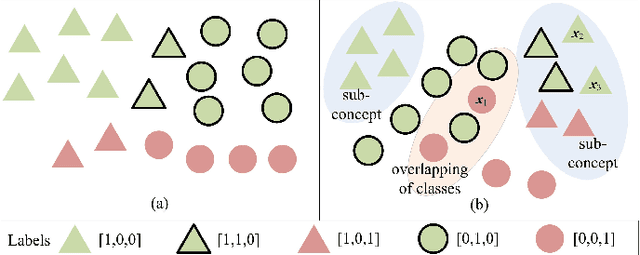


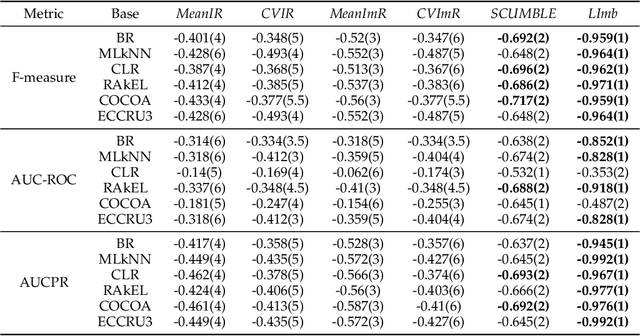
Class imbalance is an inherent characteristic of multi-label data that hinders most multi-label learning methods. One efficient and flexible strategy to deal with this problem is to employ sampling techniques before training a multi-label learning model. Although existing multi-label sampling approaches alleviate the global imbalance of multi-label datasets, it is actually the imbalance level within the local neighbourhood of minority class examples that plays a key role in performance degradation. To address this issue, we propose a novel measure to assess the local label imbalance of multi-label datasets, as well as two multi-label sampling approaches based on the local label imbalance, namely MLSOL and MLUL. By considering all informative labels, MLSOL creates more diverse and better labeled synthetic instances for difficult examples, while MLUL eliminates instances that are harmful to their local region. Experimental results on 13 multi-label datasets demonstrate the effectiveness of the proposed measure and sampling approaches for a variety of evaluation metrics, particularly in the case of an ensemble of classifiers trained on repeated samples of the original data.