 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's the Best Way to Retrieve Slides? A Comparative Study of Multimodal, Caption-Based, and Hybrid Retrieval Techniques
Sep 18, 2025Slide decks, serving as digital reports that bridge the gap between presentation slides and written documents, are a prevalent medium for conveying information in both academic and corporate settings. Their multimodal nature, combining text, images, and charts, presents challenges for retrieval-augmented generation systems, where the quality of retrieval directly impacts downstream performance. Traditional approaches to slide retrieval often involve separate indexing of modalities, which can increase complexity and lose contextual information. This paper investigates various methodologies for effective slide retrieval, including visual late-interaction embedding models like ColPali, the use of visual rerankers, and hybrid retrieval techniques that combine dense retrieval with BM25, further enhanced by textual rerankers and fusion methods like Reciprocal Rank Fusion. A novel Vision-Language Models-based captioning pipeline is also evaluated, demonstrating significantly reduced embedding storage requirements compared to visual late-interaction techniques, alongside comparable retrieval performance. Our analysis extends to the practical aspects of these methods, evaluating their runtime performance and storage demands alongside retrieval efficacy, thus offering practical guidance for the selection and development of efficient and robust slide retrieval systems for real-world applications.
Batch Selection for Multi-Label Classification Guided by Uncertainty and Dynamic Label Correlations
Dec 21, 2024



The accuracy of deep neural networks is significantly influenced by the effectiveness of mini-batch construction during training. In single-label scenarios, such as binary and multi-class classification tasks, it has been demonstrated that batch selection algorithms preferring samples with higher uncertainty achieve better performance than difficulty-based methods. Although there are two batch selection methods tailored for multi-label data, none of them leverage important uncertainty information. Adapting the concept of uncertainty to multi-label data is not a trivial task, since there are two issues that should be tackled. First, traditional variance or entropy-based uncertainty measures ignore fluctuations of predictions within sliding windows and the importance of the current model state. Second, existing multi-label methods do not explicitly exploit the label correlations, particularly the uncertainty-based label correlations that evolve during the training process. In this paper, we propose an uncertainty-based multi-label batch selection algorithm. It assesses uncertainty for each label by considering differences between successive predictions and the confidence of current outputs, and further leverages dynamic uncertainty-based label correlations to emphasize instances whose uncertainty is synergistically expressed across multiple labels. Empirical studies demonstrate the effectiveness of our method in improving the performance and accelerating the convergence of various multi-label deep learning models.
Multi-Label Adaptive Batch Selection by Highlighting Hard and Imbalanced Samples
Mar 27, 2024
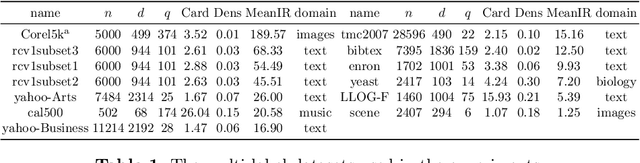

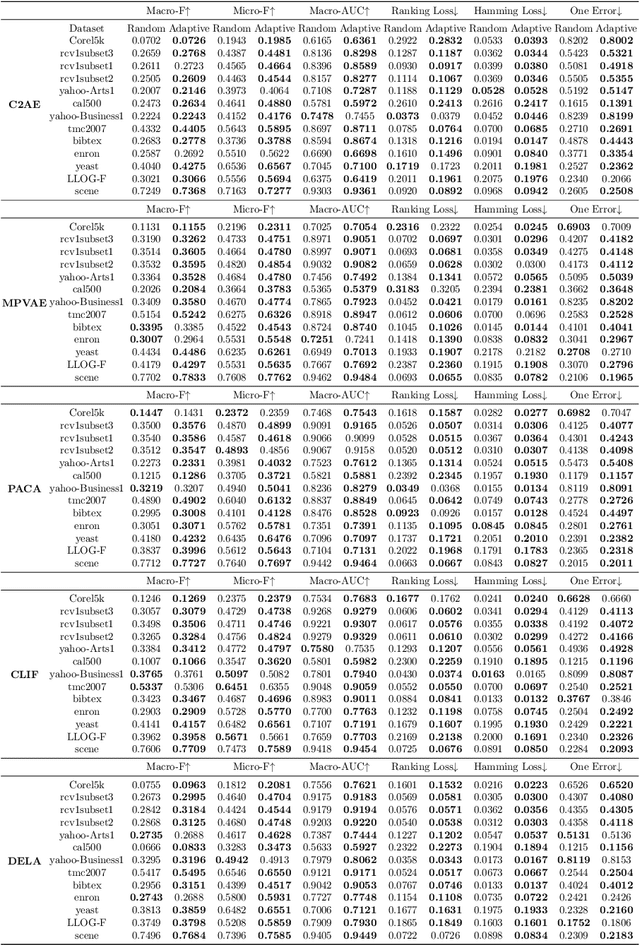
Deep neural network models have demonstrated their effectiveness in classifying multi-label data from various domains. Typically, they employ a training mode that combines mini-batches with optimizers, where each sample is randomly selected with equal probability when constructing mini-batches. However, the intrinsic class imbalance in multi-label data may bias the model towards majority labels, since samples relevant to minority labels may be underrepresented in each mini-batch. Meanwhile, during the training process, we observe that instances associated with minority labels tend to induce greater losses. Existing heuristic batch selection methods, such as priority selection of samples with high contribution to the objective function, i.e., samples with high loss, have been proven to accelerate convergence while reducing the loss and test error in single-label data. However, batch selection methods have not yet been applied and validated in multi-label data. In this study, we introduce a simple yet effective adaptive batch selection algorithm tailored to multi-label deep learning models. It adaptively selects each batch by prioritizing hard samples related to minority labels. A variant of our method also takes informative label correlations into consideration. Comprehensive experiments combining five multi-label deep learning models on thirteen benchmark datasets show that our method converges faster and performs better than random batch selection.
From Lengthy to Lucid: A Systematic Literature Review on NLP Techniques for Taming Long Sentences
Dec 08, 2023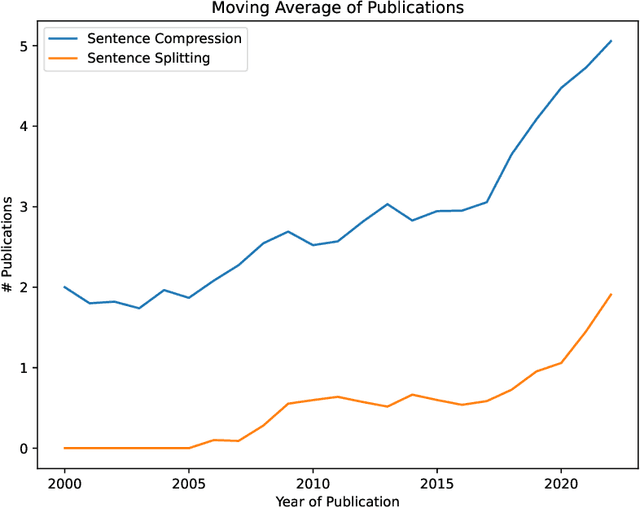
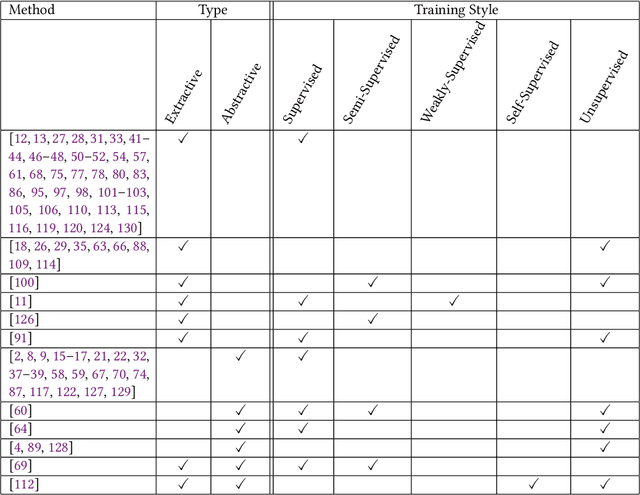
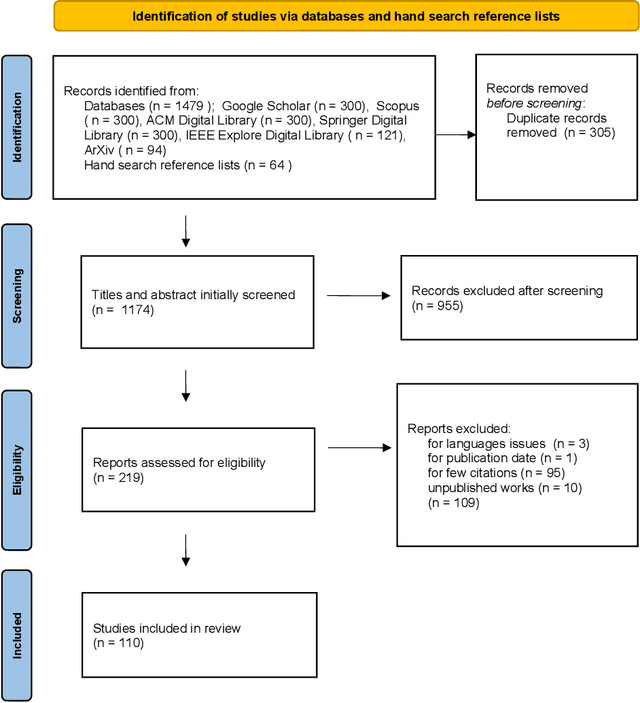
Long sentences have been a persistent issue in written communication for many years since they make it challenging for readers to grasp the main points or follow the initial intention of the writer. This survey, conducted using the PRISMA guidelines, systematically reviews two main strategies for addressing the issue of long sentences: a) sentence compression and b) sentence splitting. An increased trend of interest in this area has been observed since 2005, with significant growth after 2017. Current research is dominated by supervised approaches for both sentence compression and splitting. Yet, there is a considerable gap in weakly and self-supervised techniques, suggesting an opportunity for further research, especially in domains with limited data. In this survey, we categorize and group the most representative methods into a comprehensive taxonomy. We also conduct a comparative evaluation analysis of these methods on common sentence compression and splitting datasets. Finally, we discuss the challenges and limitations of current methods, providing valuable insights for future research directions. This survey is meant to serve as a comprehensive resource for addressing the complexities of long sentences. We aim to enable researchers to make further advancements in the field until long sentences are no longer a barrier to effective communication.
Local Interpretability of Random Forests for Multi-Target Regression
Mar 29, 2023Multi-target regression is useful in a plethora of applications. Although random forest models perform well in these tasks, they are often difficult to interpret. Interpretability is crucial in machine learning, especially when it can directly impact human well-being. Although model-agnostic techniques exist for multi-target regression, specific techniques tailored to random forest models are not available. To address this issue, we propose a technique that provides rule-based interpretations for instances made by a random forest model for multi-target regression, influenced by a recent model-specific technique for random forest interpretability. The proposed technique was evaluated through extensive experiments and shown to offer competitive interpretations compared to state-of-the-art techniques.
Does Noise Affect Housing Prices? A Case Study in the Urban Area of Thessaloniki
Feb 25, 2023Real estate markets depend on various methods to predict housing prices, including models that have been trained on datasets of residential or commercial properties. Most studies endeavor to create more accurate machine learning models by utilizing data such as basic property characteristics as well as urban features like distances from amenities and road accessibility. Even though environmental factors like noise pollution can potentially affect prices, the research around this topic is limited. One of the reasons is the lack of data. In this paper, we reconstruct and make publicly available a general purpose noise pollution dataset based on published studies conducted by the Hellenic Ministry of Environment and Energy for the city of Thessaloniki, Greece. Then, we train ensemble machine learning models, like XGBoost, on property data for different areas of Thessaloniki to investigate the way noise influences prices through interpretability evaluation techniques. Our study provides a new noise pollution dataset that not only demonstrates the impact noise has on housing prices, but also indicates that the influence of noise on prices significantly varies among different areas of the same city.
Large-scale fine-grained semantic indexing of biomedical literature based on weakly-supervised deep learning
Jan 23, 2023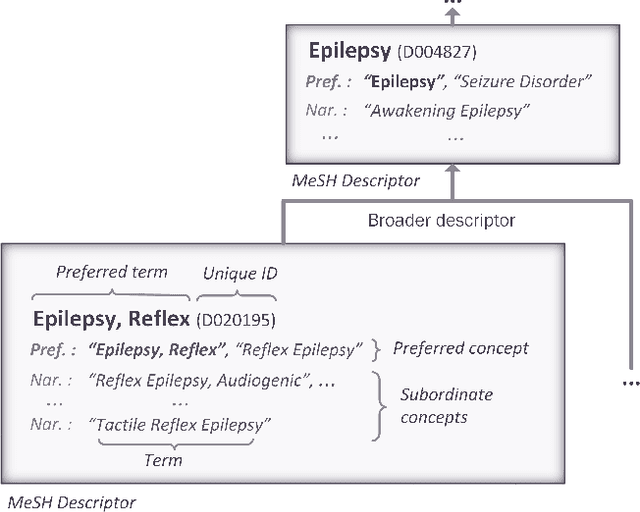
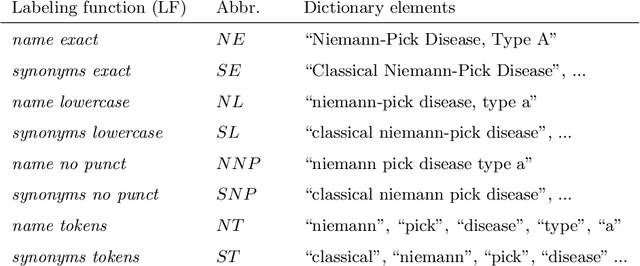
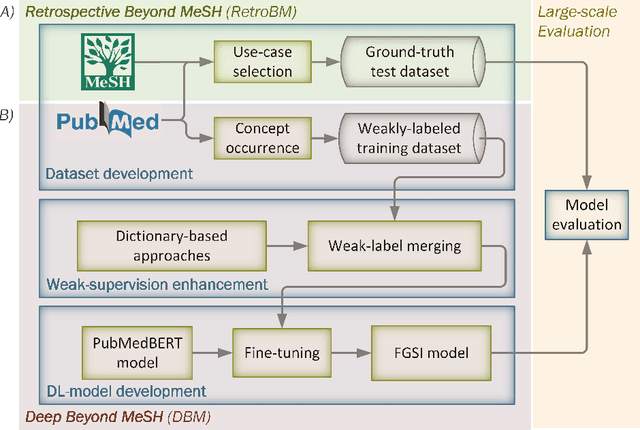
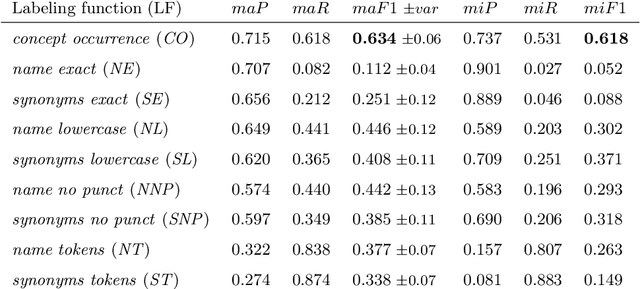
Semantic indexing of biomedical literature is usually done at the level of MeSH descriptors, representing topics of interest for the biomedical community. Several related but distinct biomedical concepts are often grouped together in a single coarse-grained descriptor and are treated as a single topic for semantic indexing. This study proposes a new method for the automated refinement of subject annotations at the level of concepts, investigating deep learning approaches. Lacking labelled data for this task, our method relies on weak supervision based on concept occurrence in the abstract of an article. The proposed approach is evaluated on an extended large-scale retrospective scenario, taking advantage of concepts that eventually become MeSH descriptors, for which annotations become available in MEDLINE/PubMed. The results suggest that concept occurrence is a strong heuristic for automated subject annotation refinement and can be further enhanced when combined with dictionary-based heuristics. In addition, such heuristics can be useful as weak supervision for developing deep learning models that can achieve further improvement in some cases.
Truthful Meta-Explanations for Local Interpretability of Machine Learning Models
Dec 07, 2022Automated Machine Learning-based systems' integration into a wide range of tasks has expanded as a result of their performance and speed. Although there are numerous advantages to employing ML-based systems, if they are not interpretable, they should not be used in critical, high-risk applications where human lives are at risk. To address this issue, researchers and businesses have been focusing on finding ways to improve the interpretability of complex ML systems, and several such methods have been developed. Indeed, there are so many developed techniques that it is difficult for practitioners to choose the best among them for their applications, even when using evaluation metrics. As a result, the demand for a selection tool, a meta-explanation technique based on a high-quality evaluation metric, is apparent. In this paper, we present a local meta-explanation technique which builds on top of the truthfulness metric, which is a faithfulness-based metric. We demonstrate the effectiveness of both the technique and the metric by concretely defining all the concepts and through experimentation.
Fine-Grained Selective Similarity Integration for Drug-Target Interaction Prediction
Dec 01, 2022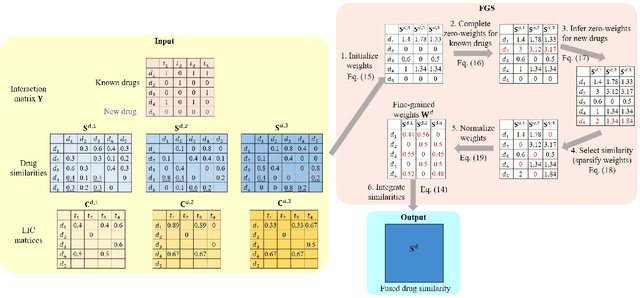

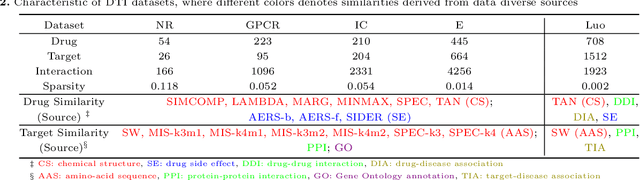
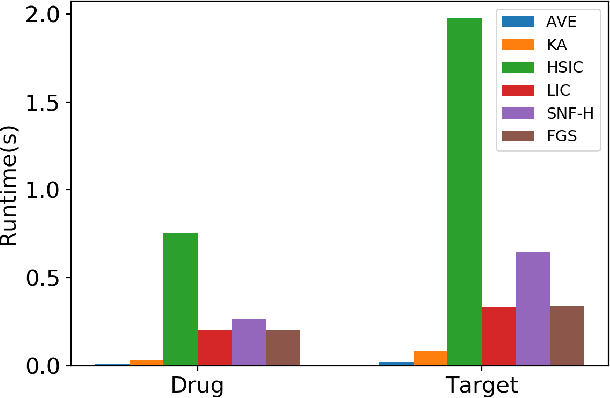
The discovery of drug-target interactions (DTIs) is a pivotal process in pharmaceutical development. Computational approaches are a promising and efficient alternative to tedious and costly wet-lab experiments for predicting novel DTIs from numerous candidates. Recently, with the availability of abundant heterogeneous biological information from diverse data sources, computational methods have been able to leverage multiple drug and target similarities to boost the performance of DTI prediction. Similarity integration is an effective and flexible strategy to extract crucial information across complementary similarity views, providing a compressed input for any similarity-based DTI prediction model. However, existing similarity integration methods filter and fuse similarities from a global perspective, neglecting the utility of similarity views for each drug and target. In this study, we propose a Fine-Grained Selective similarity integration approach, called FGS, which employs a local interaction consistency-based weight matrix to capture and exploit the importance of similarities at a finer granularity in both similarity selection and combination steps. We evaluate FGS on five DTI prediction datasets under various prediction settings. Experimental results show that our method not only outperforms similarity integration competitors with comparable computational costs, but also achieves better prediction performance than state-of-the-art DTI prediction approaches by collaborating with conventional base models. Furthermore, case studies on the analysis of similarity weights and on the verification of novel predictions confirm the practical ability of FGS.
Improving Attention-Based Interpretability of Text Classification Transformers
Sep 22, 2022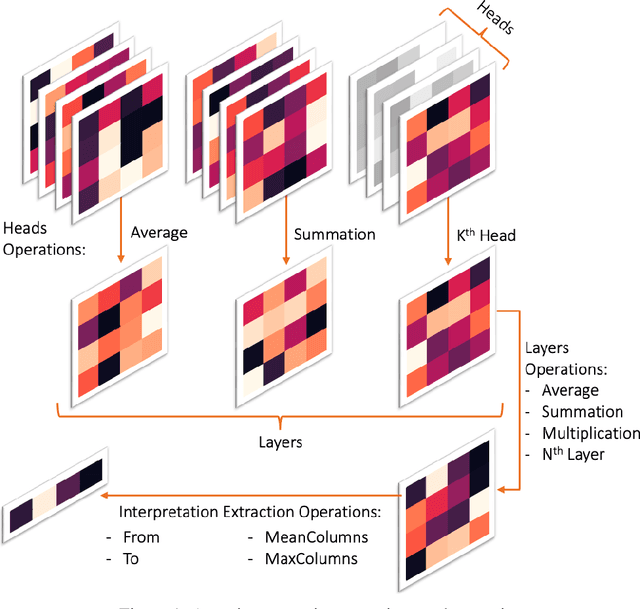
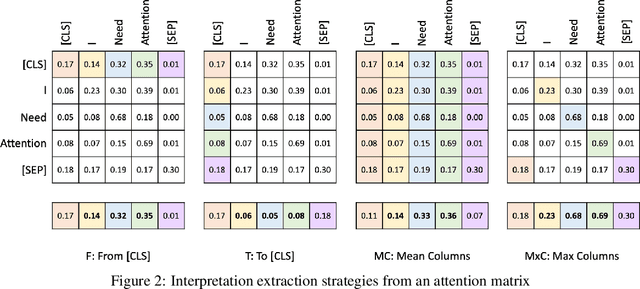
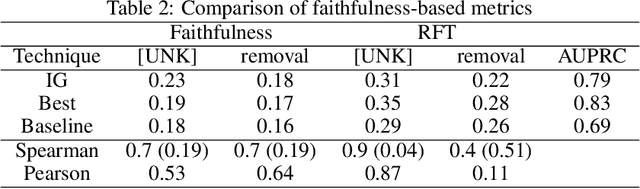
Transformers are widely used in NLP, where they consistently achieve state-of-the-art performance. This is due to their attention-based architecture, which allows them to model rich linguistic relations between words. However, transformers are difficult to interpret. Being able to provide reasoning for its decisions is an important property for a model in domains where human lives are affected, such as hate speech detection and biomedicine. With transformers finding wide use in these fields, the need for interpretability techniques tailored to them arises. The effectiveness of attention-based interpretability techniques for transformers in text classification is studied in this work. Despite concerns about attention-based interpretations in the literature, we show that, with proper setup, attention may be used in such tasks with results comparable to state-of-the-art techniques, while also being faster and friendlier to the environment. We validate our claims with a series of experiments that employ a new feature importance metric.