 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's the Best Way to Retrieve Slides? A Comparative Study of Multimodal, Caption-Based, and Hybrid Retrieval Techniques
Sep 18, 2025Slide decks, serving as digital reports that bridge the gap between presentation slides and written documents, are a prevalent medium for conveying information in both academic and corporate settings. Their multimodal nature, combining text, images, and charts, presents challenges for retrieval-augmented generation systems, where the quality of retrieval directly impacts downstream performance. Traditional approaches to slide retrieval often involve separate indexing of modalities, which can increase complexity and lose contextual information. This paper investigates various methodologies for effective slide retrieval, including visual late-interaction embedding models like ColPali, the use of visual rerankers, and hybrid retrieval techniques that combine dense retrieval with BM25, further enhanced by textual rerankers and fusion methods like Reciprocal Rank Fusion. A novel Vision-Language Models-based captioning pipeline is also evaluated, demonstrating significantly reduced embedding storage requirements compared to visual late-interaction techniques, alongside comparable retrieval performance. Our analysis extends to the practical aspects of these methods, evaluating their runtime performance and storage demands alongside retrieval efficacy, thus offering practical guidance for the selection and development of efficient and robust slide retrieval systems for real-world applications.
Multiple Similarity Drug-Target Interaction Prediction with Random Walks and Matrix Factorization
Jan 24, 2022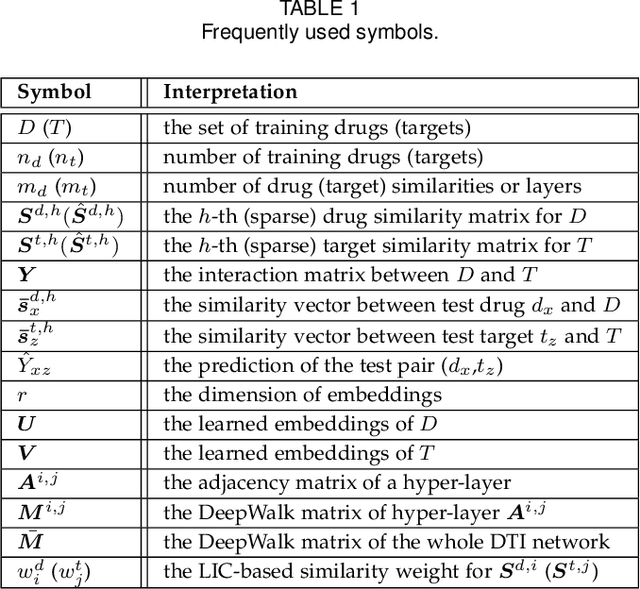

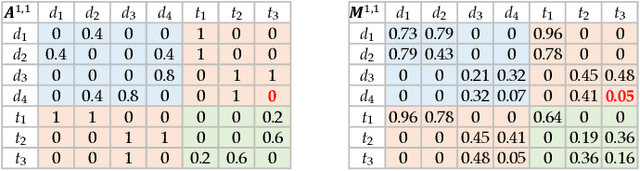
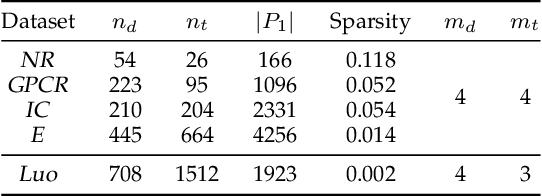
The discovery of drug-target interactions (DTIs) is a very promising area of research with great potential. In general, the identification of reliable interactions among drugs and proteins can boost the development of effective pharmaceuticals. In this work, we leverage random walks and matrix factorization techniques towards DTI prediction. In particular, we take a multi-layered network perspective, where different layers correspond to different similarity metrics between drugs and targets. To fully take advantage of topology information captured in multiple views, we develop an optimization framework, called MDMF, for DTI prediction. The framework learns vector representations of drugs and targets that not only retain higher-order proximity across all hyper-layers and layer-specific local invariance, but also approximates the interactions with their inner product. Furthermore, we propose an ensemble method, called MDMF2A, which integrates two instantiations of the MDMF model that optimize surrogate losses of the area under the precision-recall curve (AUPR) and the area under the receiver operating characteristic curve (AUC), respectively. The empirical study on real-world DTI datasets shows that our method achieves significant improvement over current state-of-the-art approaches in four different settings. Moreover, the validation of highly ranked non-interacting pairs also demonstrates the potential of MDMF2A to discover novel DTIs.
Mitigating Leakage in Federated Learning with Trusted Hardware
Nov 12, 2020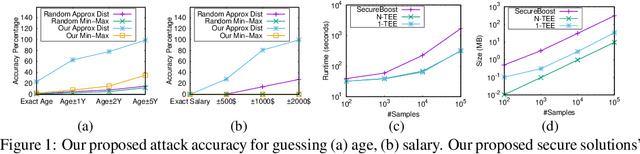
In federated learning, multiple parties collaborate in order to train a global model over their respective datasets. Even though cryptographic primitives (e.g., homomorphic encryption) can help achieve data privacy in this setting, some partial information may still be leaked across parties if this is done non-judiciously. In this work, we study the federated learning framework of SecureBoost [Cheng et al., FL@IJCAI'19] as a specific such example, demonstrate a leakage-abuse attack based on its leakage profile, and experimentally evaluate the effectiveness of our attack. We then propose two secure versions relying on trusted execution environments. We implement and benchmark our protocols to demonstrate that they are 1.2-5.4X faster in computation and need 5-49X less communication than SecureBoost.
Privacy-Preserving Hierarchical Clustering: Formal Security and Efficient Approximation
Apr 09, 2019
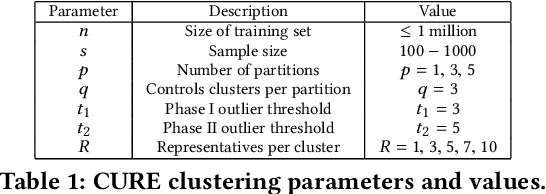

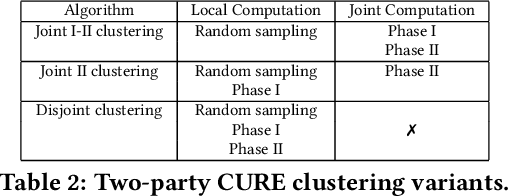
Machine Learning (ML) is widely used for predictive tasks in a number of critical applications. Recently, collaborative or federated learning is a new paradigm that enables multiple parties to jointly learn ML models on their combined datasets. Yet, in most application domains, such as healthcare and security analytics, privacy risks limit entities to individually learning local models over the sensitive datasets they own. In this work, we present the first formal study for privacy-preserving collaborative hierarchical clustering, overall featuring scalable cryptographic protocols that allow two parties to privately compute joint clusters on their combined sensitive datasets. First, we provide a formal definition that balances accuracy and privacy, and we present a provably secure protocol along with an optimized version for single linkage clustering. Second, we explore the integration of our protocol with existing approximation algorithms for hierarchical clustering, resulting in a protocol that can efficiently scale to very large datasets. Finally, we provide a prototype implementation and experimentally evaluate the feasibility and efficiency of our approach on synthetic and real datasets, with encouraging results. For example, for a dataset of one million records and 10 dimensions, our optimized privacy-preserving approximation protocol requires 35 seconds for end-to-end execution, just 896KB of communication, and achieves 97.09% accuracy.