 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Secure and Efficient Federated Learning Framework for NLP
Jan 28, 2022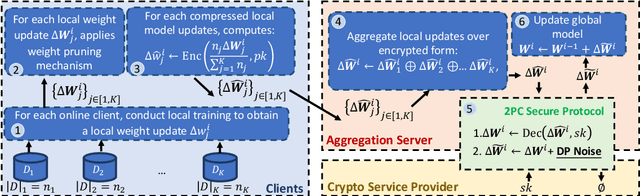
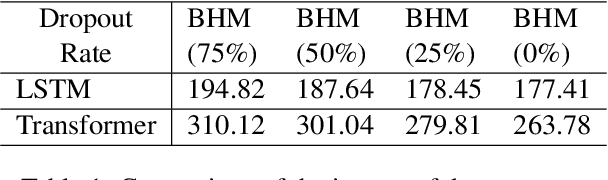
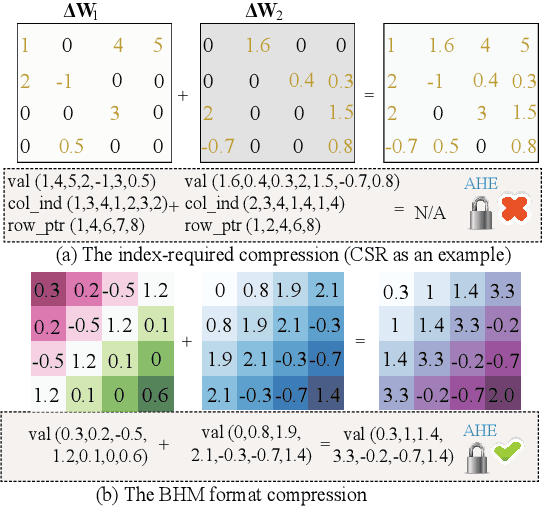
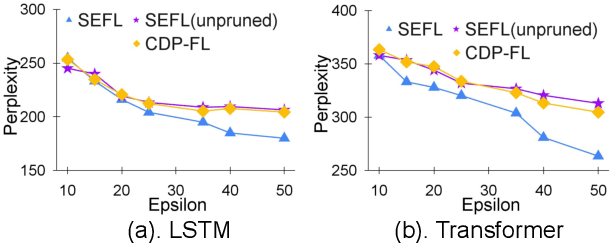
In this work, we consider the problem of designing secure and efficient federated learning (FL) frameworks. Existing solutions either involve a trusted aggregator or require heavyweight cryptographic primitives, which degrades performance significantly. Moreover, many existing secure FL designs work only under the restrictive assumption that none of the clients can be dropped out from the training protocol. To tackle these problems, we propose SEFL, a secure and efficient FL framework that (1) eliminates the need for the trusted entities; (2) achieves similar and even better model accuracy compared with existing FL designs; (3) is resilient to client dropouts. Through extensive experimental studies on natural language processing (NLP) tasks, we demonstrate that the SEFL achieves comparable accuracy compared to existing FL solutions, and the proposed pruning technique can improve runtime performance up to 13.7x.
Privacy-Preserving XGBoost Inference
Nov 13, 2020

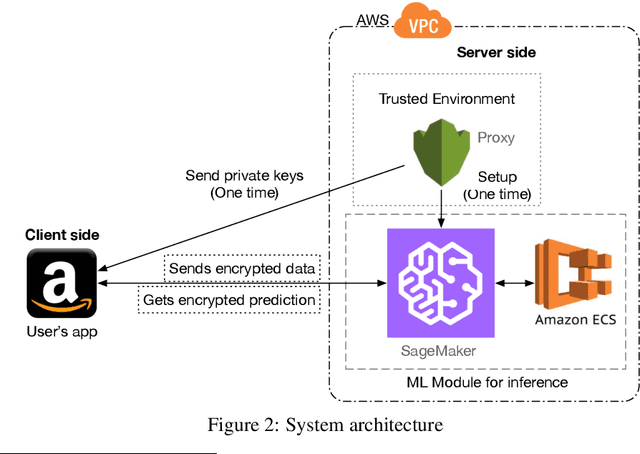
Although machine learning (ML) is widely used for predictive tasks, there are important scenarios in which ML cannot be used or at least cannot achieve its full potential. A major barrier to adoption is the sensitive nature of predictive queries. Individual users may lack sufficiently rich datasets to train accurate models locally but also be unwilling to send sensitive queries to commercial services that vend such models. One central goal of privacy-preserving machine learning (PPML) is to enable users to submit encrypted queries to a remote ML service, receive encrypted results, and decrypt them locally. We aim at developing practical solutions for real-world privacy-preserving ML inference problems. In this paper, we propose a privacy-preserving XGBoost prediction algorithm, which we have implemented and evaluated empirically on AWS SageMaker. Experimental results indicate that our algorithm is efficient enough to be used in real ML production environments.
SAPAG: A Self-Adaptive Privacy Attack From Gradients
Sep 14, 2020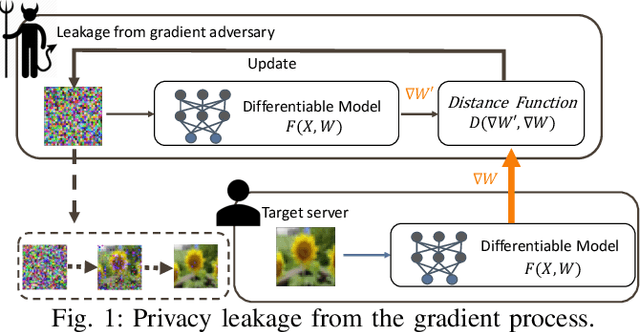

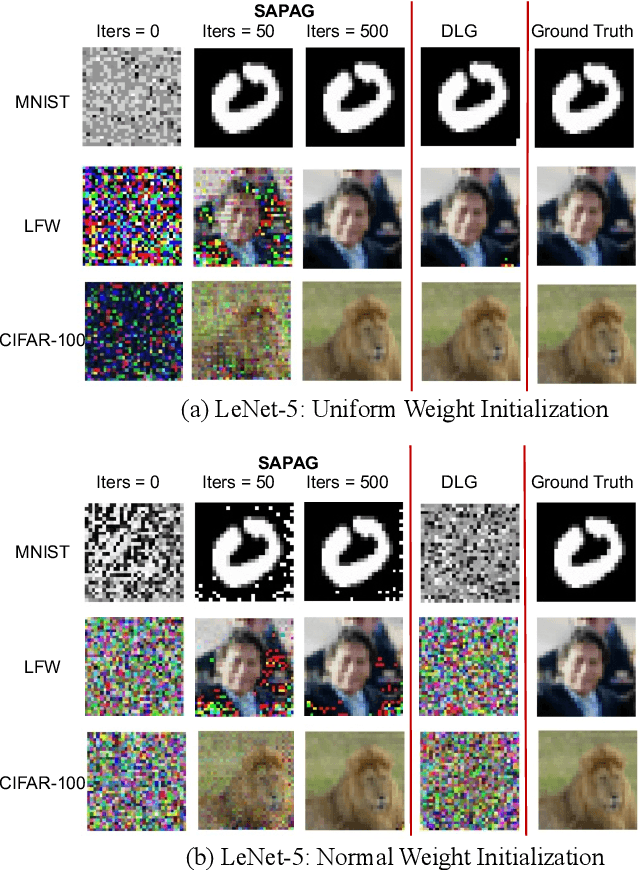
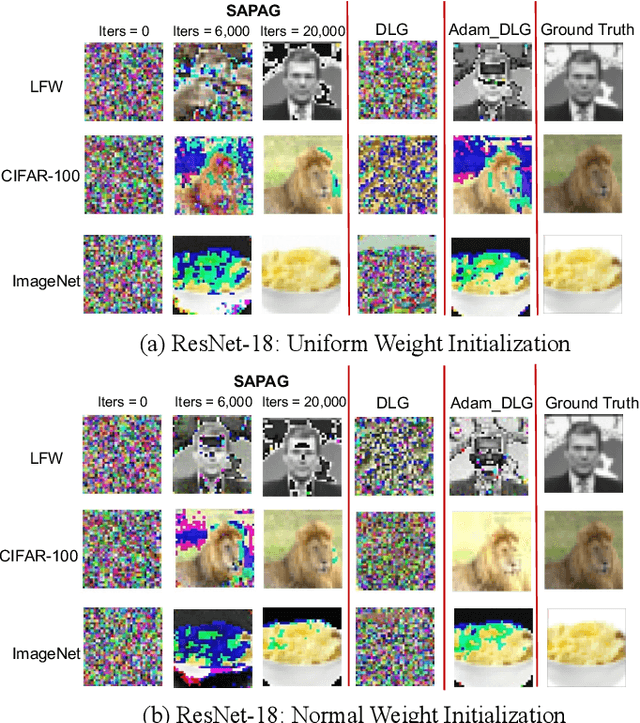
Distributed learning such as federated learning or collaborative learning enables model training on decentralized data from users and only collects local gradients, where data is processed close to its sources for data privacy. The nature of not centralizing the training data addresses the privacy issue of privacy-sensitive data. Recent studies show that a third party can reconstruct the true training data in the distributed machine learning system through the publicly-shared gradients. However, existing reconstruction attack frameworks lack generalizability on different Deep Neural Network (DNN) architectures and different weight distribution initialization, and can only succeed in the early training phase. To address these limitations, in this paper, we propose a more general privacy attack from gradient, SAPAG, which uses a Gaussian kernel based of gradient difference as a distance measure. Our experiments demonstrate that SAPAG can construct the training data on different DNNs with different weight initializations and on DNNs in any training phases.
Privacy-Preserving Hierarchical Clustering: Formal Security and Efficient Approximation
Apr 09, 2019
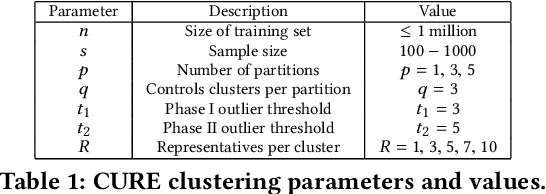

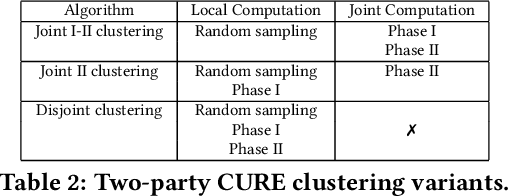
Machine Learning (ML) is widely used for predictive tasks in a number of critical applications. Recently, collaborative or federated learning is a new paradigm that enables multiple parties to jointly learn ML models on their combined datasets. Yet, in most application domains, such as healthcare and security analytics, privacy risks limit entities to individually learning local models over the sensitive datasets they own. In this work, we present the first formal study for privacy-preserving collaborative hierarchical clustering, overall featuring scalable cryptographic protocols that allow two parties to privately compute joint clusters on their combined sensitive datasets. First, we provide a formal definition that balances accuracy and privacy, and we present a provably secure protocol along with an optimized version for single linkage clustering. Second, we explore the integration of our protocol with existing approximation algorithms for hierarchical clustering, resulting in a protocol that can efficiently scale to very large datasets. Finally, we provide a prototype implementation and experimentally evaluate the feasibility and efficiency of our approach on synthetic and real datasets, with encouraging results. For example, for a dataset of one million records and 10 dimensions, our optimized privacy-preserving approximation protocol requires 35 seconds for end-to-end execution, just 896KB of communication, and achieves 97.09% accuracy.
NED: An Inter-Graph Node Metric Based On Edit Distance
Feb 16, 2016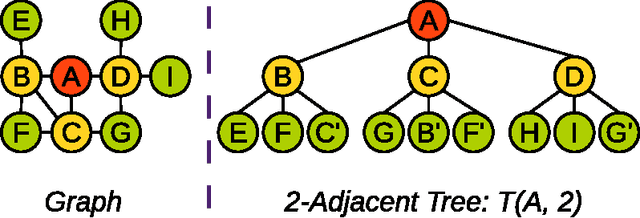

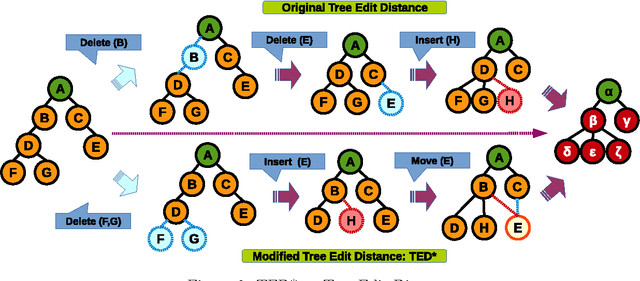
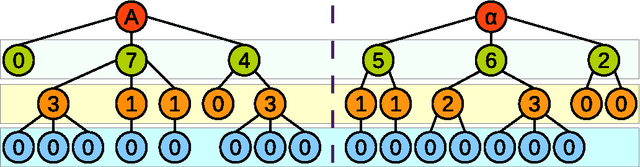
Node similarity is a fundamental problem in graph analytics. However, node similarity between nodes in different graphs (inter-graph nodes) has not received a lot of attention yet. The inter-graph node similarity is important in learning a new graph based on the knowledge of an existing graph (transfer learning on graphs) and has applications in biological, communication, and social networks. In this paper, we propose a novel distance function for measuring inter-graph node similarity with edit distance, called NED. In NED, two nodes are compared according to their local neighborhood structures which are represented as unordered k-adjacent trees, without relying on labels or other assumptions. Since the computation problem of tree edit distance on unordered trees is NP-Complete, we propose a modified tree edit distance, called TED*, for comparing neighborhood trees. TED* is a metric distance, as the original tree edit distance, but more importantly, TED* is polynomially computable. As a metric distance, NED admits efficient indexing, provides interpretable results, and shows to perform better than existing approaches on a number of data analysis tasks, including graph de-anonymization. Finally, the efficiency and effectiveness of NED are empirically demonstrated using real-world graphs.