 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe User-Centric Geo-Experience: An LLM-Powered Framework for Enhanced Planning, Navigation, and Dynamic Adaptation
Jul 09, 2025Traditional travel-planning systems are often static and fragmented, leaving them ill-equipped to handle real-world complexities such as evolving environmental conditions and unexpected itinerary disruptions. In this paper, we identify three gaps between existing service providers causing frustrating user experience: intelligent trip planning, precision "last-100-meter" navigation, and dynamic itinerary adaptation. We propose three cooperative agents: a Travel Planning Agent that employs grid-based spatial grounding and map analysis to help resolve complex multi-modal user queries; a Destination Assistant Agent that provides fine-grained guidance for the final navigation leg of each journey; and a Local Discovery Agent that leverages image embeddings and Retrieval-Augmented Generation (RAG) to detect and respond to trip plan disruptions. With evaluations and experiments, our system demonstrates substantial improvements in query interpretation, navigation accuracy, and disruption resilience, underscoring its promise for applications from urban exploration to emergency response.
Certifying Adapters: Enabling and Enhancing the Certification of Classifier Adversarial Robustness
May 25, 2024
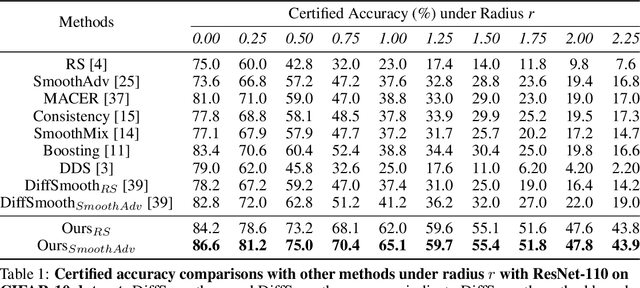
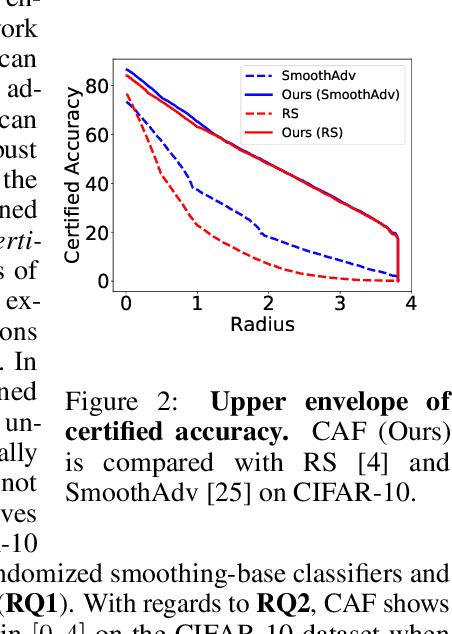

Randomized smoothing has become a leading method for achieving certified robustness in deep classifiers against l_{p}-norm adversarial perturbations. Current approaches for achieving certified robustness, such as data augmentation with Gaussian noise and adversarial training, require expensive training procedures that tune large models for different Gaussian noise levels and thus cannot leverage high-performance pre-trained neural networks. In this work, we introduce a novel certifying adapters framework (CAF) that enables and enhances the certification of classifier adversarial robustness. Our approach makes few assumptions about the underlying training algorithm or feature extractor and is thus broadly applicable to different feature extractor architectures (e.g., convolutional neural networks or vision transformers) and smoothing algorithms. We show that CAF (a) enables certification in uncertified models pre-trained on clean datasets and (b) substantially improves the performance of certified classifiers via randomized smoothing and SmoothAdv at multiple radii in CIFAR-10 and ImageNet. We demonstrate that CAF achieves improved certified accuracies when compared to methods based on random or denoised smoothing, and that CAF is insensitive to certifying adapter hyperparameters. Finally, we show that an ensemble of adapters enables a single pre-trained feature extractor to defend against a range of noise perturbation scales.
Zero-shot Generalizable Incremental Learning for Vision-Language Object Detection
Mar 04, 2024
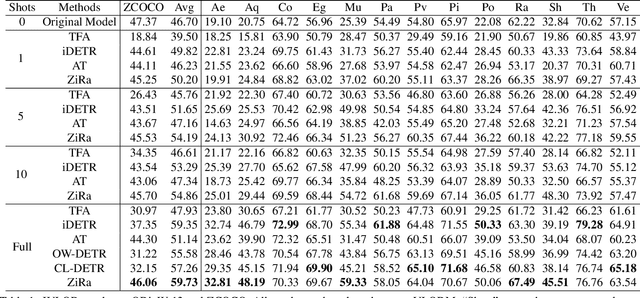
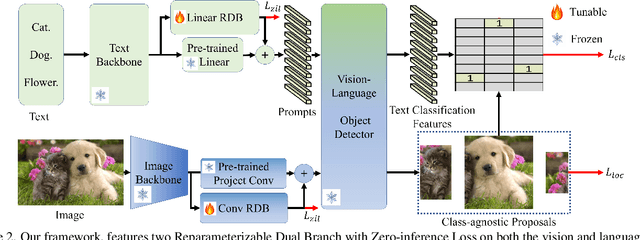

This paper presents Incremental Vision-Language Object Detection (IVLOD), a novel learning task designed to incrementally adapt pre-trained Vision-Language Object Detection Models (VLODMs) to various specialized domains, while simultaneously preserving their zero-shot generalization capabilities for the generalized domain. To address this new challenge, we present the Zero-interference Reparameterizable Adaptation (ZiRa), a novel method that introduces Zero-interference Loss and reparameterization techniques to tackle IVLOD without incurring additional inference costs or a significant increase in memory usage. Comprehensive experiments on COCO and ODinW-13 datasets demonstrate that ZiRa effectively safeguards the zero-shot generalization ability of VLODMs while continuously adapting to new tasks. Specifically, after training on ODinW-13 datasets, ZiRa exhibits superior performance compared to CL-DETR and iDETR, boosting zero-shot generalizability by substantial 13.91 and 8.71 AP, respectively.
Distilling Adversarial Robustness Using Heterogeneous Teachers
Feb 23, 2024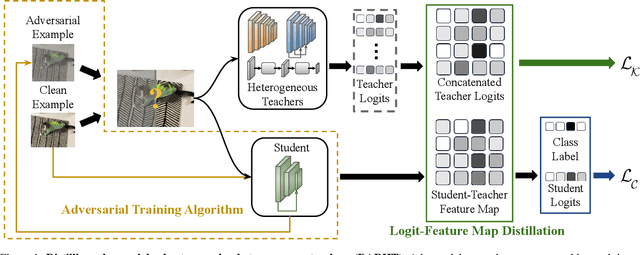
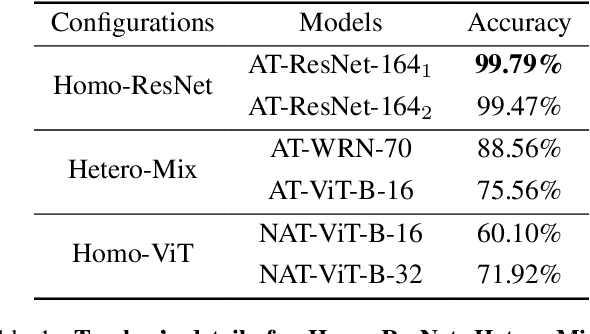
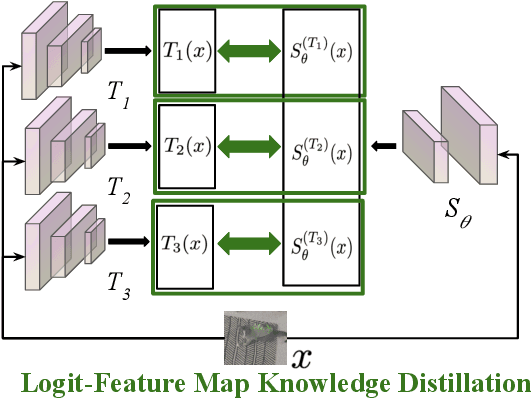
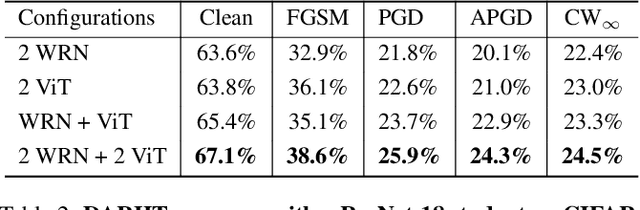
Achieving resiliency against adversarial attacks is necessary prior to deploying neural network classifiers in domains where misclassification incurs substantial costs, e.g., self-driving cars or medical imaging. Recent work has demonstrated that robustness can be transferred from an adversarially trained teacher to a student model using knowledge distillation. However, current methods perform distillation using a single adversarial and vanilla teacher and consider homogeneous architectures (i.e., residual networks) that are susceptible to misclassify examples from similar adversarial subspaces. In this work, we develop a defense framework against adversarial attacks by distilling adversarial robustness using heterogeneous teachers (DARHT). In DARHT, the student model explicitly represents teacher logits in a student-teacher feature map and leverages multiple teachers that exhibit low adversarial example transferability (i.e., exhibit high performance on dissimilar adversarial examples). Experiments on classification tasks in both white-box and black-box scenarios demonstrate that DARHT achieves state-of-the-art clean and robust accuracies when compared to competing adversarial training and distillation methods in the CIFAR-10, CIFAR-100, and Tiny ImageNet datasets. Comparisons with homogeneous and heterogeneous teacher sets suggest that leveraging teachers with low adversarial example transferability increases student model robustness.
Retrieving Conditions from Reference Images for Diffusion Models
Dec 05, 2023

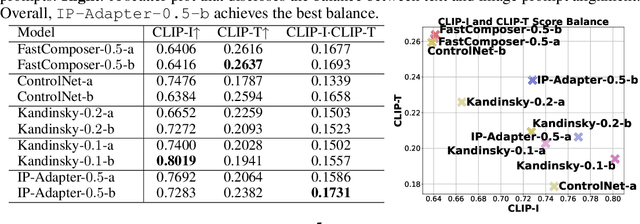

Recent diffusion-based subject driven generative methods have enabled image generations with good fidelity for specific objects or human portraits. However, to achieve better versatility for applications, we argue that not only improved datasets and evaluations are desired, but also more careful methods to retrieve only relevant information from conditional images are anticipated. To this end, we propose an anime figures dataset RetriBooru-V1, with enhanced identity and clothing labels. We state new tasks enabled by this dataset, and introduce a new diversity metric to measure success in completing these tasks, quantifying the flexibility of image generations. We establish an RAG-inspired baseline method, designed to retrieve precise conditional information from reference images. Then, we compare with current methods on existing task to demonstrate the capability of the proposed method. Finally, we provide baseline experiment results on new tasks, and conduct ablation studies on the possible structural choices.
GBSD: Generative Bokeh with Stage Diffusion
Jun 14, 2023The bokeh effect is an artistic technique that blurs out-of-focus areas in a photograph and has gained interest due to recent developments in text-to-image synthesis and the ubiquity of smart-phone cameras and photo-sharing apps. Prior work on rendering bokeh effects have focused on post hoc image manipulation to produce similar blurring effects in existing photographs using classical computer graphics or neural rendering techniques, but have either depth discontinuity artifacts or are restricted to reproducing bokeh effects that are present in the training data. More recent diffusion based models can synthesize images with an artistic style, but either require the generation of high-dimensional masks, expensive fine-tuning, or affect global image characteristics. In this paper, we present GBSD, the first generative text-to-image model that synthesizes photorealistic images with a bokeh style. Motivated by how image synthesis occurs progressively in diffusion models, our approach combines latent diffusion models with a 2-stage conditioning algorithm to render bokeh effects on semantically defined objects. Since we can focus the effect on objects, this semantic bokeh effect is more versatile than classical rendering techniques. We evaluate GBSD both quantitatively and qualitatively and demonstrate its ability to be applied in both text-to-image and image-to-image settings.
Smooth and Stepwise Self-Distillation for Object Detection
Mar 09, 2023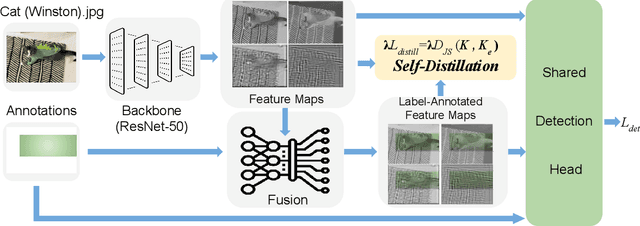
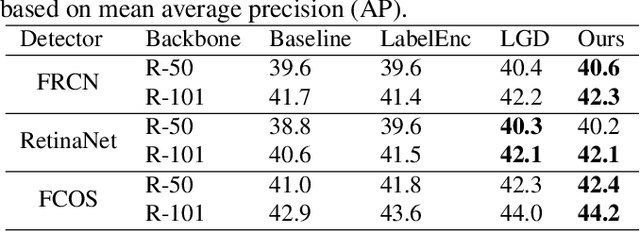
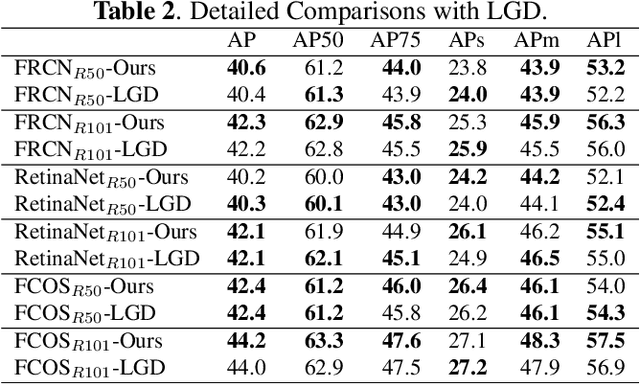
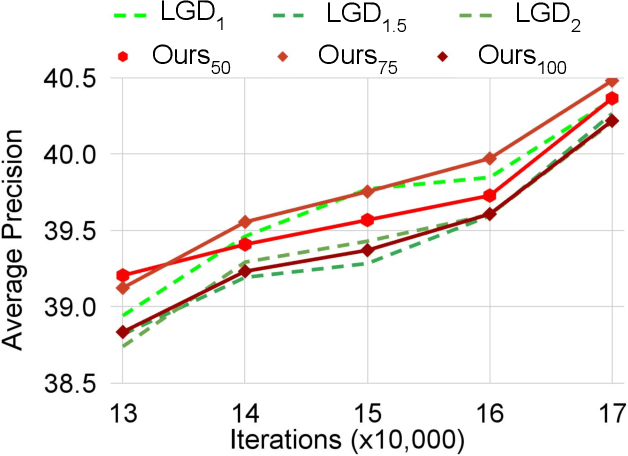
Distilling the structured information captured in feature maps has contributed to improved results for object detection tasks, but requires careful selection of baseline architectures and substantial pre-training. Self-distillation addresses these limitations and has recently achieved state-of-the-art performance for object detection despite making several simplifying architectural assumptions. Building on this work, we propose Smooth and Stepwise Self-Distillation (SSSD) for object detection. Our SSSD architecture forms an implicit teacher from object labels and a feature pyramid network backbone to distill label-annotated feature maps using Jensen-Shannon distance, which is smoother than distillation losses used in prior work. We additionally add a distillation coefficient that is adaptively configured based on the learning rate. We extensively benchmark SSSD against a baseline and two state-of-the-art object detector architectures on the COCO dataset by varying the coefficients and backbone and detector networks. We demonstrate that SSSD achieves higher average precision in most experimental settings, is robust to a wide range of coefficients, and benefits from our stepwise distillation procedure.
Incremental Prototype Prompt-tuning with Pre-trained Representation for Class Incremental Learning
Apr 11, 2022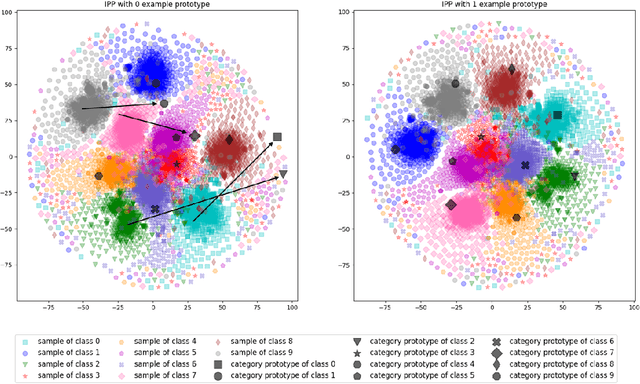
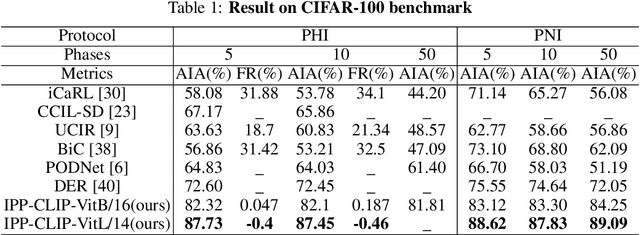
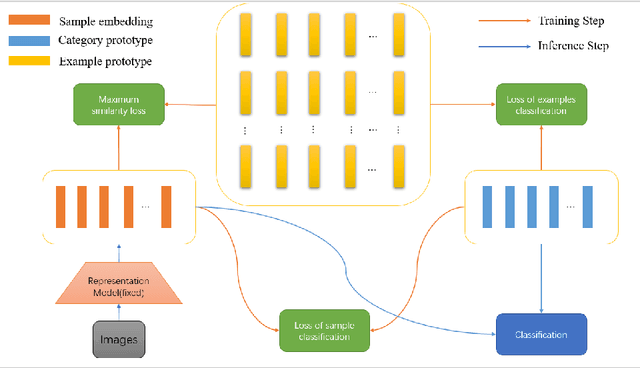
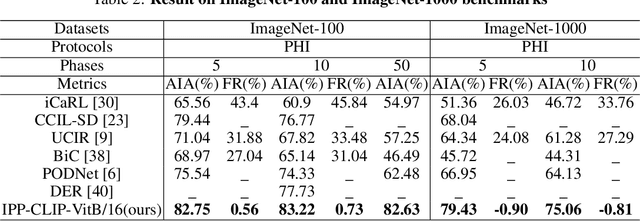
Class incremental learning has attracted much attention, but most existing works still continually fine-tune the representation model, resulting in much catastrophic forgetting. Instead of struggling to fight against such forgetting by replaying or distillation like most of the existing methods, we take the pre-train-and-prompt-tuning paradigm to sequentially learn new visual concepts based on a fixed semantic rich pre-trained representation model by incremental prototype prompt-tuning (IPP), which substantially reduces the catastrophic forgetting. In addition, an example prototype classification is proposed to compensate for semantic drift, the problem caused by learning bias at different phases. Extensive experiments conducted on the three incremental learning benchmarks demonstrate that our method consistently outperforms other state-of-the-art methods with a large margin.
A Secure and Efficient Federated Learning Framework for NLP
Jan 28, 2022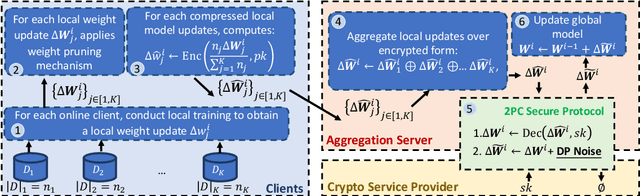
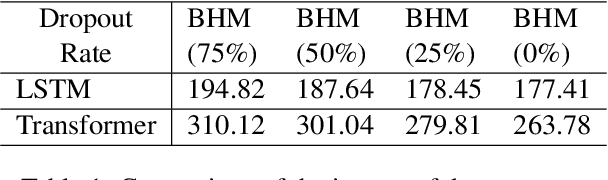
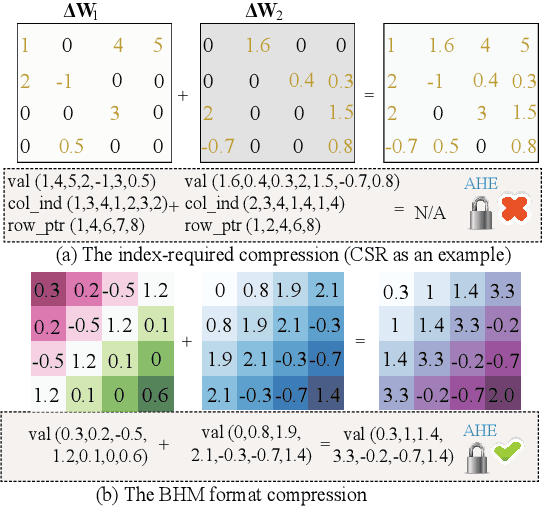
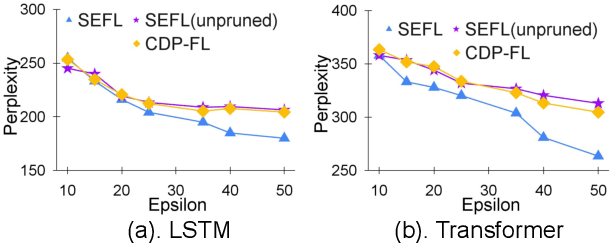
In this work, we consider the problem of designing secure and efficient federated learning (FL) frameworks. Existing solutions either involve a trusted aggregator or require heavyweight cryptographic primitives, which degrades performance significantly. Moreover, many existing secure FL designs work only under the restrictive assumption that none of the clients can be dropped out from the training protocol. To tackle these problems, we propose SEFL, a secure and efficient FL framework that (1) eliminates the need for the trusted entities; (2) achieves similar and even better model accuracy compared with existing FL designs; (3) is resilient to client dropouts. Through extensive experimental studies on natural language processing (NLP) tasks, we demonstrate that the SEFL achieves comparable accuracy compared to existing FL solutions, and the proposed pruning technique can improve runtime performance up to 13.7x.
Enabling Super-Fast Deep Learning on Tiny Energy-Harvesting IoT Devices
Nov 28, 2021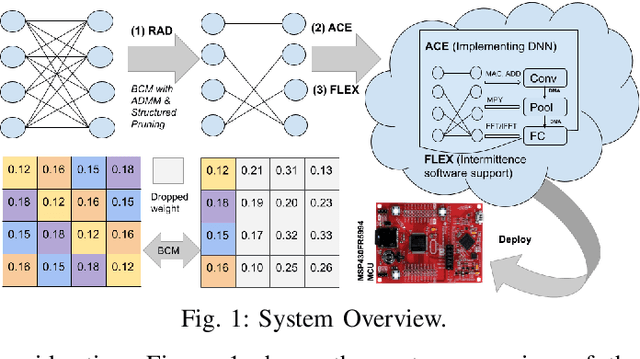
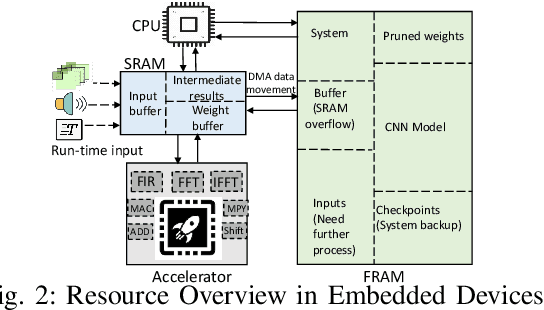
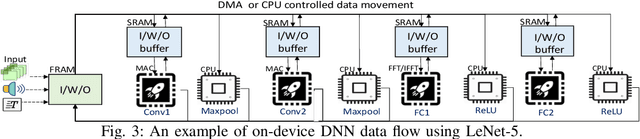
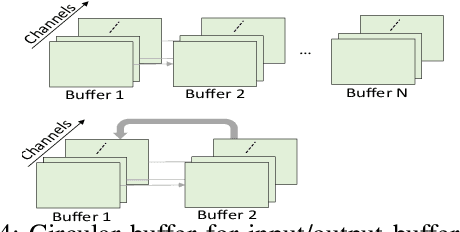
Energy harvesting (EH) IoT devices that operate intermittently without batteries, coupled with advances in deep neural networks (DNNs), have opened up new opportunities for enabling sustainable smart applications. Nevertheless, implementing those computation and memory-intensive intelligent algorithms on EH devices is extremely difficult due to the challenges of limited resources and intermittent power supply that causes frequent failures. To address those challenges, this paper proposes a methodology that enables super-fast deep learning with low-energy accelerators for tiny energy harvesting devices. We first propose RAD, a resource-aware structured DNN training framework, which employs block circulant matrix with ADMM to achieve high compression and model quantization for leveraging the advantage of various vector operation accelerators. A DNN implementation method, ACE, is then proposed that employs low-energy accelerators to profit maximum performance with minor energy consumption. Finally, we further design FLEX, the system support for intermittent computation in energy harvesting situations. Experimental results from three different DNN models demonstrate that RAD, ACE, and FLEX can enable super-fast and correct inference on energy harvesting devices with up to 4.26X runtime reduction, up to 7.7X energy reduction with higher accuracy over the state-of-the-art.