 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeware Untrusted Simulators -- Reward-Free Backdoor Attacks in Reinforcement Learning
Feb 04, 2026Simulated environments are a key piece in the success of Reinforcement Learning (RL), allowing practitioners and researchers to train decision making agents without running expensive experiments on real hardware. Simulators remain a security blind spot, however, enabling adversarial developers to alter the dynamics of their released simulators for malicious purposes. Therefore, in this work we highlight a novel threat, demonstrating how simulator dynamics can be exploited to stealthily implant action-level backdoors into RL agents. The backdoor then allows an adversary to reliably activate targeted actions in an agent upon observing a predefined ``trigger'', leading to potentially dangerous consequences. Traditional backdoor attacks are limited in their strong threat models, assuming the adversary has near full control over an agent's training pipeline, enabling them to both alter and observe agent's rewards. As these assumptions are infeasible to implement within a simulator, we propose a new attack ``Daze'' which is able to reliably and stealthily implant backdoors into RL agents trained for real world tasks without altering or even observing their rewards. We provide formal proof of Daze's effectiveness in guaranteeing attack success across general RL tasks along with extensive empirical evaluations on both discrete and continuous action space domains. We additionally provide the first example of RL backdoor attacks transferring to real, robotic hardware. These developments motivate further research into securing all components of the RL training pipeline to prevent malicious attacks.
Busting the Paper Ballot: Voting Meets Adversarial Machine Learning
Jun 17, 2025
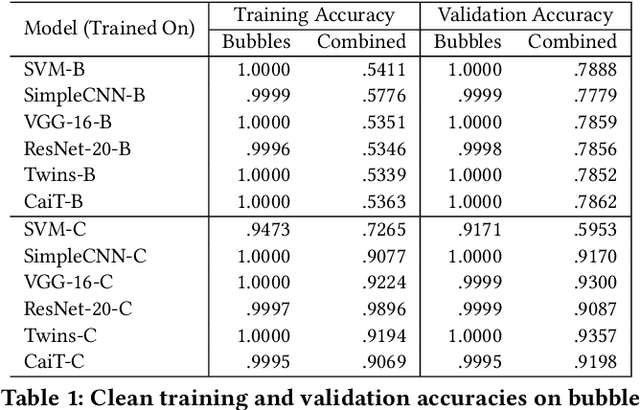

We show the security risk associated with using machine learning classifiers in United States election tabulators. The central classification task in election tabulation is deciding whether a mark does or does not appear on a bubble associated to an alternative in a contest on the ballot. Barretto et al. (E-Vote-ID 2021) reported that convolutional neural networks are a viable option in this field, as they outperform simple feature-based classifiers. Our contributions to election security can be divided into four parts. To demonstrate and analyze the hypothetical vulnerability of machine learning models on election tabulators, we first introduce four new ballot datasets. Second, we train and test a variety of different models on our new datasets. These models include support vector machines, convolutional neural networks (a basic CNN, VGG and ResNet), and vision transformers (Twins and CaiT). Third, using our new datasets and trained models, we demonstrate that traditional white box attacks are ineffective in the voting domain due to gradient masking. Our analyses further reveal that gradient masking is a product of numerical instability. We use a modified difference of logits ratio loss to overcome this issue (Croce and Hein, ICML 2020). Fourth, in the physical world, we conduct attacks with the adversarial examples generated using our new methods. In traditional adversarial machine learning, a high (50% or greater) attack success rate is ideal. However, for certain elections, even a 5% attack success rate can flip the outcome of a race. We show such an impact is possible in the physical domain. We thoroughly discuss attack realism, and the challenges and practicality associated with printing and scanning ballot adversarial examples.
Adversarial Inception for Bounded Backdoor Poisoning in Deep Reinforcement Learning
Oct 21, 2024Recent works have demonstrated the vulnerability of Deep Reinforcement Learning (DRL) algorithms against training-time, backdoor poisoning attacks. These attacks induce pre-determined, adversarial behavior in the agent upon observing a fixed trigger during deployment while allowing the agent to solve its intended task during training. Prior attacks rely on arbitrarily large perturbations to the agent's rewards to achieve both of these objectives - leaving them open to detection. Thus, in this work, we propose a new class of backdoor attacks against DRL which achieve state of the art performance while minimally altering the agent's rewards. These "inception" attacks train the agent to associate the targeted adversarial behavior with high returns by inducing a disjunction between the agent's chosen action and the true action executed in the environment during training. We formally define these attacks and prove they can achieve both adversarial objectives. We then devise an online inception attack which significantly out-performs prior attacks under bounded reward constraints.
SleeperNets: Universal Backdoor Poisoning Attacks Against Reinforcement Learning Agents
May 30, 2024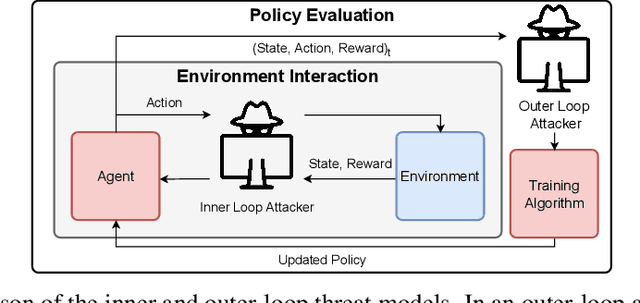

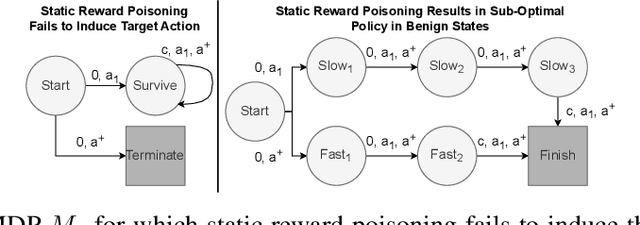
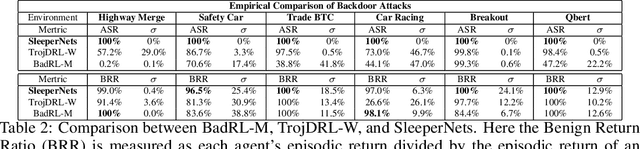
Reinforcement learning (RL) is an actively growing field that is seeing increased usage in real-world, safety-critical applications -- making it paramount to ensure the robustness of RL algorithms against adversarial attacks. In this work we explore a particularly stealthy form of training-time attacks against RL -- backdoor poisoning. Here the adversary intercepts the training of an RL agent with the goal of reliably inducing a particular action when the agent observes a pre-determined trigger at inference time. We uncover theoretical limitations of prior work by proving their inability to generalize across domains and MDPs. Motivated by this, we formulate a novel poisoning attack framework which interlinks the adversary's objectives with those of finding an optimal policy -- guaranteeing attack success in the limit. Using insights from our theoretical analysis we develop ``SleeperNets'' as a universal backdoor attack which exploits a newly proposed threat model and leverages dynamic reward poisoning techniques. We evaluate our attack in 6 environments spanning multiple domains and demonstrate significant improvements in attack success over existing methods, while preserving benign episodic return.
Distilling Adversarial Robustness Using Heterogeneous Teachers
Feb 23, 2024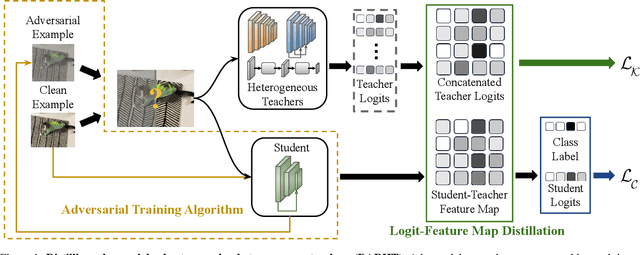
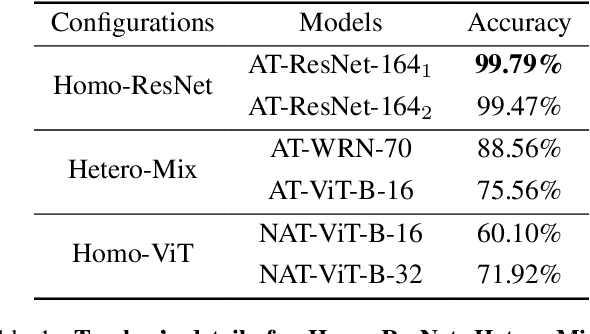
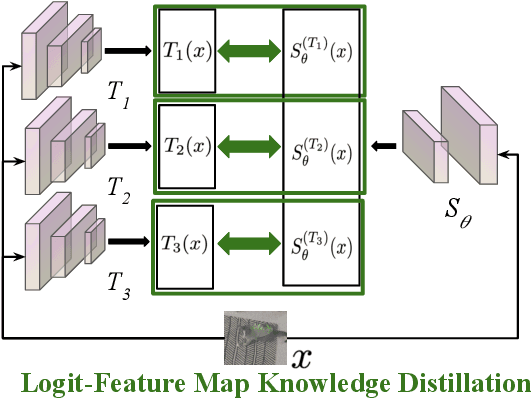
Achieving resiliency against adversarial attacks is necessary prior to deploying neural network classifiers in domains where misclassification incurs substantial costs, e.g., self-driving cars or medical imaging. Recent work has demonstrated that robustness can be transferred from an adversarially trained teacher to a student model using knowledge distillation. However, current methods perform distillation using a single adversarial and vanilla teacher and consider homogeneous architectures (i.e., residual networks) that are susceptible to misclassify examples from similar adversarial subspaces. In this work, we develop a defense framework against adversarial attacks by distilling adversarial robustness using heterogeneous teachers (DARHT). In DARHT, the student model explicitly represents teacher logits in a student-teacher feature map and leverages multiple teachers that exhibit low adversarial example transferability (i.e., exhibit high performance on dissimilar adversarial examples). Experiments on classification tasks in both white-box and black-box scenarios demonstrate that DARHT achieves state-of-the-art clean and robust accuracies when compared to competing adversarial training and distillation methods in the CIFAR-10, CIFAR-100, and Tiny ImageNet datasets. Comparisons with homogeneous and heterogeneous teacher sets suggest that leveraging teachers with low adversarial example transferability increases student model robustness.
Game Theoretic Mixed Experts for Combinational Adversarial Machine Learning
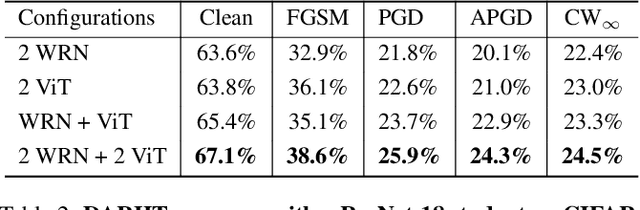
Nov 26, 2022Recent advances in adversarial machine learning have shown that defenses considered to be robust are actually susceptible to adversarial attacks which are specifically tailored to target their weaknesses. These defenses include Barrage of Random Transforms (BaRT), Friendly Adversarial Training (FAT), Trash is Treasure (TiT) and ensemble models made up of Vision Transformers (ViTs), Big Transfer models and Spiking Neural Networks (SNNs). A natural question arises: how can one best leverage a combination of adversarial defenses to thwart such attacks? In this paper, we provide a game-theoretic framework for ensemble adversarial attacks and defenses which answers this question. In addition to our framework we produce the first adversarial defense transferability study to further motivate a need for combinational defenses utilizing a diverse set of defense architectures. Our framework is called Game theoretic Mixed Experts (GaME) and is designed to find the Mixed-Nash strategy for a defender when facing an attacker employing compositional adversarial attacks. We show that this framework creates an ensemble of defenses with greater robustness than multiple state-of-the-art, single-model defenses in addition to combinational defenses with uniform probability distributions. Overall, our framework and analyses advance the field of adversarial machine learning by yielding new insights into compositional attack and defense formulations.
Securing the Spike: On the Transferabilty and Security of Spiking Neural Networks to Adversarial Examples
Sep 07, 2022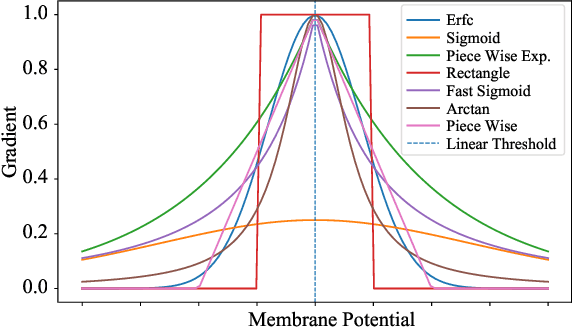
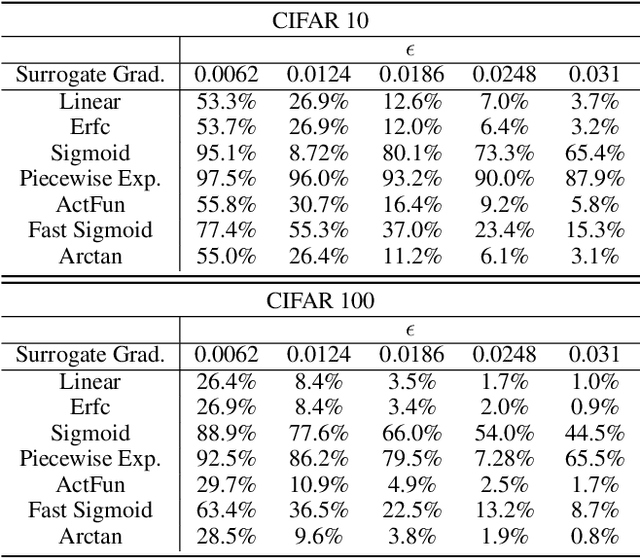
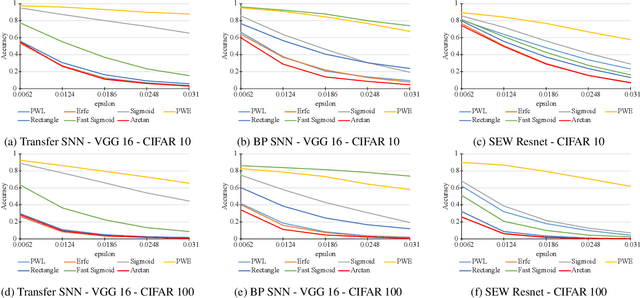
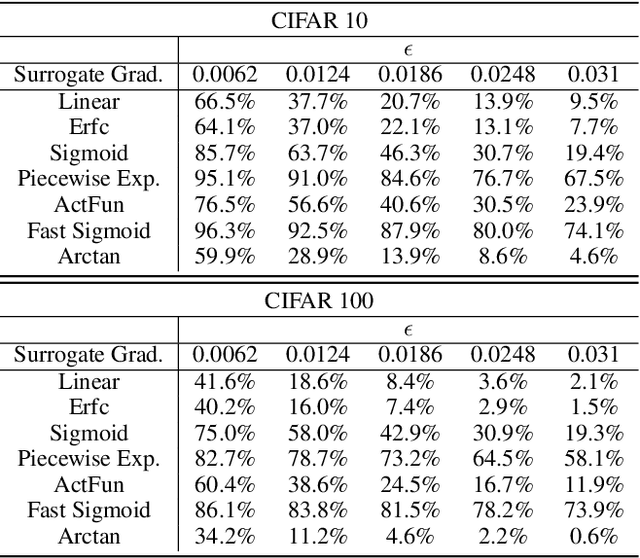
Spiking neural networks (SNNs) have attracted much attention for their high energy efficiency and for recent advances in their classification performance. However, unlike traditional deep learning approaches, the analysis and study of the robustness of SNNs to adversarial examples remains relatively underdeveloped. In this work we advance the field of adversarial machine learning through experimentation and analyses of three important SNN security attributes. First, we show that successful white-box adversarial attacks on SNNs are highly dependent on the underlying surrogate gradient technique. Second, we analyze the transferability of adversarial examples generated by SNNs and other state-of-the-art architectures like Vision Transformers and Big Transfer CNNs. We demonstrate that SNNs are not often deceived by adversarial examples generated by Vision Transformers and certain types of CNNs. Lastly, we develop a novel white-box attack that generates adversarial examples capable of fooling both SNN models and non-SNN models simultaneously. Our experiments and analyses are broad and rigorous covering two datasets (CIFAR-10 and CIFAR-100), five different white-box attacks and twelve different classifier models.
Back in Black: A Comparative Evaluation of Recent State-Of-The-Art Black-Box Attacks
Sep 29, 2021
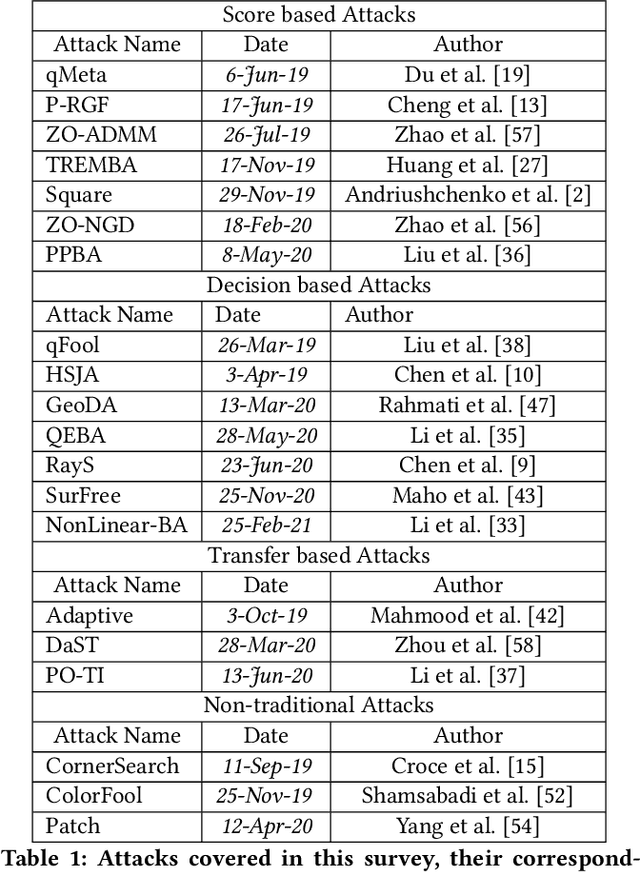
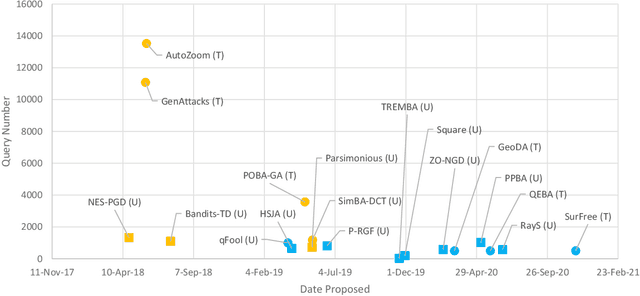

The field of adversarial machine learning has experienced a near exponential growth in the amount of papers being produced since 2018. This massive information output has yet to be properly processed and categorized. In this paper, we seek to help alleviate this problem by systematizing the recent advances in adversarial machine learning black-box attacks since 2019. Our survey summarizes and categorizes 20 recent black-box attacks. We also present a new analysis for understanding the attack success rate with respect to the adversarial model used in each paper. Overall, our paper surveys a wide body of literature to highlight recent attack developments and organizes them into four attack categories: score based attacks, decision based attacks, transfer attacks and non-traditional attacks. Further, we provide a new mathematical framework to show exactly how attack results can fairly be compared.