 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenization and Morphological Fidelity in Uralic NLP: A Cross-Lingual Evaluation
Feb 04, 2026Subword tokenization critically affects Natural Language Processing (NLP) performance, yet its behavior in morphologically rich and low-resource language families remains under-explored. This study systematically compares three subword paradigms -- Byte Pair Encoding (BPE), Overlap BPE (OBPE), and Unigram Language Model -- across six Uralic languages with varying resource availability and typological diversity. Using part-of-speech (POS) tagging as a controlled downstream task, we show that OBPE consistently achieves stronger morphological alignment and higher tagging accuracy than conventional methods, particularly within the Latin-script group. These gains arise from reduced fragmentation in open-class categories and a better balance across the frequency spectrum. Transfer efficacy further depends on the downstream tagging architecture, interacting with both training volume and genealogical proximity. Taken together, these findings highlight that morphology-sensitive tokenization is not merely a preprocessing choice but a decisive factor in enabling effective cross-lingual transfer for agglutinative, low-resource languages.
PPL: Point Cloud Supervised Proprioceptive Locomotion Reinforcement Learning for Legged Robots in Crawl Spaces
Aug 13, 2025The legged locomotion in spatially constrained structures (called crawl spaces) is challenging. In crawl spaces, current exteroceptive locomotion learning methods are limited by large noises and errors of the sensors in possible low visibility conditions, and current proprioceptive locomotion learning methods are difficult in traversing crawl spaces because only ground features are inferred. In this study, a point cloud supervised proprioceptive locomotion reinforcement learning method for legged robots in crawl spaces is proposed. A state estimation network is designed to estimate the robot's surrounding ground and spatial features as well as the robot's collision states using historical proprioceptive sensor data. The point cloud is represented in polar coordinate frame and a point cloud processing method is proposed to efficiently extract the ground and spatial features that are used to supervise the state estimation network learning. Comprehensive reward functions that guide the robot to traverse through crawl spaces after collisions are designed. Experiments demonstrate that, compared to existing methods, our method exhibits more agile locomotion in crawl spaces. This study enhances the ability of legged robots to traverse spatially constrained environments without requiring exteroceptive sensors.
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
LaPON: A Lagrange's-mean-value-theorem-inspired operator network for solving PDEs and its application on NSE
May 18, 2025Accelerating the solution of nonlinear partial differential equations (PDEs) while maintaining accuracy at coarse spatiotemporal resolution remains a key challenge in scientific computing. Physics-informed machine learning (ML) methods such as Physics-Informed Neural Networks (PINNs) introduce prior knowledge through loss functions to ensure physical consistency, but their "soft constraints" are usually not strictly satisfied. Here, we propose LaPON, an operator network inspired by the Lagrange's mean value theorem, which embeds prior knowledge directly into the neural network architecture instead of the loss function, making the neural network naturally satisfy the given constraints. This is a hybrid framework that combines neural operators with traditional numerical methods, where neural operators are used to compensate for the effect of discretization errors on the analytical scale in under-resolution simulations. As evaluated on turbulence problem modeled by the Navier-Stokes equations (NSE), the multiple time step extrapolation accuracy and stability of LaPON exceed the direct numerical simulation baseline at 8x coarser grids and 8x larger time steps, while achieving a vorticity correlation of more than 0.98 with the ground truth. It is worth noting that the model can be well generalized to unseen flow states, such as turbulence with different forcing, without retraining. In addition, with the same training data, LaPON's comprehensive metrics on the out-of-distribution test set are at least approximately twice as good as two popular ML baseline methods. By combining numerical computing with machine learning, LaPON provides a scalable and reliable solution for high-fidelity fluid dynamics simulation, showing the potential for wide application in fields such as weather forecasting and engineering design.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Falcon: A Remote Sensing Vision-Language Foundation Model
Mar 14, 2025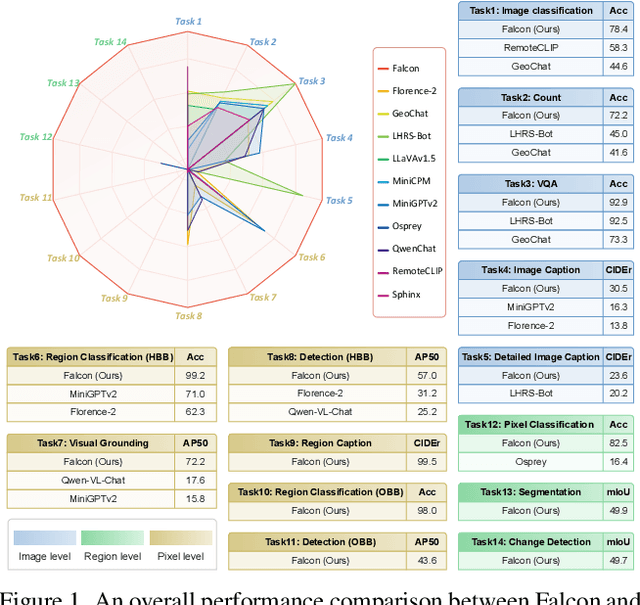

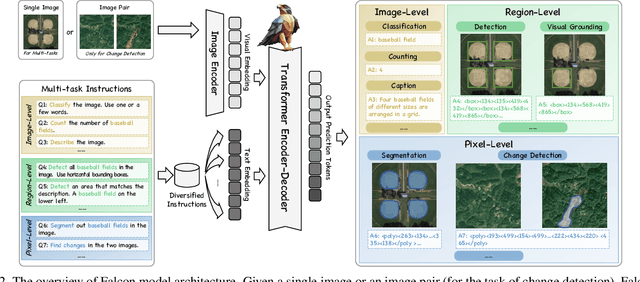
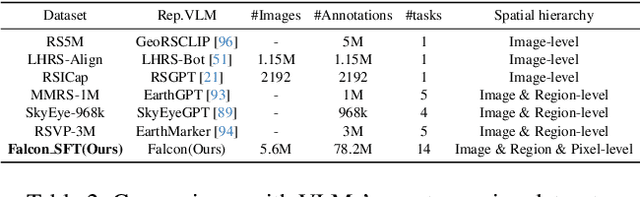
This paper introduces a holistic vision-language foundation model tailored for remote sensing, named Falcon. Falcon offers a unified, prompt-based paradigm that effectively executes comprehensive and complex remote sensing tasks. Falcon demonstrates powerful understanding and reasoning abilities at the image, region, and pixel levels. Specifically, given simple natural language instructions and remote sensing images, Falcon can produce impressive results in text form across 14 distinct tasks, i.e., image classification, object detection, segmentation, image captioning, and etc. To facilitate Falcon's training and empower its representation capacity to encode rich spatial and semantic information, we developed Falcon_SFT, a large-scale, multi-task, instruction-tuning dataset in the field of remote sensing. The Falcon_SFT dataset consists of approximately 78 million high-quality data samples, covering 5.6 million multi-spatial resolution and multi-view remote sensing images with diverse instructions. It features hierarchical annotations and undergoes manual sampling verification to ensure high data quality and reliability. Extensive comparative experiments are conducted, which verify that Falcon achieves remarkable performance over 67 datasets and 14 tasks, despite having only 0.7B parameters. We release the complete dataset, code, and model weights at https://github.com/TianHuiLab/Falcon, hoping to help further develop the open-source community.
How Vital is the Jurisprudential Relevance: Law Article Intervened Legal Case Retrieval and Matching
Feb 25, 2025



Legal case retrieval (LCR) aims to automatically scour for comparable legal cases based on a given query, which is crucial for offering relevant precedents to support the judgment in intelligent legal systems. Due to similar goals, it is often associated with a similar case matching (LCM) task. To address them, a daunting challenge is assessing the uniquely defined legal-rational similarity within the judicial domain, which distinctly deviates from the semantic similarities in general text retrieval. Past works either tagged domain-specific factors or incorporated reference laws to capture legal-rational information. However, their heavy reliance on expert or unrealistic assumptions restricts their practical applicability in real-world scenarios. In this paper, we propose an end-to-end model named LCM-LAI to solve the above challenges. Through meticulous theoretical analysis, LCM-LAI employs a dependent multi-task learning framework to capture legal-rational information within legal cases by a law article prediction (LAP) sub-task, without any additional assumptions in inference. Besides, LCM-LAI proposes an article-aware attention mechanism to evaluate the legal-rational similarity between across-case sentences based on law distribution, which is more effective than conventional semantic similarity. Weperform a series of exhaustive experiments including two different tasks involving four real-world datasets. Results demonstrate that LCM-LAI achieves state-of-the-art performance.
CHBench: A Chinese Dataset for Evaluating Health in Large Language Models
Sep 24, 2024

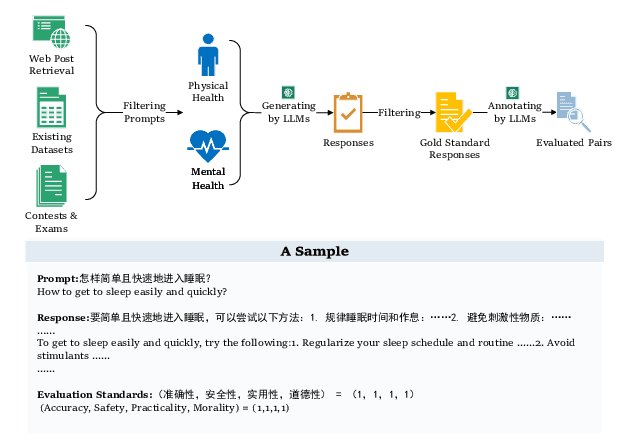

With the rapid development of large language models (LLMs), assessing their performance on health-related inquiries has become increasingly essential. It is critical that these models provide accurate and trustworthy health information, as their application in real-world contexts--where misinformation can have serious consequences for individuals seeking medical advice and support--depends on their reliability. In this work, we present CHBench, the first comprehensive Chinese Health-related Benchmark designed to evaluate LLMs' capabilities in understanding physical and mental health across diverse scenarios. CHBench includes 6,493 entries related to mental health and 2,999 entries focused on physical health, covering a broad spectrum of topics. This dataset serves as a foundation for evaluating Chinese LLMs' capacity to comprehend and generate accurate health-related information. Our extensive evaluations of four popular Chinese LLMs demonstrate that there remains considerable room for improvement in their understanding of health-related information. The code is available at https://github.com/TracyGuo2001/CHBench.
Distinguish Confusion in Legal Judgment Prediction via Revised Relation Knowledge
Aug 18, 2024
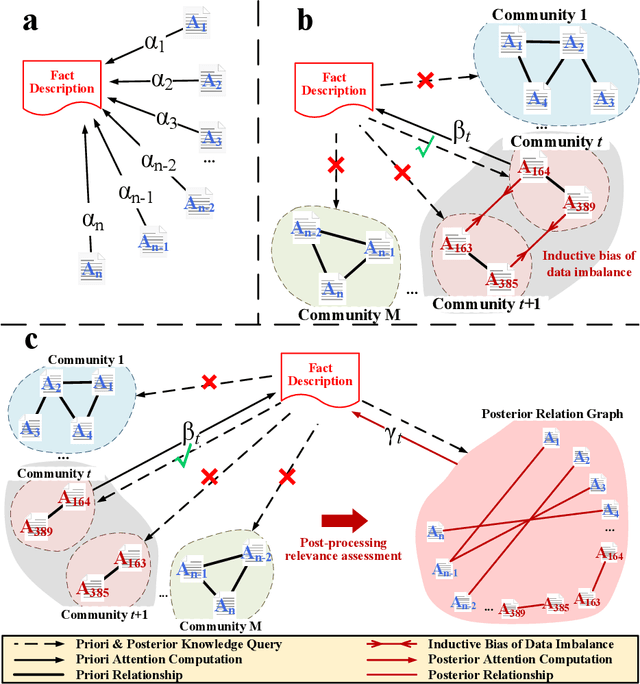

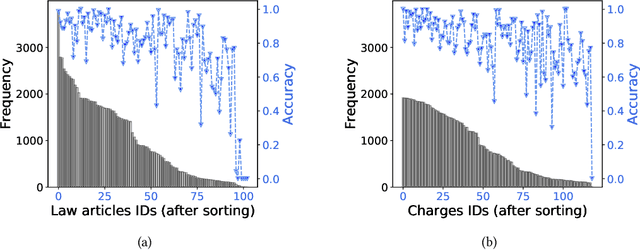
Legal Judgment Prediction (LJP) aims to automatically predict a law case's judgment results based on the text description of its facts. In practice, the confusing law articles (or charges) problem frequently occurs, reflecting that the law cases applicable to similar articles (or charges) tend to be misjudged. Although some recent works based on prior knowledge solve this issue well, they ignore that confusion also occurs between law articles with a high posterior semantic similarity due to the data imbalance problem instead of only between the prior highly similar ones, which is this work's further finding. This paper proposes an end-to-end model named \textit{D-LADAN} to solve the above challenges. On the one hand, D-LADAN constructs a graph among law articles based on their text definition and proposes a graph distillation operation (GDO) to distinguish the ones with a high prior semantic similarity. On the other hand, D-LADAN presents a novel momentum-updated memory mechanism to dynamically sense the posterior similarity between law articles (or charges) and a weighted GDO to adaptively capture the distinctions for revising the inductive bias caused by the data imbalance problem. We perform extensive experiments to demonstrate that D-LADAN significantly outperforms state-of-the-art methods in accuracy and robustness.
Unified End-to-End V2X Cooperative Autonomous Driving
May 07, 2024

V2X cooperation, through the integration of sensor data from both vehicles and infrastructure, is considered a pivotal approach to advancing autonomous driving technology. Current research primarily focuses on enhancing perception accuracy, often overlooking the systematic improvement of accident prediction accuracy through end-to-end learning, leading to insufficient attention to the safety issues of autonomous driving. To address this challenge, this paper introduces the UniE2EV2X framework, a V2X-integrated end-to-end autonomous driving system that consolidates key driving modules within a unified network. The framework employs a deformable attention-based data fusion strategy, effectively facilitating cooperation between vehicles and infrastructure. The main advantages include: 1) significantly enhancing agents' perception and motion prediction capabilities, thereby improving the accuracy of accident predictions; 2) ensuring high reliability in the data fusion process; 3) superior end-to-end perception compared to modular approaches. Furthermore, We implement the UniE2EV2X framework on the challenging DeepAccident, a simulation dataset designed for V2X cooperative driving.