 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHBench: A Chinese Dataset for Evaluating Health in Large Language Models
Paper and Code


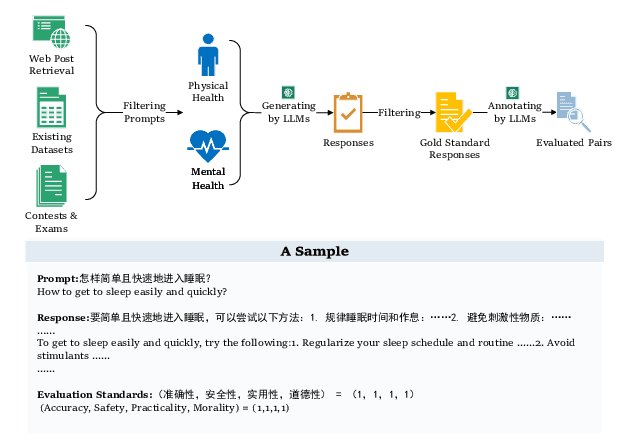

With the rapid development of large language models (LLMs), assessing their performance on health-related inquiries has become increasingly essential. It is critical that these models provide accurate and trustworthy health information, as their application in real-world contexts--where misinformation can have serious consequences for individuals seeking medical advice and support--depends on their reliability. In this work, we present CHBench, the first comprehensive Chinese Health-related Benchmark designed to evaluate LLMs' capabilities in understanding physical and mental health across diverse scenarios. CHBench includes 6,493 entries related to mental health and 2,999 entries focused on physical health, covering a broad spectrum of topics. This dataset serves as a foundation for evaluating Chinese LLMs' capacity to comprehend and generate accurate health-related information. Our extensive evaluations of four popular Chinese LLMs demonstrate that there remains considerable room for improvement in their understanding of health-related information. The code is available at https://github.com/TracyGuo2001/CHBench.