 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Security Audit Using Large Language Model based Agent: An Exploration Experiment
May 15, 2025In the current rapidly changing digital environment, businesses are under constant stress to ensure that their systems are secured. Security audits help to maintain a strong security posture by ensuring that policies are in place, controls are implemented, gaps are identified for cybersecurity risks mitigation. However, audits are usually manual, requiring much time and costs. This paper looks at the possibility of developing a framework to leverage Large Language Models (LLMs) as an autonomous agent to execute part of the security audit, namely with the field audit. password policy compliance for Windows operating system. Through the conduct of an exploration experiment of using GPT-4 with Langchain, the agent executed the audit tasks by accurately flagging password policy violations and appeared to be more efficient than traditional manual audits. Despite its potential limitations in operational consistency in complex and dynamic environment, the framework suggests possibilities to extend further to real-time threat monitoring and compliance checks.
Falcon: A Remote Sensing Vision-Language Foundation Model
Mar 14, 2025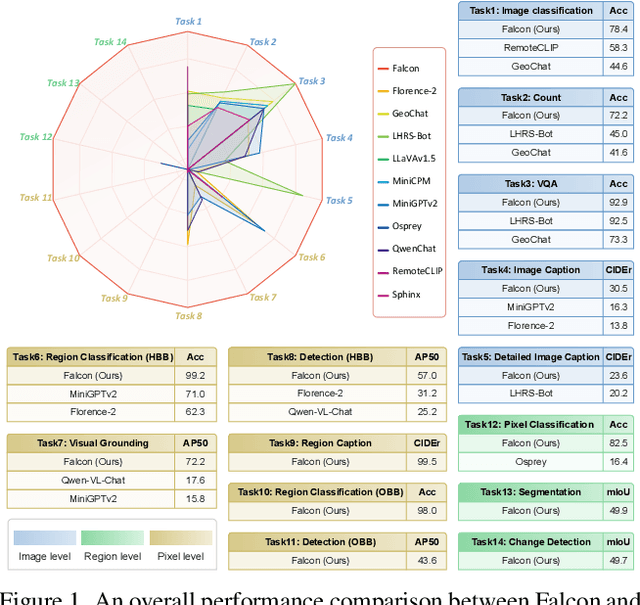

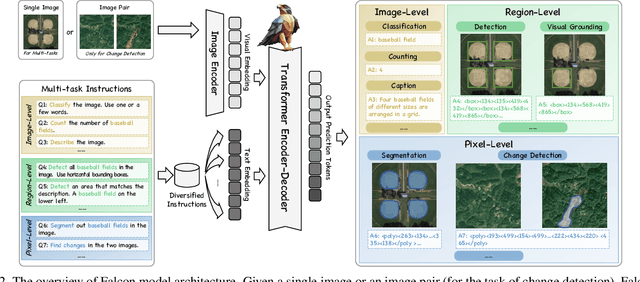
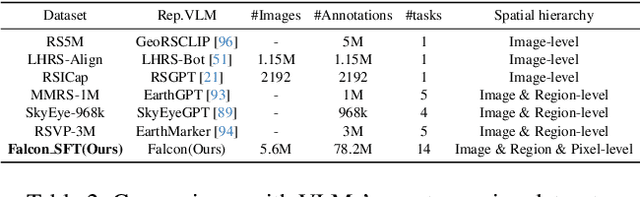
This paper introduces a holistic vision-language foundation model tailored for remote sensing, named Falcon. Falcon offers a unified, prompt-based paradigm that effectively executes comprehensive and complex remote sensing tasks. Falcon demonstrates powerful understanding and reasoning abilities at the image, region, and pixel levels. Specifically, given simple natural language instructions and remote sensing images, Falcon can produce impressive results in text form across 14 distinct tasks, i.e., image classification, object detection, segmentation, image captioning, and etc. To facilitate Falcon's training and empower its representation capacity to encode rich spatial and semantic information, we developed Falcon_SFT, a large-scale, multi-task, instruction-tuning dataset in the field of remote sensing. The Falcon_SFT dataset consists of approximately 78 million high-quality data samples, covering 5.6 million multi-spatial resolution and multi-view remote sensing images with diverse instructions. It features hierarchical annotations and undergoes manual sampling verification to ensure high data quality and reliability. Extensive comparative experiments are conducted, which verify that Falcon achieves remarkable performance over 67 datasets and 14 tasks, despite having only 0.7B parameters. We release the complete dataset, code, and model weights at https://github.com/TianHuiLab/Falcon, hoping to help further develop the open-source community.
JANUS: A Difference-Oriented Analyzer For Financial Centralization Risks in Smart Contracts
Dec 05, 2024Some smart contracts violate decentralization principles by defining privileged accounts that manage other users' assets without permission, introducing centralization risks that have caused financial losses. Existing methods, however, face challenges in accurately detecting diverse centralization risks due to their dependence on predefined behavior patterns. In this paper, we propose JANUS, an automated analyzer for Solidity smart contracts that detects financial centralization risks independently of their specific behaviors. JANUS identifies differences between states reached by privileged and ordinary accounts, and analyzes whether these differences are finance-related. Focusing on the impact of risks rather than behaviors, JANUS achieves improved accuracy compared to existing tools and can uncover centralization risks with unknown patterns. To evaluate JANUS's performance, we compare it with other tools using a dataset of 540 contracts. Our evaluation demonstrates that JANUS outperforms representative tools in terms of detection accuracy for financial centralization risks . Additionally, we evaluate JANUS on a real-world dataset of 33,151 contracts, successfully identifying two types of risks that other tools fail to detect. We also prove that the state traversal method and variable summaries, which are used in JANUS to reduce the number of states to be compared, do not introduce false alarms or omissions in detection.
Large Language Model is a Good Policy Teacher for Training Reinforcement Learning Agents
Nov 29, 2023



Recent studies have shown that Large Language Models (LLMs) can be utilized for solving complex sequential decision-making tasks by providing high-level instructions. However, LLM-based agents face limitations in real-time dynamic environments due to their lack of specialization in solving specific target problems. Moreover, the deployment of such LLM-based agents is both costly and time-consuming in practical scenarios. In this paper, we introduce a novel framework that addresses these challenges by training a smaller scale specialized student agent using instructions from an LLM-based teacher agent. By leveraging guided actions provided by the teachers, the prior knowledge of the LLM is distilled into the local student model. Consequently, the student agent can be trained with significantly less data. Furthermore, subsequent training with environment feedback empowers the student agents to surpass the capabilities of their teachers. We conducted experiments on three challenging MiniGrid environments to evaluate the effectiveness of our framework. The results demonstrate that our approach enhances sample efficiency and achieves superior performance compared to baseline methods. Our code is available at https://github.com/ZJLAB-AMMI/LLM4Teach.
SwinLSTM:Improving Spatiotemporal Prediction Accuracy using Swin Transformer and LSTM
Aug 19, 2023Integrating CNNs and RNNs to capture spatiotemporal dependencies is a prevalent strategy for spatiotemporal prediction tasks. However, the property of CNNs to learn local spatial information decreases their efficiency in capturing spatiotemporal dependencies, thereby limiting their prediction accuracy. In this paper, we propose a new recurrent cell, SwinLSTM, which integrates Swin Transformer blocks and the simplified LSTM, an extension that replaces the convolutional structure in ConvLSTM with the self-attention mechanism. Furthermore, we construct a network with SwinLSTM cell as the core for spatiotemporal prediction. Without using unique tricks, SwinLSTM outperforms state-of-the-art methods on Moving MNIST, Human3.6m, TaxiBJ, and KTH datasets. In particular, it exhibits a significant improvement in prediction accuracy compared to ConvLSTM. Our competitive experimental results demonstrate that learning global spatial dependencies is more advantageous for models to capture spatiotemporal dependencies. We hope that SwinLSTM can serve as a solid baseline to promote the advancement of spatiotemporal prediction accuracy. The codes are publicly available at https://github.com/SongTang-x/SwinLSTM.
Enhancing Mapless Trajectory Prediction through Knowledge Distillation
Jun 25, 2023

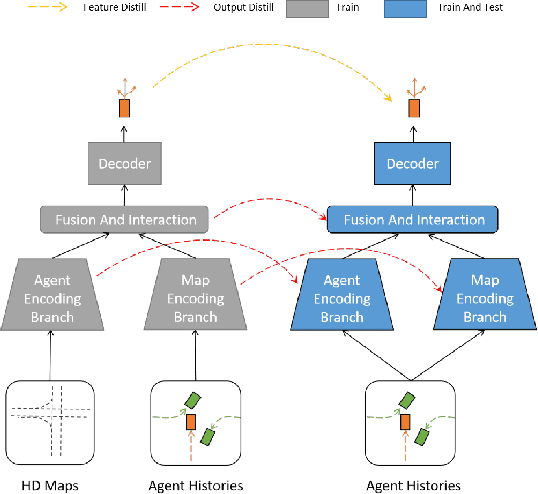

Scene information plays a crucial role in trajectory forecasting systems for autonomous driving by providing semantic clues and constraints on potential future paths of traffic agents. Prevalent trajectory prediction techniques often take high-definition maps (HD maps) as part of the inputs to provide scene knowledge. Although HD maps offer accurate road information, they may suffer from the high cost of annotation or restrictions of law that limits their widespread use. Therefore, those methods are still expected to generate reliable prediction results in mapless scenarios. In this paper, we tackle the problem of improving the consistency of multi-modal prediction trajectories and the real road topology when map information is unavailable during the test phase. Specifically, we achieve this by training a map-based prediction teacher network on the annotated samples and transferring the knowledge to a student mapless prediction network using a two-fold knowledge distillation framework. Our solution is generalizable for common trajectory prediction networks and does not bring extra computation burden. Experimental results show that our method stably improves prediction performance in mapless mode on many widely used state-of-the-art trajectory prediction baselines, compensating for the gaps caused by the absence of HD maps. Qualitative visualization results demonstrate that our approach helps infer unseen map information.
Enabling Intelligent Interactions between an Agent and an LLM: A Reinforcement Learning Approach
Jun 11, 2023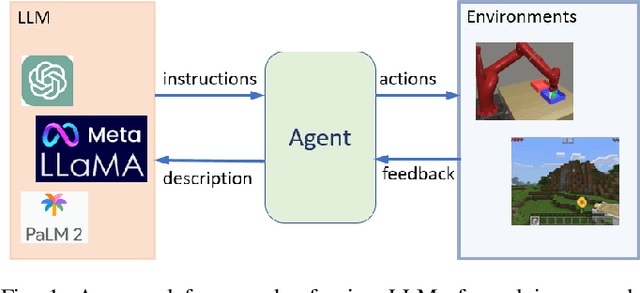



Large language models (LLMs) encode a vast amount of world knowledge acquired from massive text datasets. Recent studies have demonstrated that LLMs can assist an agent in solving complex sequential decision making tasks in embodied environments by providing high-level instructions. However, interacting with LLMs can be time-consuming, as in many practical scenarios, they require a significant amount of storage space that can only be deployed on remote cloud server nodes. Additionally, using commercial LLMs can be costly since they may charge based on usage frequency. In this paper, we explore how to enable intelligent cost-effective interactions between the agent and an LLM. We propose a reinforcement learning based mediator model that determines when it is necessary to consult LLMs for high-level instructions to accomplish a target task. Experiments on 4 MiniGrid environments that entail planning sub-goals demonstrate that our method can learn to solve target tasks with only a few necessary interactions with an LLM, significantly reducing interaction costs in testing environments, compared with baseline methods. Experimental results also suggest that by learning a mediator model to interact with the LLM, the agent's performance becomes more robust against partial observability of the environment. Our code is available at https://github.com/ZJLAB-AMMI/LLM4RL.
FEND: A Future Enhanced Distribution-Aware Contrastive Learning Framework for Long-tail Trajectory Prediction
Mar 29, 2023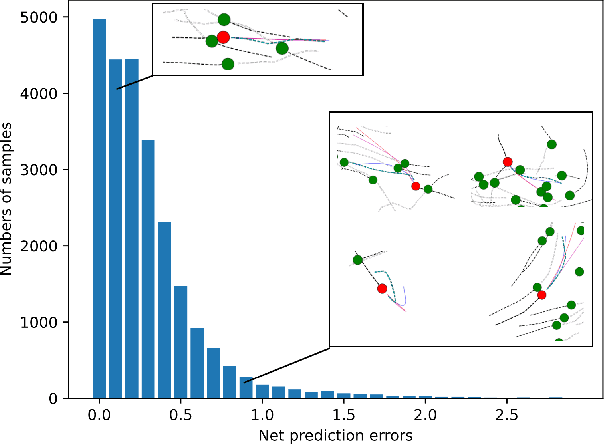



Predicting the future trajectories of the traffic agents is a gordian technique in autonomous driving. However, trajectory prediction suffers from data imbalance in the prevalent datasets, and the tailed data is often more complicated and safety-critical. In this paper, we focus on dealing with the long-tail phenomenon in trajectory prediction. Previous methods dealing with long-tail data did not take into account the variety of motion patterns in the tailed data. In this paper, we put forward a future enhanced contrastive learning framework to recognize tail trajectory patterns and form a feature space with separate pattern clusters. Furthermore, a distribution aware hyper predictor is brought up to better utilize the shaped feature space. Our method is a model-agnostic framework and can be plugged into many well-known baselines. Experimental results show that our framework outperforms the state-of-the-art long-tail prediction method on tailed samples by 9.5% on ADE and 8.5% on FDE, while maintaining or slightly improving the averaged performance. Our method also surpasses many long-tail techniques on trajectory prediction task.
Commonsense Knowledge Assisted Deep Learning for Resource-constrained and Fine-grained Object Detection
Mar 21, 2023



In this paper, we consider fine-grained image object detection in resource-constrained cases such as edge computing. Deep learning (DL), namely learning with deep neural networks (DNNs), has become the dominating approach to object detection. To achieve accurate fine-grained detection, one needs to employ a large enough DNN model and a vast amount of data annotations, which brings a challenge for using modern DL object detectors in resource-constrained cases. To this end, we propose an approach, which leverages commonsense knowledge to assist a coarse-grained object detector to get accurate fine-grained detection results. Specifically, we introduce a commonsense knowledge inference module (CKIM) to translate coarse-grained labels given by a backbone lightweight coarse-grained DL detector to fine-grained labels. We consider both crisp-rule and fuzzy-rule based inference in our CKIM; the latter is used to handle ambiguity in the target semantic labels. We implement our method based on several modern DL detectors, namely YOLOv4, Mobilenetv3-SSD and YOLOv7-tiny. Experiment results show that our approach outperforms benchmark detectors remarkably in terms of accuracy, model size and processing latency.
Heterogeneous Trajectory Forecasting via Risk and Scene Graph Learning
Nov 02, 2022



Heterogeneous trajectory forecasting is critical for intelligent transportation systems, while it is challenging because of the difficulty for modeling the complex interaction relations among the heterogeneous road agents as well as their agent-environment constraint. In this work, we propose a risk and scene graph learning method for trajectory forecasting of heterogeneous road agents, which consists of a Heterogeneous Risk Graph (HRG) and a Hierarchical Scene Graph (HSG) from the aspects of agent category and their movable semantic regions. HRG groups each kind of road agents and calculates their interaction adjacency matrix based on an effective collision risk metric. HSG of driving scene is modeled by inferring the relationship between road agents and road semantic layout aligned by the road scene grammar. Based on this formulation, we can obtain an effective trajectory forecasting in driving situations, and superior performance to other state-of-the-art approaches is demonstrated by exhaustive experiments on the nuScenes, ApolloScape, and Argoverse datasets.