 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCIP: Threshold-Controlled Iterative Pyramid Network for Deformable Medical Image Registration
Oct 09, 2025Although pyramid networks have demonstrated superior performance in deformable medical image registration, their decoder architectures are inherently prone to propagating and accumulating anatomical structure misalignments. Moreover, most existing models do not adaptively determine the number of iterations for optimization under varying deformation requirements across images, resulting in either premature termination or excessive iterations that degrades registration accuracy. To effectively mitigate the accumulation of anatomical misalignments, we propose the Feature-Enhanced Residual Module (FERM) as the core component of each decoding layer in the pyramid network. FERM comprises three sequential blocks that extract anatomical semantic features, learn to suppress irrelevant features, and estimate the final deformation field, respectively. To adaptively determine the number of iterations for varying images, we propose the dual-stage Threshold-Controlled Iterative (TCI) strategy. In the first stage, TCI assesses registration stability and with asserted stability, it continues with the second stage to evaluate convergence. We coin the model that integrates FERM and TCI as Threshold-Controlled Iterative Pyramid (TCIP). Extensive experiments on three public brain MRI datasets and one abdomen CT dataset demonstrate that TCIP outperforms the state-of-the-art (SOTA) registration networks in terms of accuracy, while maintaining comparable inference speed and a compact model parameter size. Finally, we assess the generalizability of FERM and TCI by integrating them with existing registration networks and further conduct ablation studies to validate the effectiveness of these two proposed methods.
SSFO: Self-Supervised Faithfulness Optimization for Retrieval-Augmented Generation
Aug 24, 2025Retrieval-Augmented Generation (RAG) systems require Large Language Models (LLMs) to generate responses that are faithful to the retrieved context. However, faithfulness hallucination remains a critical challenge, as existing methods often require costly supervision and post-training or significant inference burdens. To overcome these limitations, we introduce Self-Supervised Faithfulness Optimization (SSFO), the first self-supervised alignment approach for enhancing RAG faithfulness. SSFO constructs preference data pairs by contrasting the model's outputs generated with and without the context. Leveraging Direct Preference Optimization (DPO), SSFO aligns model faithfulness without incurring labeling costs or additional inference burden. We theoretically and empirically demonstrate that SSFO leverages a benign form of \emph{likelihood displacement}, transferring probability mass from parametric-based tokens to context-aligned tokens. Based on this insight, we propose a modified DPO loss function to encourage likelihood displacement. Comprehensive evaluations show that SSFO significantly outperforms existing methods, achieving state-of-the-art faithfulness on multiple context-based question-answering datasets. Notably, SSFO exhibits strong generalization, improving cross-lingual faithfulness and preserving general instruction-following capabilities. We release our code and model at the anonymous link: https://github.com/chkwy/SSFO
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
FLTG: Byzantine-Robust Federated Learning via Angle-Based Defense and Non-IID-Aware Weighting
May 19, 2025Byzantine attacks during model aggregation in Federated Learning (FL) threaten training integrity by manipulating malicious clients' updates. Existing methods struggle with limited robustness under high malicious client ratios and sensitivity to non-i.i.d. data, leading to degraded accuracy. To address this, we propose FLTG, a novel aggregation algorithm integrating angle-based defense and dynamic reference selection. FLTG first filters clients via ReLU-clipped cosine similarity, leveraging a server-side clean dataset to exclude misaligned updates. It then dynamically selects a reference client based on the prior global model to mitigate non-i.i.d. bias, assigns aggregation weights inversely proportional to angular deviations, and normalizes update magnitudes to suppress malicious scaling. Evaluations across datasets of varying complexity under five classic attacks demonstrate FLTG's superiority over state-of-the-art methods under extreme bias scenarios and sustains robustness with a higher proportion(over 50%) of malicious clients.
Multimodal Feature-Driven Deep Learning for the Prediction of Duck Body Dimensions and Weight
Mar 19, 2025Accurate body dimension and weight measurements are critical for optimizing poultry management, health assessment, and economic efficiency. This study introduces an innovative deep learning-based model leveraging multimodal data-2D RGB images from different views, depth images, and 3D point clouds-for the non-invasive estimation of duck body dimensions and weight. A dataset of 1,023 Linwu ducks, comprising over 5,000 samples with diverse postures and conditions, was collected to support model training. The proposed method innovatively employs PointNet++ to extract key feature points from point clouds, extracts and computes corresponding 3D geometric features, and fuses them with multi-view convolutional 2D features. A Transformer encoder is then utilized to capture long-range dependencies and refine feature interactions, thereby enhancing prediction robustness. The model achieved a mean absolute percentage error (MAPE) of 6.33% and an R2 of 0.953 across eight morphometric parameters, demonstrating strong predictive capability. Unlike conventional manual measurements, the proposed model enables high-precision estimation while eliminating the necessity for physical handling, thereby reducing animal stress and broadening its application scope. This study marks the first application of deep learning techniques to poultry body dimension and weight estimation, providing a valuable reference for the intelligent and precise management of the livestock industry with far-reaching practical significance.
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Jan 21, 2025This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
Incorporating External Knowledge and Goal Guidance for LLM-based Conversational Recommender Systems
May 03, 2024



This paper aims to efficiently enable large language models (LLMs) to use external knowledge and goal guidance in conversational recommender system (CRS) tasks. Advanced LLMs (e.g., ChatGPT) are limited in domain-specific CRS tasks for 1) generating grounded responses with recommendation-oriented knowledge, or 2) proactively leading the conversations through different dialogue goals. In this work, we first analyze those limitations through a comprehensive evaluation, showing the necessity of external knowledge and goal guidance which contribute significantly to the recommendation accuracy and language quality. In light of this finding, we propose a novel ChatCRS framework to decompose the complex CRS task into several sub-tasks through the implementation of 1) a knowledge retrieval agent using a tool-augmented approach to reason over external Knowledge Bases and 2) a goal-planning agent for dialogue goal prediction. Experimental results on two multi-goal CRS datasets reveal that ChatCRS sets new state-of-the-art benchmarks, improving language quality of informativeness by 17% and proactivity by 27%, and achieving a tenfold enhancement in recommendation accuracy.
Utilizing Computer Vision for Continuous Monitoring of Vaccine Side Effects in Experimental Mice
Apr 03, 2024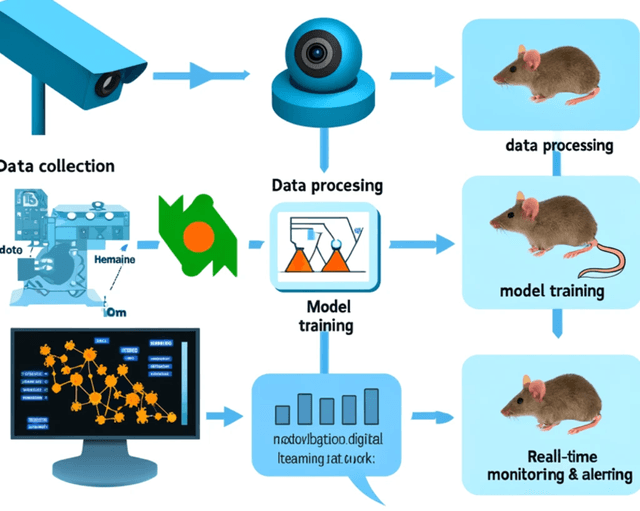
The demand for improved efficiency and accuracy in vaccine safety assessments is increasing. Here, we explore the application of computer vision technologies to automate the monitoring of experimental mice for potential side effects after vaccine administration. Traditional observation methods are labor-intensive and lack the capability for continuous monitoring. By deploying a computer vision system, our research aims to improve the efficiency and accuracy of vaccine safety assessments. The methodology involves training machine learning models on annotated video data of mice behaviors pre- and post-vaccination. Preliminary results indicate that computer vision effectively identify subtle changes, signaling possible side effects. Therefore, our approach has the potential to significantly enhance the monitoring process in vaccine trials in animals, providing a practical solution to the limitations of human observation.
Lightweight Modality Adaptation to Sequential Recommendation via Correlation Supervision
Jan 14, 2024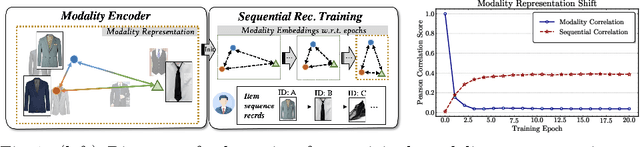
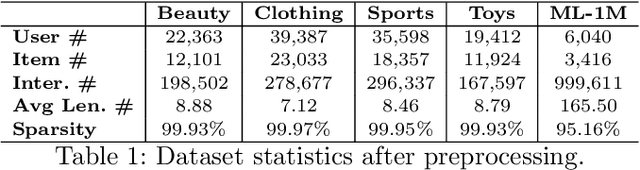
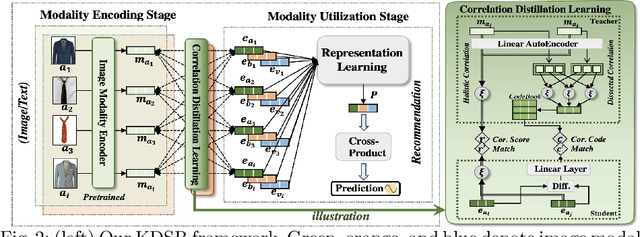
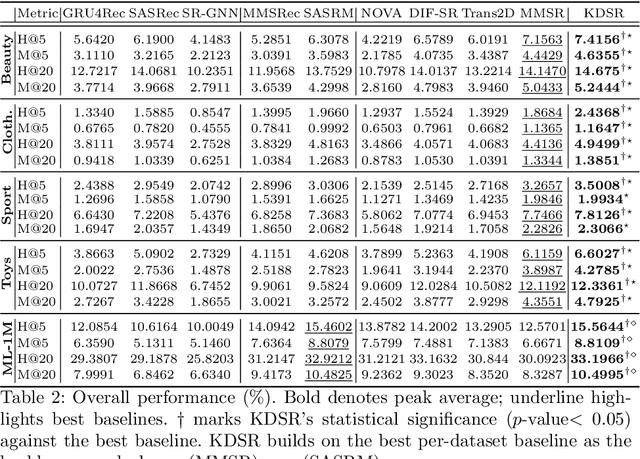
In Sequential Recommenders (SR), encoding and utilizing modalities in an end-to-end manner is costly in terms of modality encoder sizes. Two-stage approaches can mitigate such concerns, but they suffer from poor performance due to modality forgetting, where the sequential objective overshadows modality representation. We propose a lightweight knowledge distillation solution that preserves both merits: retaining modality information and maintaining high efficiency. Specifically, we introduce a novel method that enhances the learning of embeddings in SR through the supervision of modality correlations. The supervision signals are distilled from the original modality representations, including both (1) holistic correlations, which quantify their overall associations, and (2) dissected correlation types, which refine their relationship facets (honing in on specific aspects like color or shape consistency). To further address the issue of modality forgetting, we propose an asynchronous learning step, allowing the original information to be retained longer for training the representation learning module. Our approach is compatible with various backbone architectures and outperforms the top baselines by 6.8% on average. We empirically demonstrate that preserving original feature associations from modality encoders significantly boosts task-specific recommendation adaptation. Additionally, we find that larger modality encoders (e.g., Large Language Models) contain richer feature sets which necessitate more fine-grained modeling to reach their full performance potential.
UNO-DST: Leveraging Unlabelled Data in Zero-Shot Dialogue State Tracking
Oct 16, 2023Previous zero-shot dialogue state tracking (DST) methods only apply transfer learning, but ignore unlabelled data in the target domain. We transform zero-shot DST into few-shot DST by utilising such unlabelled data via joint and self-training methods. Our method incorporates auxiliary tasks that generate slot types as inverse prompts for main tasks, creating slot values during joint training. Cycle consistency between these two tasks enables the generation and selection of quality samples in unknown target domains for subsequent fine-tuning. This approach also facilitates automatic label creation, thereby optimizing the training and fine-tuning of DST models. We demonstrate this method's effectiveness on large language models in zero-shot scenarios, improving average joint goal accuracy by $8\%$ across all domains in MultiWOZ.