 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
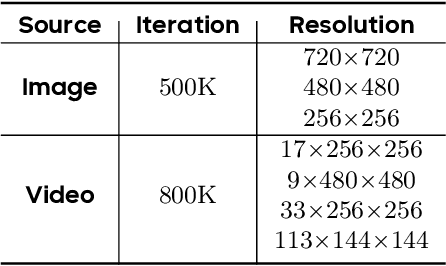
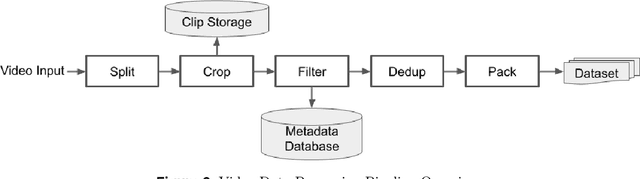

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Jan 21, 2025This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
ByteCheckpoint: A Unified Checkpointing System for LLM Development
Jul 29, 2024



The development of real-world Large Language Models (LLMs) necessitates checkpointing of training states in persistent storage to mitigate potential software and hardware failures, as well as to facilitate checkpoint transferring within the training pipeline and across various tasks. Due to the immense size of LLMs, saving and loading checkpoints often incur intolerable minute-level stalls, significantly diminishing training efficiency. Besides, when transferring checkpoints across tasks, checkpoint resharding, defined as loading checkpoints into parallel configurations differing from those used for saving, is often required according to the characteristics and resource quota of specific tasks. Previous checkpointing systems [16,3,33,6] assume consistent parallel configurations, failing to address the complexities of checkpoint transformation during resharding. Furthermore, in the industry platform, developers create checkpoints from different training frameworks[23,36,21,11], each with its own unique storage and I/O logic. This diversity complicates the implementation of unified checkpoint management and optimization. To address these challenges, we introduce ByteCheckpoint, a PyTorch-native multi-framework LLM checkpointing system that supports automatic online checkpoint resharding. ByteCheckpoint employs a data/metadata disaggregated storage architecture, decoupling checkpoint storage from the adopted parallelism strategies and training frameworks. We design an efficient asynchronous tensor merging technique to settle the irregular tensor sharding problem and propose several I/O performance optimizations to significantly enhance the efficiency of checkpoint saving and loading. Experimental results demonstrate ByteCheckpoint's substantial advantages in reducing checkpoint saving (by up to 529.22X) and loading (by up to 3.51X) costs, compared to baseline methods.