 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Seedream 3.0 Technical Report
Apr 16, 2025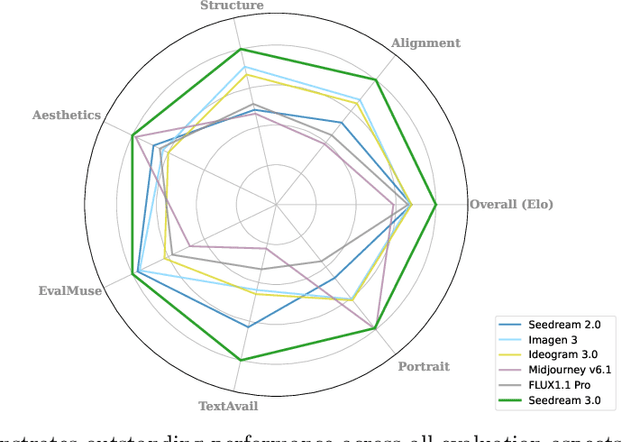


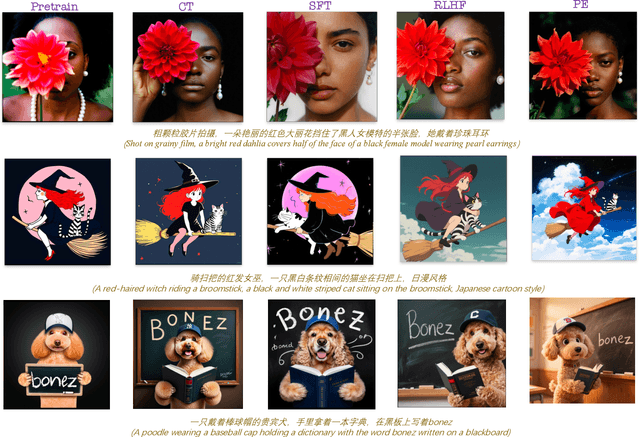
We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
Goku: Flow Based Video Generative Foundation Models
Feb 10, 2025



This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.
ByteCheckpoint: A Unified Checkpointing System for LLM Development
Jul 29, 2024



The development of real-world Large Language Models (LLMs) necessitates checkpointing of training states in persistent storage to mitigate potential software and hardware failures, as well as to facilitate checkpoint transferring within the training pipeline and across various tasks. Due to the immense size of LLMs, saving and loading checkpoints often incur intolerable minute-level stalls, significantly diminishing training efficiency. Besides, when transferring checkpoints across tasks, checkpoint resharding, defined as loading checkpoints into parallel configurations differing from those used for saving, is often required according to the characteristics and resource quota of specific tasks. Previous checkpointing systems [16,3,33,6] assume consistent parallel configurations, failing to address the complexities of checkpoint transformation during resharding. Furthermore, in the industry platform, developers create checkpoints from different training frameworks[23,36,21,11], each with its own unique storage and I/O logic. This diversity complicates the implementation of unified checkpoint management and optimization. To address these challenges, we introduce ByteCheckpoint, a PyTorch-native multi-framework LLM checkpointing system that supports automatic online checkpoint resharding. ByteCheckpoint employs a data/metadata disaggregated storage architecture, decoupling checkpoint storage from the adopted parallelism strategies and training frameworks. We design an efficient asynchronous tensor merging technique to settle the irregular tensor sharding problem and propose several I/O performance optimizations to significantly enhance the efficiency of checkpoint saving and loading. Experimental results demonstrate ByteCheckpoint's substantial advantages in reducing checkpoint saving (by up to 529.22X) and loading (by up to 3.51X) costs, compared to baseline methods.