 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaminar: A Scalable Asynchronous RL Post-Training Framework
Oct 14, 2025Reinforcement learning (RL) post-training for Large Language Models (LLMs) is now scaling to large clusters and running for extended durations to enhance model reasoning performance. However, the scalability of existing RL frameworks is limited, as extreme long-tail skewness in RL trajectory generation causes severe GPU underutilization. Current asynchronous RL systems attempt to mitigate this, but they rely on global weight synchronization between the actor and all rollouts, which creates a rigid model update schedule. This global synchronization is ill-suited for the highly skewed and evolving distribution of trajectory generation latency in RL training, crippling training efficiency. Our key insight is that efficient scaling requires breaking this lockstep through trajectory-level asynchrony, which generates and consumes each trajectory independently. We propose Laminar, a scalable and robust RL post-training system built on a fully decoupled architecture. First, we replace global updates with a tier of relay workers acting as a distributed parameter service. This enables asynchronous and fine-grained weight synchronization, allowing rollouts to pull the latest weight anytime without stalling the actor's training loop. Second, a dynamic repack mechanism consolidates long-tail trajectories onto a few dedicated rollouts, maximizing generation throughput. The fully decoupled design also isolates failures, ensuring robustness for long-running jobs. Our evaluation on a 1024-GPU cluster shows that Laminar achieves up to 5.48$\times$ training throughput speedup over state-of-the-art systems, while reducing model convergence time.
OVERLORD: Ultimate Scaling of DataLoader for Multi-Source Large Foundation Model Training
Apr 14, 2025Modern frameworks for training large foundation models (LFMs) employ data loaders in a data parallel paradigm. While this design offers implementation simplicity, it introduces two fundamental challenges. First, due to the quadratic computational complexity of the attention operator, the non-uniform sample distribution over data-parallel ranks leads to a significant workload imbalance among loaders, which degrades the training efficiency. This paradigm also impedes the implementation of data mixing algorithms (e.g., curriculum learning) over different datasets. Second, to acquire a broad range of capability, LFMs training ingests data from diverse sources, each with distinct file access states. Colocating massive datasets within loader instances can easily exceed local pod memory capacity. Additionally, heavy sources with higher transformation latency require larger worker pools, further exacerbating memory consumption. We present OVERLORD, an industrial-grade distributed data loading architecture with three innovations: (1) A centralized and declarative data plane, which facilitates elastic data orchestration strategy, such as long-short context, multimodal, and curriculum learning; (2) Disaggregated multisource preprocessing through role-specific actors, i.e., Source Loaders and Data Constructors, leveraging autoscaling for Source Loaders towards heterogeneous and evolving source preprocessing cost; (3) Shadow Loaders with differential checkpointing for uninterrupted fault recovery. Deployed on production clusters scaling to multi-thousand GPU, OVERLORD achieves: (1) 4.5x end-to-end training throughput improvement, (2) a minimum 3.6x reduction in CPU memory usage, with further improvements to be added in later experiments.
ByteCheckpoint: A Unified Checkpointing System for LLM Development
Jul 29, 2024



The development of real-world Large Language Models (LLMs) necessitates checkpointing of training states in persistent storage to mitigate potential software and hardware failures, as well as to facilitate checkpoint transferring within the training pipeline and across various tasks. Due to the immense size of LLMs, saving and loading checkpoints often incur intolerable minute-level stalls, significantly diminishing training efficiency. Besides, when transferring checkpoints across tasks, checkpoint resharding, defined as loading checkpoints into parallel configurations differing from those used for saving, is often required according to the characteristics and resource quota of specific tasks. Previous checkpointing systems [16,3,33,6] assume consistent parallel configurations, failing to address the complexities of checkpoint transformation during resharding. Furthermore, in the industry platform, developers create checkpoints from different training frameworks[23,36,21,11], each with its own unique storage and I/O logic. This diversity complicates the implementation of unified checkpoint management and optimization. To address these challenges, we introduce ByteCheckpoint, a PyTorch-native multi-framework LLM checkpointing system that supports automatic online checkpoint resharding. ByteCheckpoint employs a data/metadata disaggregated storage architecture, decoupling checkpoint storage from the adopted parallelism strategies and training frameworks. We design an efficient asynchronous tensor merging technique to settle the irregular tensor sharding problem and propose several I/O performance optimizations to significantly enhance the efficiency of checkpoint saving and loading. Experimental results demonstrate ByteCheckpoint's substantial advantages in reducing checkpoint saving (by up to 529.22X) and loading (by up to 3.51X) costs, compared to baseline methods.
QSync: Quantization-Minimized Synchronous Distributed Training Across Hybrid Devices
Jul 02, 2024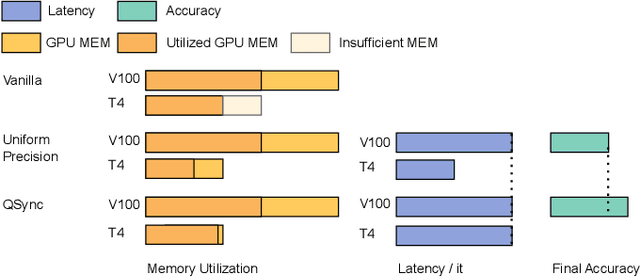
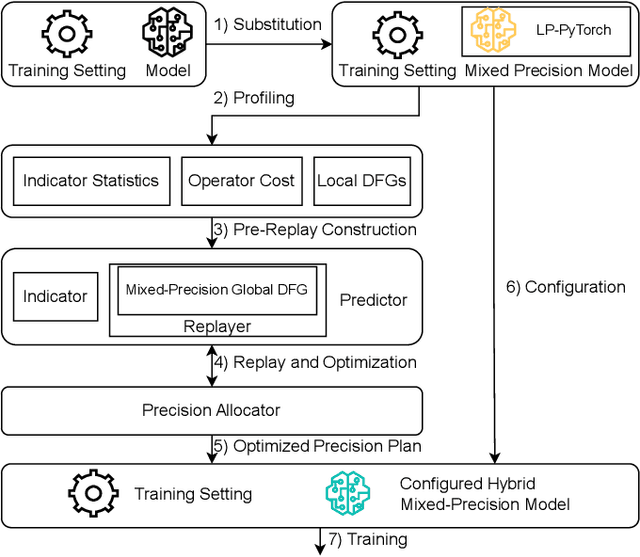
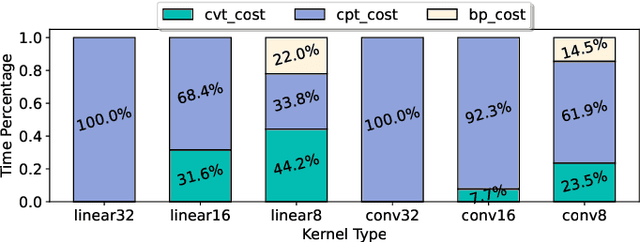
A number of production deep learning clusters have attempted to explore inference hardware for DNN training, at the off-peak serving hours with many inference GPUs idling. Conducting DNN training with a combination of heterogeneous training and inference GPUs, known as hybrid device training, presents considerable challenges due to disparities in compute capability and significant differences in memory capacity. We propose QSync, a training system that enables efficient synchronous data-parallel DNN training over hybrid devices by strategically exploiting quantized operators. According to each device's available resource capacity, QSync selects a quantization-minimized setting for operators in the distributed DNN training graph, minimizing model accuracy degradation but keeping the training efficiency brought by quantization. We carefully design a predictor with a bi-directional mixed-precision indicator to reflect the sensitivity of DNN layers on fixed-point and floating-point low-precision operators, a replayer with a neighborhood-aware cost mapper to accurately estimate the latency of distributed hybrid mixed-precision training, and then an allocator that efficiently synchronizes workers with minimized model accuracy degradation. QSync bridges the computational graph on PyTorch to an optimized backend for quantization kernel performance and flexible support for various GPU architectures. Extensive experiments show that QSync's predictor can accurately simulate distributed mixed-precision training with <5% error, with a consistent 0.27-1.03% accuracy improvement over the from-scratch training tasks compared to uniform precision.
LLM-PQ: Serving LLM on Heterogeneous Clusters with Phase-Aware Partition and Adaptive Quantization
Mar 02, 2024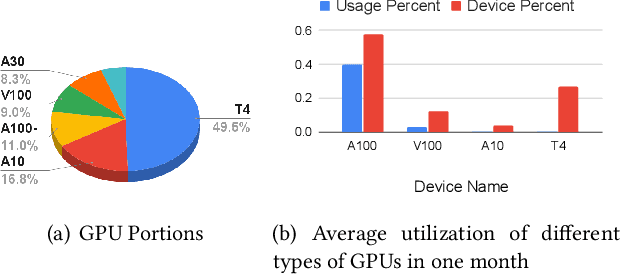
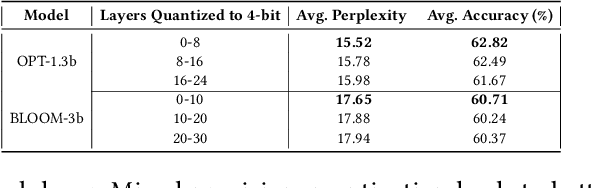
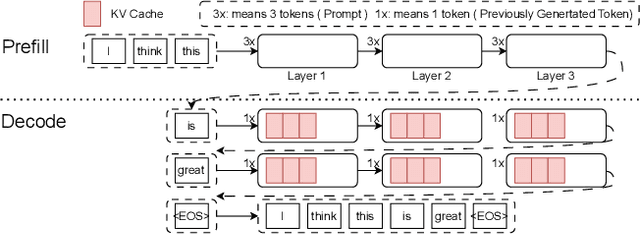

Recent breakthroughs in Large-scale language models (LLMs) have demonstrated impressive performance on various tasks. The immense sizes of LLMs have led to very high resource demand and cost for running the models. Though the models are largely served using uniform high-caliber GPUs nowadays, utilizing a heterogeneous cluster with a mix of available high- and low-capacity GPUs can potentially substantially reduce the serving cost. There is a lack of designs to support efficient LLM serving using a heterogeneous cluster, while the current solutions focus on model partition and uniform compression among homogeneous devices. This paper proposes LLM-PQ, a system that advocates adaptive model quantization and phase-aware partition to improve LLM serving efficiency on heterogeneous GPU clusters. We carefully decide on mixed-precision model quantization together with phase-aware model partition and micro-batch sizing in distributed LLM serving with an efficient algorithm, to greatly enhance inference throughput while fulfilling user-specified model quality targets. Extensive experiments on production inference workloads in 11 different clusters demonstrate that LLM-PQ achieves up to 2.88x (2.26x on average) throughput improvement in inference, showing great advantages over state-of-the-art works.
Adaptive Message Quantization and Parallelization for Distributed Full-graph GNN Training
Jun 02, 2023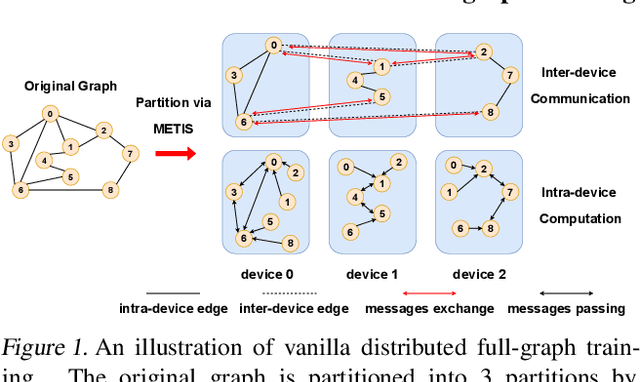
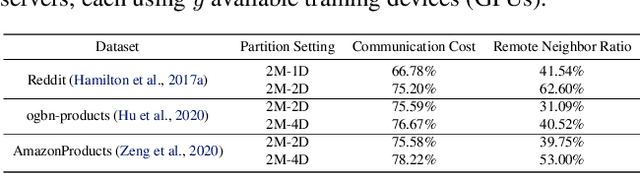
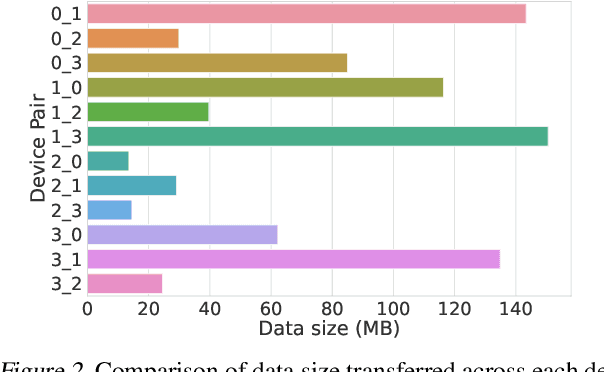
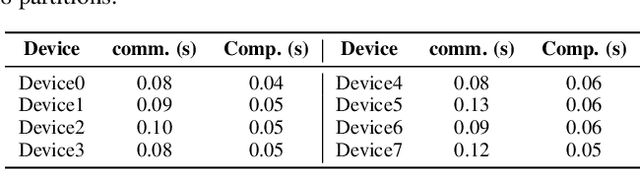
Distributed full-graph training of Graph Neural Networks (GNNs) over large graphs is bandwidth-demanding and time-consuming. Frequent exchanges of node features, embeddings and embedding gradients (all referred to as messages) across devices bring significant communication overhead for nodes with remote neighbors on other devices (marginal nodes) and unnecessary waiting time for nodes without remote neighbors (central nodes) in the training graph. This paper proposes an efficient GNN training system, AdaQP, to expedite distributed full-graph GNN training. We stochastically quantize messages transferred across devices to lower-precision integers for communication traffic reduction and advocate communication-computation parallelization between marginal nodes and central nodes. We provide theoretical analysis to prove fast training convergence (at the rate of O(T^{-1}) with T being the total number of training epochs) and design an adaptive quantization bit-width assignment scheme for each message based on the analysis, targeting a good trade-off between training convergence and efficiency. Extensive experiments on mainstream graph datasets show that AdaQP substantially improves distributed full-graph training's throughput (up to 3.01 X) with negligible accuracy drop (at most 0.30%) or even accuracy improvement (up to 0.19%) in most cases, showing significant advantages over the state-of-the-art works.