 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQSync: Quantization-Minimized Synchronous Distributed Training Across Hybrid Devices
Paper and Code
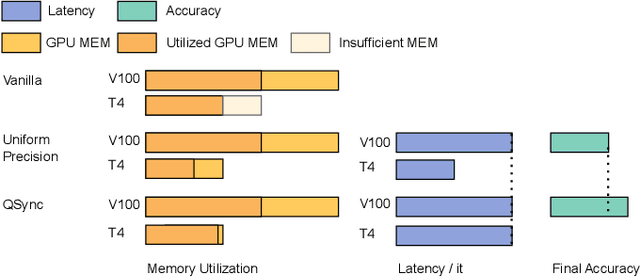
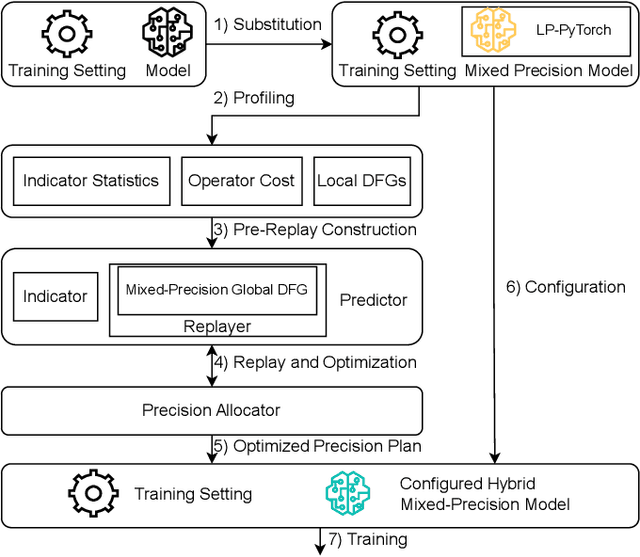
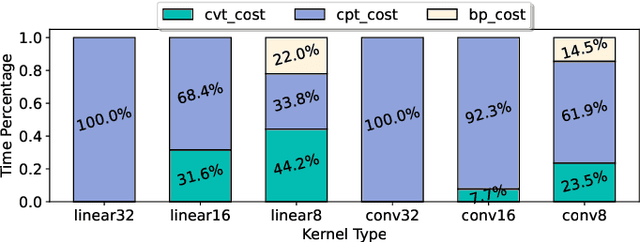
A number of production deep learning clusters have attempted to explore inference hardware for DNN training, at the off-peak serving hours with many inference GPUs idling. Conducting DNN training with a combination of heterogeneous training and inference GPUs, known as hybrid device training, presents considerable challenges due to disparities in compute capability and significant differences in memory capacity. We propose QSync, a training system that enables efficient synchronous data-parallel DNN training over hybrid devices by strategically exploiting quantized operators. According to each device's available resource capacity, QSync selects a quantization-minimized setting for operators in the distributed DNN training graph, minimizing model accuracy degradation but keeping the training efficiency brought by quantization. We carefully design a predictor with a bi-directional mixed-precision indicator to reflect the sensitivity of DNN layers on fixed-point and floating-point low-precision operators, a replayer with a neighborhood-aware cost mapper to accurately estimate the latency of distributed hybrid mixed-precision training, and then an allocator that efficiently synchronizes workers with minimized model accuracy degradation. QSync bridges the computational graph on PyTorch to an optimized backend for quantization kernel performance and flexible support for various GPU architectures. Extensive experiments show that QSync's predictor can accurately simulate distributed mixed-precision training with <5% error, with a consistent 0.27-1.03% accuracy improvement over the from-scratch training tasks compared to uniform precision.