 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Graph vs. Mini-Batch Training: Comprehensive Analysis from a Batch Size and Fan-Out Size Perspective
Jan 30, 2026Full-graph and mini-batch Graph Neural Network (GNN) training approaches have distinct system design demands, making it crucial to choose the appropriate approach to develop. A core challenge in comparing these two GNN training approaches lies in characterizing their model performance (i.e., convergence and generalization) and computational efficiency. While a batch size has been an effective lens in analyzing such behaviors in deep neural networks (DNNs), GNNs extend this lens by introducing a fan-out size, as full-graph training can be viewed as mini-batch training with the largest possible batch size and fan-out size. However, the impact of the batch and fan-out size for GNNs remains insufficiently explored. To this end, this paper systematically compares full-graph vs. mini-batch training of GNNs through empirical and theoretical analyses from the view points of the batch size and fan-out size. Our key contributions include: 1) We provide a novel generalization analysis using the Wasserstein distance to study the impact of the graph structure, especially the fan-out size. 2) We uncover the non-isotropic effects of the batch size and the fan-out size in GNN convergence and generalization, providing practical guidance for tuning these hyperparameters under resource constraints. Finally, full-graph training does not always yield better model performance or computational efficiency than well-tuned smaller mini-batch settings. The implementation can be found in the github link: https://github.com/LIUMENGFAN-gif/GNN_fullgraph_minibatch_training.
Laminar: A Scalable Asynchronous RL Post-Training Framework
Oct 14, 2025Reinforcement learning (RL) post-training for Large Language Models (LLMs) is now scaling to large clusters and running for extended durations to enhance model reasoning performance. However, the scalability of existing RL frameworks is limited, as extreme long-tail skewness in RL trajectory generation causes severe GPU underutilization. Current asynchronous RL systems attempt to mitigate this, but they rely on global weight synchronization between the actor and all rollouts, which creates a rigid model update schedule. This global synchronization is ill-suited for the highly skewed and evolving distribution of trajectory generation latency in RL training, crippling training efficiency. Our key insight is that efficient scaling requires breaking this lockstep through trajectory-level asynchrony, which generates and consumes each trajectory independently. We propose Laminar, a scalable and robust RL post-training system built on a fully decoupled architecture. First, we replace global updates with a tier of relay workers acting as a distributed parameter service. This enables asynchronous and fine-grained weight synchronization, allowing rollouts to pull the latest weight anytime without stalling the actor's training loop. Second, a dynamic repack mechanism consolidates long-tail trajectories onto a few dedicated rollouts, maximizing generation throughput. The fully decoupled design also isolates failures, ensuring robustness for long-running jobs. Our evaluation on a 1024-GPU cluster shows that Laminar achieves up to 5.48$\times$ training throughput speedup over state-of-the-art systems, while reducing model convergence time.
A Non-Asymptotic Convergent Analysis for Scored-Based Graph Generative Model via a System of Stochastic Differential Equations
Aug 20, 2025Score-based graph generative models (SGGMs) have proven effective in critical applications such as drug discovery and protein synthesis. However, their theoretical behavior, particularly regarding convergence, remains underexplored. Unlike common score-based generative models (SGMs), which are governed by a single stochastic differential equation (SDE), SGGMs involve a system of coupled SDEs. In SGGMs, the graph structure and node features are governed by separate but interdependent SDEs. This distinction makes existing convergence analyses from SGMs inapplicable for SGGMs. In this work, we present the first non-asymptotic convergence analysis for SGGMs, focusing on the convergence bound (the risk of generative error) across three key graph generation paradigms: (1) feature generation with a fixed graph structure, (2) graph structure generation with fixed node features, and (3) joint generation of both graph structure and node features. Our analysis reveals several unique factors specific to SGGMs (e.g., the topological properties of the graph structure) which affect the convergence bound. Additionally, we offer theoretical insights into the selection of hyperparameters (e.g., sampling steps and diffusion length) and advocate for techniques like normalization to improve convergence. To validate our theoretical findings, we conduct a controlled empirical study using synthetic graph models, and the results align with our theoretical predictions. This work deepens the theoretical understanding of SGGMs, demonstrates their applicability in critical domains, and provides practical guidance for designing effective models.
On the Interplay between Graph Structure and Learning Algorithms in Graph Neural Networks
Aug 20, 2025This paper studies the interplay between learning algorithms and graph structure for graph neural networks (GNNs). Existing theoretical studies on the learning dynamics of GNNs primarily focus on the convergence rates of learning algorithms under the interpolation regime (noise-free) and offer only a crude connection between these dynamics and the actual graph structure (e.g., maximum degree). This paper aims to bridge this gap by investigating the excessive risk (generalization performance) of learning algorithms in GNNs within the generalization regime (with noise). Specifically, we extend the conventional settings from the learning theory literature to the context of GNNs and examine how graph structure influences the performance of learning algorithms such as stochastic gradient descent (SGD) and Ridge regression. Our study makes several key contributions toward understanding the interplay between graph structure and learning in GNNs. First, we derive the excess risk profiles of SGD and Ridge regression in GNNs and connect these profiles to the graph structure through spectral graph theory. With this established framework, we further explore how different graph structures (regular vs. power-law) impact the performance of these algorithms through comparative analysis. Additionally, we extend our analysis to multi-layer linear GNNs, revealing an increasing non-isotropic effect on the excess risk profile, thereby offering new insights into the over-smoothing issue in GNNs from the perspective of learning algorithms. Our empirical results align with our theoretical predictions, \emph{collectively showcasing a coupling relation among graph structure, GNNs and learning algorithms, and providing insights on GNN algorithm design and selection in practice.}
OVERLORD: Ultimate Scaling of DataLoader for Multi-Source Large Foundation Model Training
Apr 14, 2025Modern frameworks for training large foundation models (LFMs) employ data loaders in a data parallel paradigm. While this design offers implementation simplicity, it introduces two fundamental challenges. First, due to the quadratic computational complexity of the attention operator, the non-uniform sample distribution over data-parallel ranks leads to a significant workload imbalance among loaders, which degrades the training efficiency. This paradigm also impedes the implementation of data mixing algorithms (e.g., curriculum learning) over different datasets. Second, to acquire a broad range of capability, LFMs training ingests data from diverse sources, each with distinct file access states. Colocating massive datasets within loader instances can easily exceed local pod memory capacity. Additionally, heavy sources with higher transformation latency require larger worker pools, further exacerbating memory consumption. We present OVERLORD, an industrial-grade distributed data loading architecture with three innovations: (1) A centralized and declarative data plane, which facilitates elastic data orchestration strategy, such as long-short context, multimodal, and curriculum learning; (2) Disaggregated multisource preprocessing through role-specific actors, i.e., Source Loaders and Data Constructors, leveraging autoscaling for Source Loaders towards heterogeneous and evolving source preprocessing cost; (3) Shadow Loaders with differential checkpointing for uninterrupted fault recovery. Deployed on production clusters scaling to multi-thousand GPU, OVERLORD achieves: (1) 4.5x end-to-end training throughput improvement, (2) a minimum 3.6x reduction in CPU memory usage, with further improvements to be added in later experiments.
TreeSynth: Synthesizing Diverse Data from Scratch via Tree-Guided Subspace Partitioning
Mar 21, 2025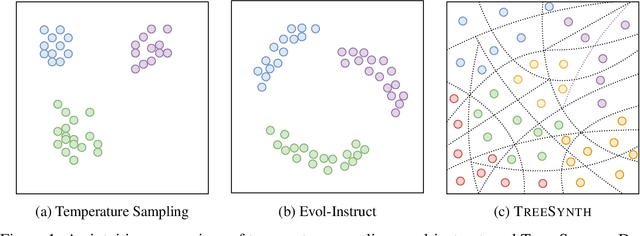
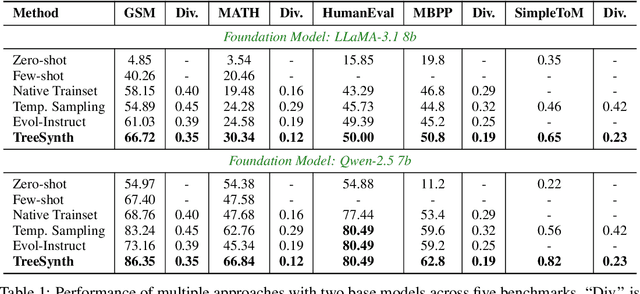
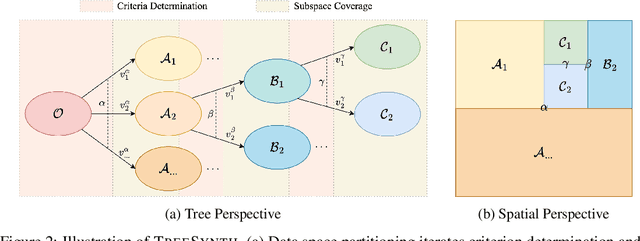
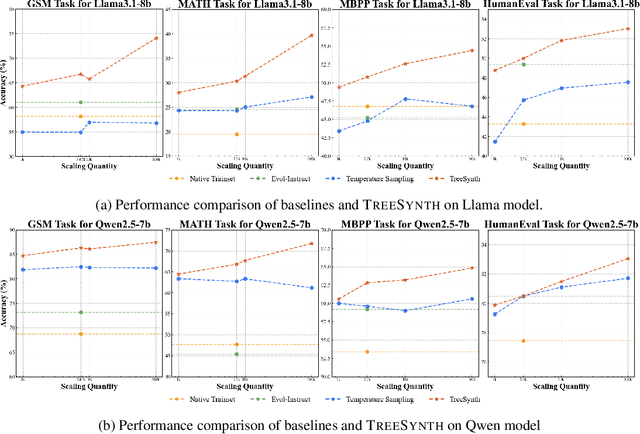
Model customization requires high-quality and diverse datasets, but acquiring such data remains challenging and costly. Although large language models (LLMs) can synthesize training data, current approaches are constrained by limited seed data, model bias and insufficient control over the generation process, resulting in limited diversity and biased distribution with the increase of data scales. To tackle this challenge, we present TreeSynth, a tree-guided subspace-based data synthesis framework that recursively partitions the entire data space into hierar-chical subspaces, enabling comprehensive and diverse scaling of data synthesis. Briefly, given a task-specific description, we construct a data space partitioning tree by iteratively executing criteria determination and subspace coverage steps. This hierarchically divides the whole space (i.e., root node) into mutually exclusive and complementary atomic subspaces (i.e., leaf nodes). By collecting synthesized data according to the attributes of each leaf node, we obtain a diverse dataset that fully covers the data space. Empirically, our extensive experiments demonstrate that TreeSynth surpasses both human-designed datasets and the state-of-the-art data synthesis baselines, achieving maximum improvements of 45.2% in data diversity and 17.6% in downstream task performance across various models and tasks. Hopefully, TreeSynth provides a scalable solution to synthesize diverse and comprehensive datasets from scratch without human intervention.
Developing and Utilizing a Large-Scale Cantonese Dataset for Multi-Tasking in Large Language Models
Mar 05, 2025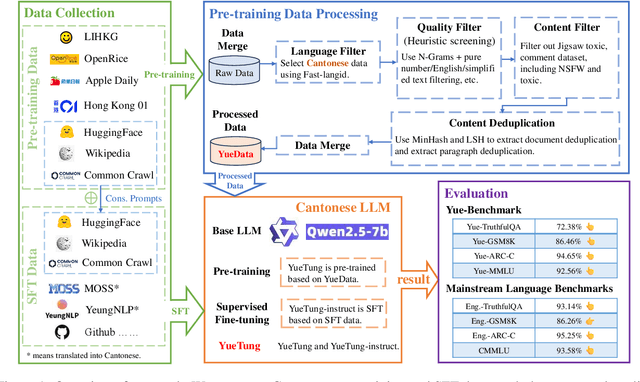
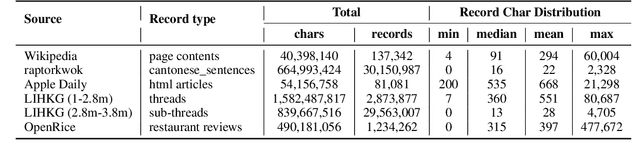
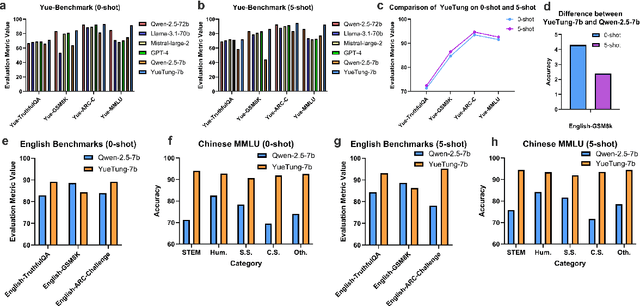
High-quality data resources play a crucial role in learning large language models (LLMs), particularly for low-resource languages like Cantonese. Despite having more than 85 million native speakers, Cantonese is still considered a low-resource language in the field of natural language processing (NLP) due to factors such as the dominance of Mandarin, lack of cohesion within the Cantonese-speaking community, diversity in character encoding and input methods, and the tendency of overseas Cantonese speakers to prefer using English. In addition, rich colloquial vocabulary of Cantonese, English loanwords, and code-switching characteristics add to the complexity of corpus collection and processing. To address these challenges, we collect Cantonese texts from a variety of sources, including open source corpora, Hong Kong-specific forums, Wikipedia, and Common Crawl data. We conduct rigorous data processing through language filtering, quality filtering, content filtering, and de-duplication steps, successfully constructing a high-quality Cantonese corpus of over 2 billion tokens for training large language models. We further refined the model through supervised fine-tuning (SFT) on curated Cantonese tasks, enhancing its ability to handle specific applications. Upon completion of the training, the model achieves state-of-the-art (SOTA) performance on four Cantonese benchmarks. After training on our dataset, the model also exhibits improved performance on other mainstream language tasks.
Optimizing Distributed Deployment of Mixture-of-Experts Model Inference in Serverless Computing
Jan 09, 2025With the advancement of serverless computing, running machine learning (ML) inference services over a serverless platform has been advocated, given its labor-free scalability and cost effectiveness. Mixture-of-Experts (MoE) models have been a dominant type of model architectures to enable large models nowadays, with parallel expert networks. Serving large MoE models on serverless computing is potentially beneficial, but has been underexplored due to substantial challenges in handling the skewed expert popularity and scatter-gather communication bottleneck in MoE model execution, for cost-efficient serverless MoE deployment and performance guarantee. We study optimized MoE model deployment and distributed inference serving on a serverless platform, that effectively predict expert selection, pipeline communication with model execution, and minimize the overall billed cost of serving MoE models. Especially, we propose a Bayesian optimization framework with multi-dimensional epsilon-greedy search to learn expert selections and optimal MoE deployment achieving optimal billed cost, including: 1) a Bayesian decision-making method for predicting expert popularity; 2) flexibly pipelined scatter-gather communication; and 3) an optimal model deployment algorithm for distributed MoE serving. Extensive experiments on AWS Lambda show that our designs reduce the billed cost of all MoE layers by at least 75.67% compared to CPU clusters while maintaining satisfactory inference throughput. As compared to LambdaML in serverless computing, our designs achieves 43.41% lower cost with a throughput decrease of at most 18.76%.
Echo: Simulating Distributed Training At Scale
Dec 17, 2024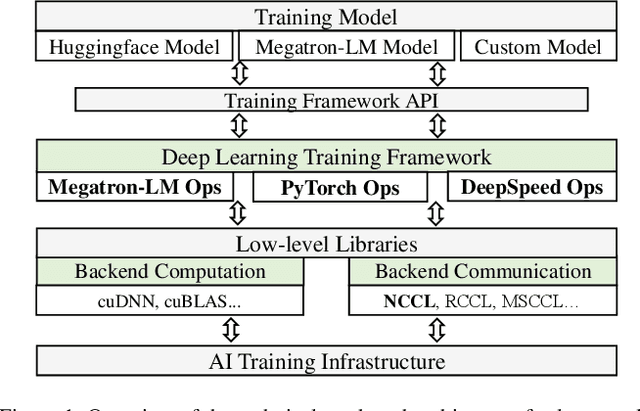


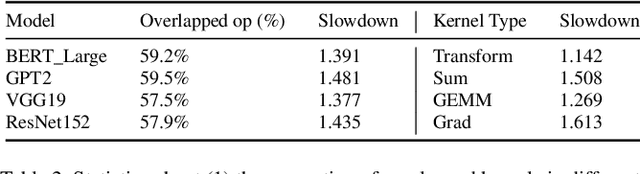
Simulation offers unique values for both enumeration and extrapolation purposes, and is becoming increasingly important for managing the massive machine learning (ML) clusters and large-scale distributed training jobs. In this paper, we build Echo to tackle three key challenges in large-scale training simulation: (1) tracing the runtime training workloads at each device in an ex-situ fashion so we can use a single device to obtain the actual execution graphs of 1K-GPU training, (2) accurately estimating the collective communication without high overheads of discrete-event based network simulation, and (3) accounting for the interference-induced computation slowdown from overlapping communication and computation kernels on the same device. Echo delivers on average 8% error in training step -- roughly 3x lower than state-of-the-art simulators -- for GPT-175B on a 96-GPU H800 cluster with 3D parallelism on Megatron-LM under 2 minutes.
FedMoE-DA: Federated Mixture of Experts via Domain Aware Fine-grained Aggregation
Nov 04, 2024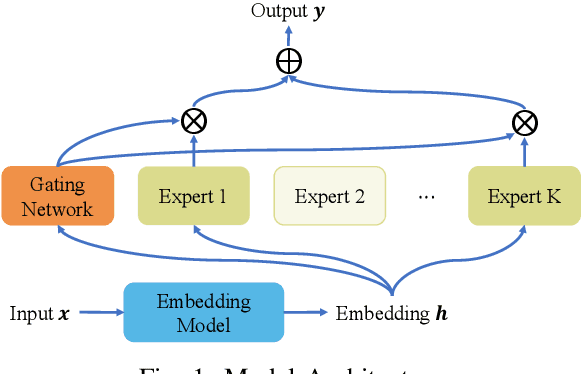
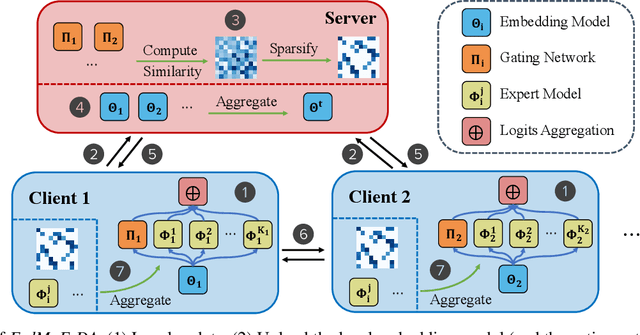
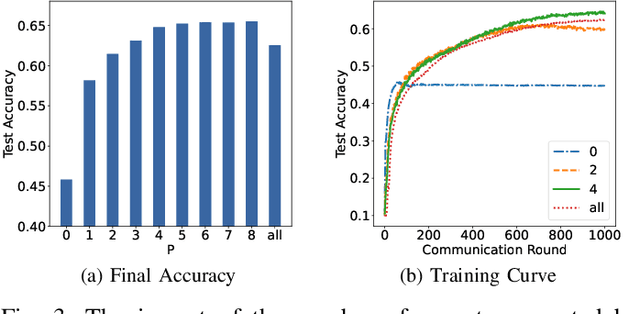
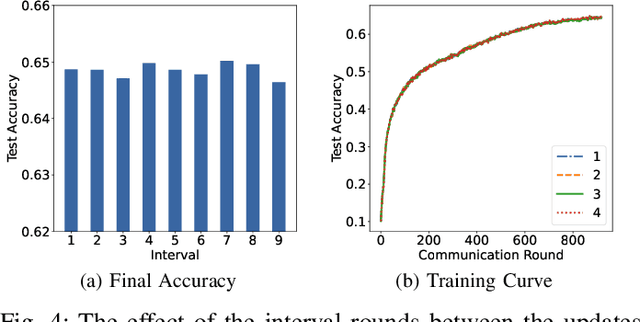
Federated learning (FL) is a collaborative machine learning approach that enables multiple clients to train models without sharing their private data. With the rise of deep learning, large-scale models have garnered significant attention due to their exceptional performance. However, a key challenge in FL is the limitation imposed by clients with constrained computational and communication resources, which hampers the deployment of these large models. The Mixture of Experts (MoE) architecture addresses this challenge with its sparse activation property, which reduces computational workload and communication demands during inference and updates. Additionally, MoE facilitates better personalization by allowing each expert to specialize in different subsets of the data distribution. To alleviate the communication burdens between the server and clients, we propose FedMoE-DA, a new FL model training framework that leverages the MoE architecture and incorporates a novel domain-aware, fine-grained aggregation strategy to enhance the robustness, personalizability, and communication efficiency simultaneously. Specifically, the correlation between both intra-client expert models and inter-client data heterogeneity is exploited. Moreover, we utilize peer-to-peer (P2P) communication between clients for selective expert model synchronization, thus significantly reducing the server-client transmissions. Experiments demonstrate that our FedMoE-DA achieves excellent performance while reducing the communication pressure on the server.