 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping and Utilizing a Large-Scale Cantonese Dataset for Multi-Tasking in Large Language Models
Paper and Code
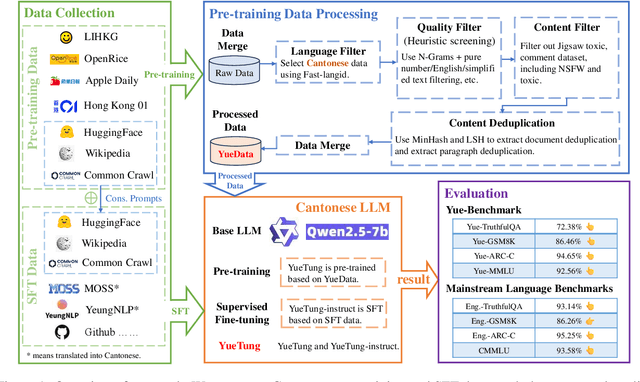
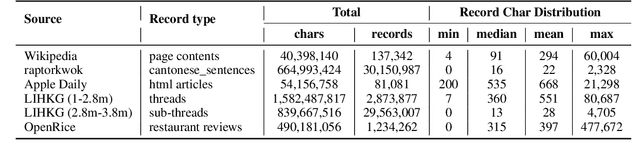
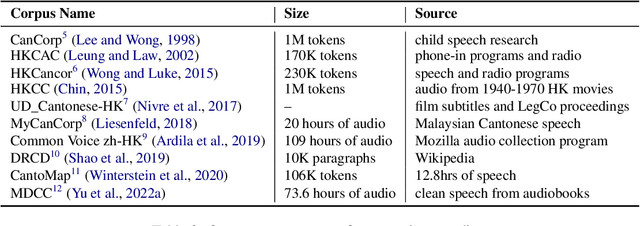
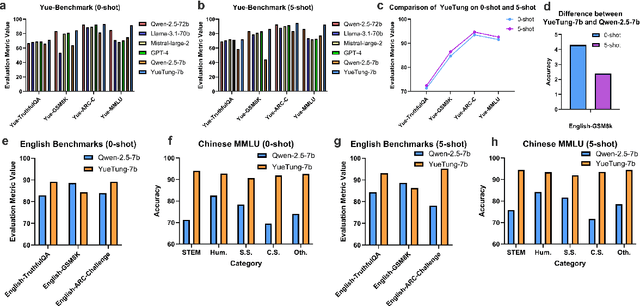
High-quality data resources play a crucial role in learning large language models (LLMs), particularly for low-resource languages like Cantonese. Despite having more than 85 million native speakers, Cantonese is still considered a low-resource language in the field of natural language processing (NLP) due to factors such as the dominance of Mandarin, lack of cohesion within the Cantonese-speaking community, diversity in character encoding and input methods, and the tendency of overseas Cantonese speakers to prefer using English. In addition, rich colloquial vocabulary of Cantonese, English loanwords, and code-switching characteristics add to the complexity of corpus collection and processing. To address these challenges, we collect Cantonese texts from a variety of sources, including open source corpora, Hong Kong-specific forums, Wikipedia, and Common Crawl data. We conduct rigorous data processing through language filtering, quality filtering, content filtering, and de-duplication steps, successfully constructing a high-quality Cantonese corpus of over 2 billion tokens for training large language models. We further refined the model through supervised fine-tuning (SFT) on curated Cantonese tasks, enhancing its ability to handle specific applications. Upon completion of the training, the model achieves state-of-the-art (SOTA) performance on four Cantonese benchmarks. After training on our dataset, the model also exhibits improved performance on other mainstream language tasks.