 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolSelf: Unifying Task Execution and Self-Reconfiguration via Tool-Driven Intrinsic Adaptation
Feb 08, 2026Agentic systems powered by Large Language Models (LLMs) have demonstrated remarkable potential in tackling complex, long-horizon tasks. However, their efficacy is fundamentally constrained by static configurations governing agent behaviors, which are fixed prior to execution and fail to adapt to evolving task dynamics. Existing approaches, relying on manual orchestration or heuristic-based patches, often struggle with poor generalization and fragmented optimization. To transcend these limitations, we propose ToolSelf, a novel paradigm enabling tool-driven runtime self-reconfiguration. By abstracting configuration updates as a callable tool, ToolSelf unifies task execution and self-adjustment into a single action space, achieving a phase transition from external rules to intrinsic parameters. Agents can thereby autonomously update their sub-goals and context based on task progression, and correspondingly adapt their strategy and toolbox, transforming from passive executors into dual managers of both task and self. We further devise Configuration-Aware Two-stage Training (CAT), combining rejection sampling fine-tuning with trajectory-level reinforcement learning to internalize this meta-capability. Extensive experiments across diverse benchmarks demonstrate that ToolSelf rivals specialized workflows while generalizing to novel tasks, achieving a 24.1% average performance gain and illuminating a path toward truly self-adaptive agents.
Investigating Data Pruning for Pretraining Biological Foundation Models at Scale
Dec 15, 2025Biological foundation models (BioFMs), pretrained on large-scale biological sequences, have recently shown strong potential in providing meaningful representations for diverse downstream bioinformatics tasks. However, such models often rely on millions to billions of training sequences and billions of parameters, resulting in prohibitive computational costs and significant barriers to reproducibility and accessibility, particularly for academic labs. To address these challenges, we investigate the feasibility of data pruning for BioFM pretraining and propose a post-hoc influence-guided data pruning framework tailored to biological domains. Our approach introduces a subset-based self-influence formulation that enables efficient estimation of sample importance at low computational cost, and builds upon it two simple yet effective selection strategies, namely Top-k Influence (Top I) and Coverage-Centric Influence (CCI). We empirically validate our method on two representative BioFMs, RNA-FM and ESM-C. For RNA, our framework consistently outperforms random selection baselines under an extreme pruning rate of over 99 percent, demonstrating its effectiveness. Furthermore, we show the generalizability of our framework on protein-related tasks using ESM-C. In particular, our coreset even outperforms random subsets that are ten times larger in both RNA and protein settings, revealing substantial redundancy in biological sequence datasets. These findings underscore the potential of influence-guided data pruning to substantially reduce the computational cost of BioFM pretraining, paving the way for more efficient, accessible, and sustainable biological AI research.
DS-ProGen: A Dual-Structure Deep Language Model for Functional Protein Design
May 18, 2025Inverse Protein Folding (IPF) is a critical subtask in the field of protein design, aiming to engineer amino acid sequences capable of folding correctly into a specified three-dimensional (3D) conformation. Although substantial progress has been achieved in recent years, existing methods generally rely on either backbone coordinates or molecular surface features alone, which restricts their ability to fully capture the complex chemical and geometric constraints necessary for precise sequence prediction. To address this limitation, we present DS-ProGen, a dual-structure deep language model for functional protein design, which integrates both backbone geometry and surface-level representations. By incorporating backbone coordinates as well as surface chemical and geometric descriptors into a next-amino-acid prediction paradigm, DS-ProGen is able to generate functionally relevant and structurally stable sequences while satisfying both global and local conformational constraints. On the PRIDE dataset, DS-ProGen attains the current state-of-the-art recovery rate of 61.47%, demonstrating the synergistic advantage of multi-modal structural encoding in protein design. Furthermore, DS-ProGen excels in predicting interactions with a variety of biological partners, including ligands, ions, and RNA, confirming its robust functional retention capabilities.
TreeSynth: Synthesizing Diverse Data from Scratch via Tree-Guided Subspace Partitioning
Mar 21, 2025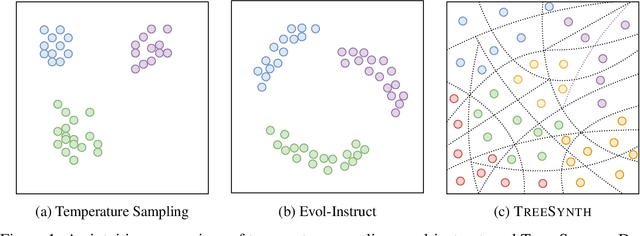
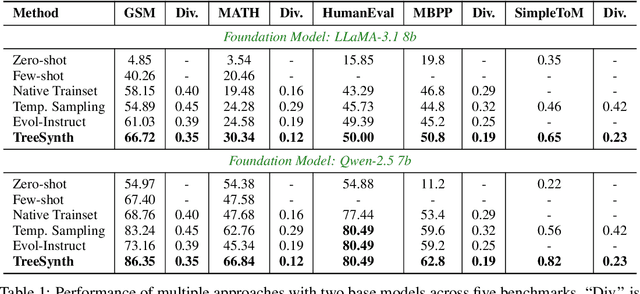
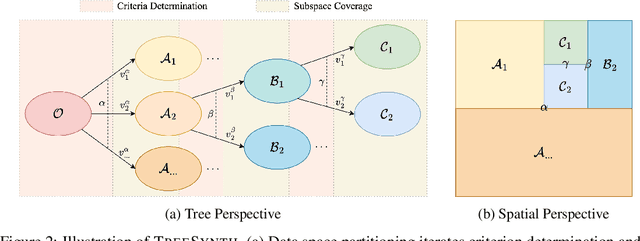
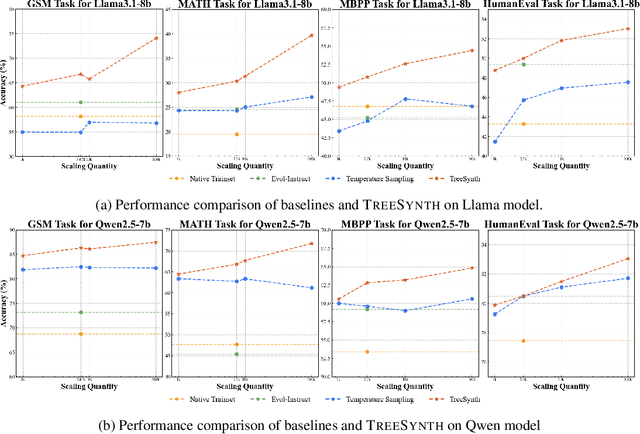
Model customization requires high-quality and diverse datasets, but acquiring such data remains challenging and costly. Although large language models (LLMs) can synthesize training data, current approaches are constrained by limited seed data, model bias and insufficient control over the generation process, resulting in limited diversity and biased distribution with the increase of data scales. To tackle this challenge, we present TreeSynth, a tree-guided subspace-based data synthesis framework that recursively partitions the entire data space into hierar-chical subspaces, enabling comprehensive and diverse scaling of data synthesis. Briefly, given a task-specific description, we construct a data space partitioning tree by iteratively executing criteria determination and subspace coverage steps. This hierarchically divides the whole space (i.e., root node) into mutually exclusive and complementary atomic subspaces (i.e., leaf nodes). By collecting synthesized data according to the attributes of each leaf node, we obtain a diverse dataset that fully covers the data space. Empirically, our extensive experiments demonstrate that TreeSynth surpasses both human-designed datasets and the state-of-the-art data synthesis baselines, achieving maximum improvements of 45.2% in data diversity and 17.6% in downstream task performance across various models and tasks. Hopefully, TreeSynth provides a scalable solution to synthesize diverse and comprehensive datasets from scratch without human intervention.
Large Language Models in Bioinformatics: A Survey
Mar 06, 2025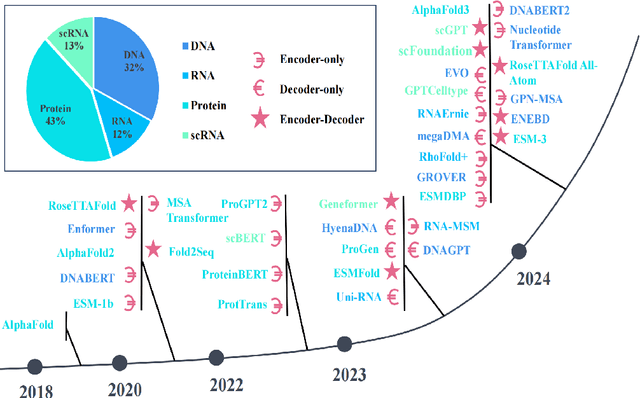
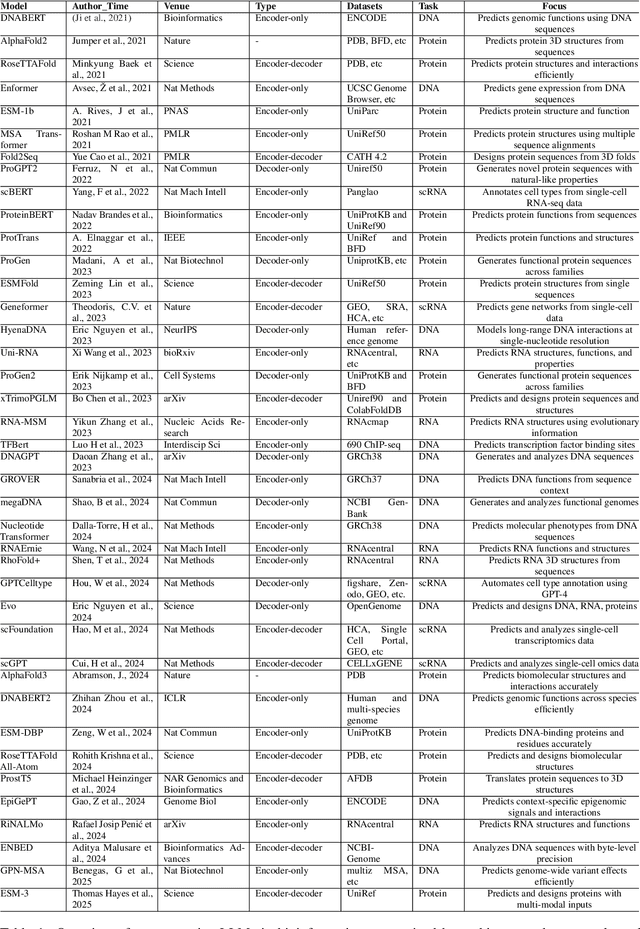
Large Language Models (LLMs) are revolutionizing bioinformatics, enabling advanced analysis of DNA, RNA, proteins, and single-cell data. This survey provides a systematic review of recent advancements, focusing on genomic sequence modeling, RNA structure prediction, protein function inference, and single-cell transcriptomics. Meanwhile, we also discuss several key challenges, including data scarcity, computational complexity, and cross-omics integration, and explore future directions such as multimodal learning, hybrid AI models, and clinical applications. By offering a comprehensive perspective, this paper underscores the transformative potential of LLMs in driving innovations in bioinformatics and precision medicine.
Biological Sequence with Language Model Prompting: A Survey
Mar 06, 2025Large Language models (LLMs) have emerged as powerful tools for addressing challenges across diverse domains. Notably, recent studies have demonstrated that large language models significantly enhance the efficiency of biomolecular analysis and synthesis, attracting widespread attention from academics and medicine. In this paper, we systematically investigate the application of prompt-based methods with LLMs to biological sequences, including DNA, RNA, proteins, and drug discovery tasks. Specifically, we focus on how prompt engineering enables LLMs to tackle domain-specific problems, such as promoter sequence prediction, protein structure modeling, and drug-target binding affinity prediction, often with limited labeled data. Furthermore, our discussion highlights the transformative potential of prompting in bioinformatics while addressing key challenges such as data scarcity, multimodal fusion, and computational resource limitations. Our aim is for this paper to function both as a foundational primer for newcomers and a catalyst for continued innovation within this dynamic field of study.
Developing and Utilizing a Large-Scale Cantonese Dataset for Multi-Tasking in Large Language Models
Mar 05, 2025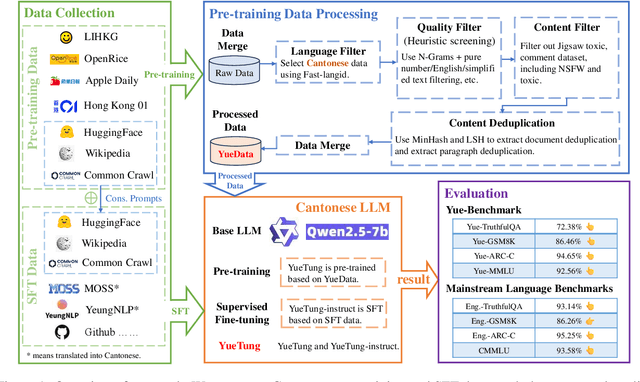
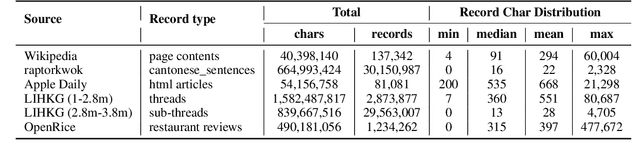
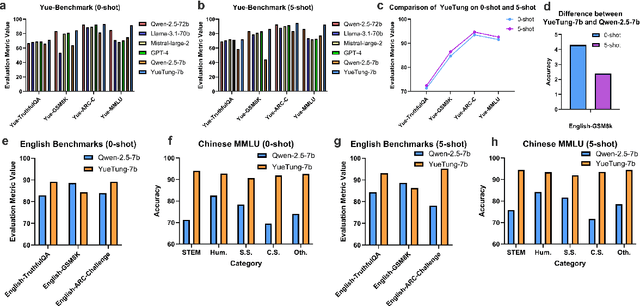
High-quality data resources play a crucial role in learning large language models (LLMs), particularly for low-resource languages like Cantonese. Despite having more than 85 million native speakers, Cantonese is still considered a low-resource language in the field of natural language processing (NLP) due to factors such as the dominance of Mandarin, lack of cohesion within the Cantonese-speaking community, diversity in character encoding and input methods, and the tendency of overseas Cantonese speakers to prefer using English. In addition, rich colloquial vocabulary of Cantonese, English loanwords, and code-switching characteristics add to the complexity of corpus collection and processing. To address these challenges, we collect Cantonese texts from a variety of sources, including open source corpora, Hong Kong-specific forums, Wikipedia, and Common Crawl data. We conduct rigorous data processing through language filtering, quality filtering, content filtering, and de-duplication steps, successfully constructing a high-quality Cantonese corpus of over 2 billion tokens for training large language models. We further refined the model through supervised fine-tuning (SFT) on curated Cantonese tasks, enhancing its ability to handle specific applications. Upon completion of the training, the model achieves state-of-the-art (SOTA) performance on four Cantonese benchmarks. After training on our dataset, the model also exhibits improved performance on other mainstream language tasks.
MoS: Unleashing Parameter Efficiency of Low-Rank Adaptation with Mixture of Shards
Oct 01, 2024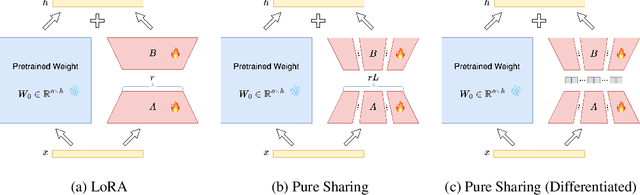

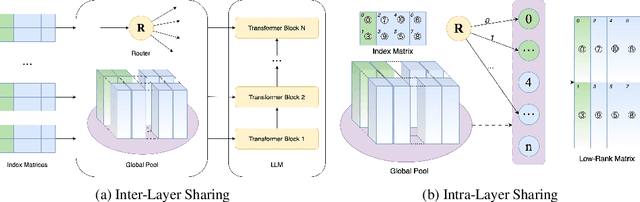
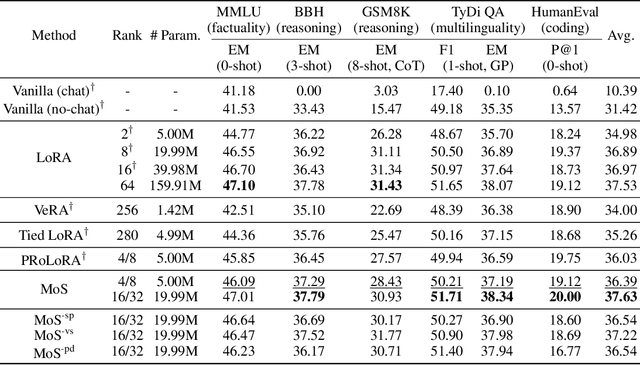
The rapid scaling of large language models necessitates more lightweight finetuning methods to reduce the explosive GPU memory overhead when numerous customized models are served simultaneously. Targeting more parameter-efficient low-rank adaptation (LoRA), parameter sharing presents a promising solution. Empirically, our research into high-level sharing principles highlights the indispensable role of differentiation in reversing the detrimental effects of pure sharing. Guided by this finding, we propose Mixture of Shards (MoS), incorporating both inter-layer and intra-layer sharing schemes, and integrating four nearly cost-free differentiation strategies, namely subset selection, pair dissociation, vector sharding, and shard privatization. Briefly, it selects a designated number of shards from global pools with a Mixture-of-Experts (MoE)-like routing mechanism before sequentially concatenating them to low-rank matrices. Hence, it retains all the advantages of LoRA while offering enhanced parameter efficiency, and effectively circumvents the drawbacks of peer parameter-sharing methods. Our empirical experiments demonstrate approximately 8x parameter savings in a standard LoRA setting. The ablation study confirms the significance of each component. Our insights into parameter sharing and MoS method may illuminate future developments of more parameter-efficient finetuning methods.
How Far Can Cantonese NLP Go? Benchmarking Cantonese Capabilities of Large Language Models
Aug 29, 2024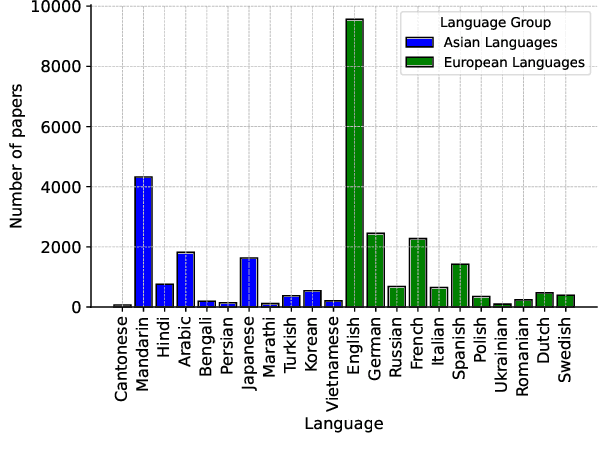
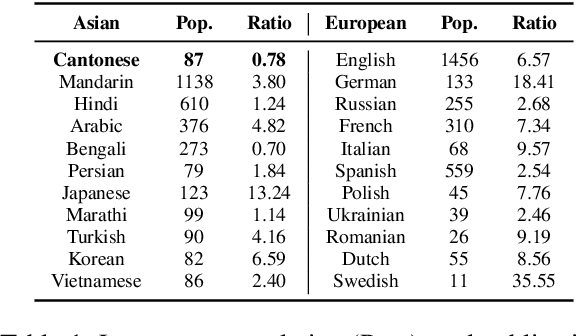
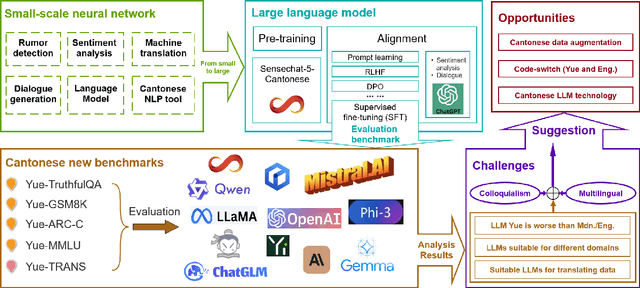
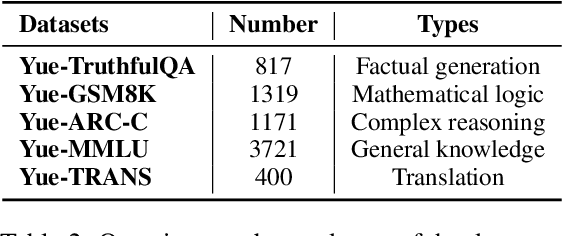
The rapid evolution of large language models (LLMs) has transformed the competitive landscape in natural language processing (NLP), particularly for English and other data-rich languages. However, underrepresented languages like Cantonese, spoken by over 85 million people, face significant development gaps, which is particularly concerning given the economic significance of the Guangdong-Hong Kong-Macau Greater Bay Area, and in substantial Cantonese-speaking populations in places like Singapore and North America. Despite its wide use, Cantonese has scant representation in NLP research, especially compared to other languages from similarly developed regions. To bridge these gaps, we outline current Cantonese NLP methods and introduce new benchmarks designed to evaluate LLM performance in factual generation, mathematical logic, complex reasoning, and general knowledge in Cantonese, which aim to advance open-source Cantonese LLM technology. We also propose future research directions and recommended models to enhance Cantonese LLM development.
Data Augmentation of Multi-turn Psychological Dialogue via Knowledge-driven Progressive Thought Prompting
Jun 24, 2024Existing dialogue data augmentation (DA) techniques predominantly focus on augmenting utterance-level dialogues, which makes it difficult to take dialogue contextual information into account. The advent of large language models (LLMs) has simplified the implementation of multi-turn dialogues. Due to absence of professional understanding and knowledge, it remains challenging to deliver satisfactory performance in low-resource domain, like psychological dialogue dialogue. DA involves creating new training or prompting data based on the existing data, which help the model better understand and generate psychology-related responses. In this paper, we aim to address the issue of multi-turn dialogue data augmentation for boosted performance in the psychology domain. We propose a knowledge-driven progressive thought prompting method to guide LLM to generate multi-turn psychology-related dialogue. This method integrates a progressive thought generator, a psychology knowledge generator, and a multi-turn dialogue generator. The thought generated by the progressive thought generator serves as a prompt to prevent the generated dialogue from having significant semantic deviations, while the psychology knowledge generator produces psychological knowledge to serve as the dialogue history for the LLM, guiding the dialogue generator to create multi-turn psychological dialogue. To ensure the precision of multi-turn psychological dialogue generation by LLM, a meticulous professional evaluation is required. Extensive experiments conducted on three datasets related to psychological dialogue verify the effectiveness of the proposed method.