 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
DS-ProGen: A Dual-Structure Deep Language Model for Functional Protein Design
May 18, 2025Inverse Protein Folding (IPF) is a critical subtask in the field of protein design, aiming to engineer amino acid sequences capable of folding correctly into a specified three-dimensional (3D) conformation. Although substantial progress has been achieved in recent years, existing methods generally rely on either backbone coordinates or molecular surface features alone, which restricts their ability to fully capture the complex chemical and geometric constraints necessary for precise sequence prediction. To address this limitation, we present DS-ProGen, a dual-structure deep language model for functional protein design, which integrates both backbone geometry and surface-level representations. By incorporating backbone coordinates as well as surface chemical and geometric descriptors into a next-amino-acid prediction paradigm, DS-ProGen is able to generate functionally relevant and structurally stable sequences while satisfying both global and local conformational constraints. On the PRIDE dataset, DS-ProGen attains the current state-of-the-art recovery rate of 61.47%, demonstrating the synergistic advantage of multi-modal structural encoding in protein design. Furthermore, DS-ProGen excels in predicting interactions with a variety of biological partners, including ligands, ions, and RNA, confirming its robust functional retention capabilities.
Developing and Utilizing a Large-Scale Cantonese Dataset for Multi-Tasking in Large Language Models
Mar 05, 2025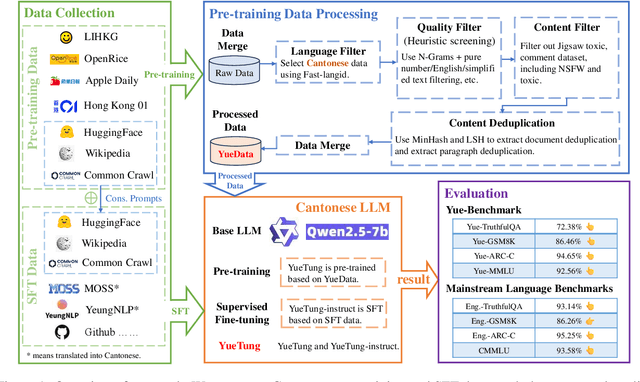
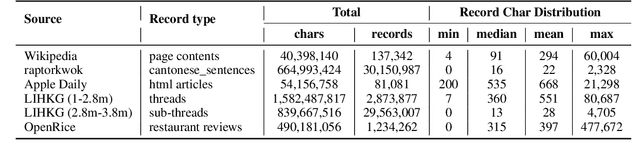
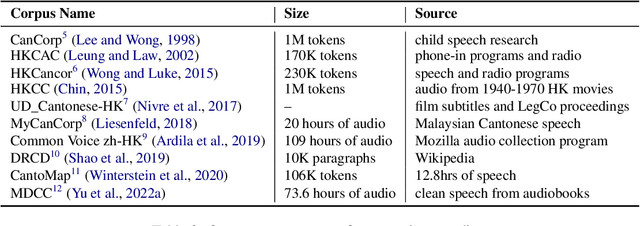
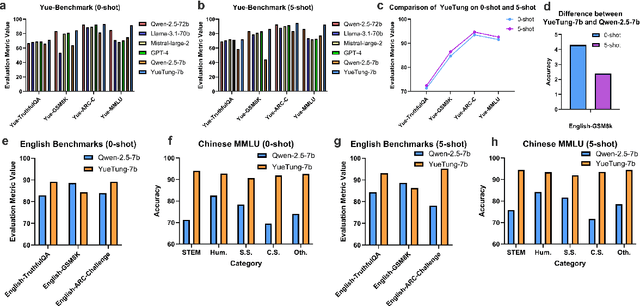
High-quality data resources play a crucial role in learning large language models (LLMs), particularly for low-resource languages like Cantonese. Despite having more than 85 million native speakers, Cantonese is still considered a low-resource language in the field of natural language processing (NLP) due to factors such as the dominance of Mandarin, lack of cohesion within the Cantonese-speaking community, diversity in character encoding and input methods, and the tendency of overseas Cantonese speakers to prefer using English. In addition, rich colloquial vocabulary of Cantonese, English loanwords, and code-switching characteristics add to the complexity of corpus collection and processing. To address these challenges, we collect Cantonese texts from a variety of sources, including open source corpora, Hong Kong-specific forums, Wikipedia, and Common Crawl data. We conduct rigorous data processing through language filtering, quality filtering, content filtering, and de-duplication steps, successfully constructing a high-quality Cantonese corpus of over 2 billion tokens for training large language models. We further refined the model through supervised fine-tuning (SFT) on curated Cantonese tasks, enhancing its ability to handle specific applications. Upon completion of the training, the model achieves state-of-the-art (SOTA) performance on four Cantonese benchmarks. After training on our dataset, the model also exhibits improved performance on other mainstream language tasks.
Advancing Oyster Phenotype Segmentation with Multi-Network Ensemble and Multi-Scale mechanism
Jan 20, 2025Phenotype segmentation is pivotal in analysing visual features of living organisms, enhancing our understanding of their characteristics. In the context of oysters, meat quality assessment is paramount, focusing on shell, meat, gonad, and muscle components. Traditional manual inspection methods are time-consuming and subjective, prompting the adoption of machine vision technology for efficient and objective evaluation. We explore machine vision's capacity for segmenting oyster components, leading to the development of a multi-network ensemble approach with a global-local hierarchical attention mechanism. This approach integrates predictions from diverse models and addresses challenges posed by varying scales, ensuring robust instance segmentation across components. Finally, we provide a comprehensive evaluation of the proposed method's performance using different real-world datasets, highlighting its efficacy and robustness in enhancing oyster phenotype segmentation.
GUIDE: A Global Unified Inference Engine for Deploying Large Language Models in Heterogeneous Environments
Dec 06, 2024



Efficiently deploying large language models (LLMs) in real-world scenarios remains a critical challenge, primarily due to hardware heterogeneity, inference framework limitations, and workload complexities.Efficiently deploying large language models (LLMs) in real-world scenarios remains a critical challenge, primarily due to hardware heterogeneity, inference framework limitations, and workload complexities. These challenges often lead to inefficiencies in memory utilization, latency, and throughput, hindering the effective deployment of LLMs, especially for non-experts. Through extensive experiments, we identify key performance bottlenecks, including sudden drops in memory utilization, latency fluctuations with varying batch sizes, and inefficiencies in multi-GPU configurations. These insights reveal a vast optimization space shaped by the intricate interplay of hardware, frameworks, and workload parameters. This underscores the need for a systematic approach to optimize LLM inference, motivating the design of our framework, GUIDE. GUIDE leverages dynamic modeling and simulation-based optimization to address these issues, achieving prediction errors between 25% and 55% for key metrics such as batch latency, TTFT, and decode throughput. By effectively bridging the gap between theoretical performance and practical deployment, our framework empowers practitioners, particularly non-specialists, to make data-driven decisions and unlock the full potential of LLMs in heterogeneous environments cheaply.
Training and Serving System of Foundation Models: A Comprehensive Survey
Jan 05, 2024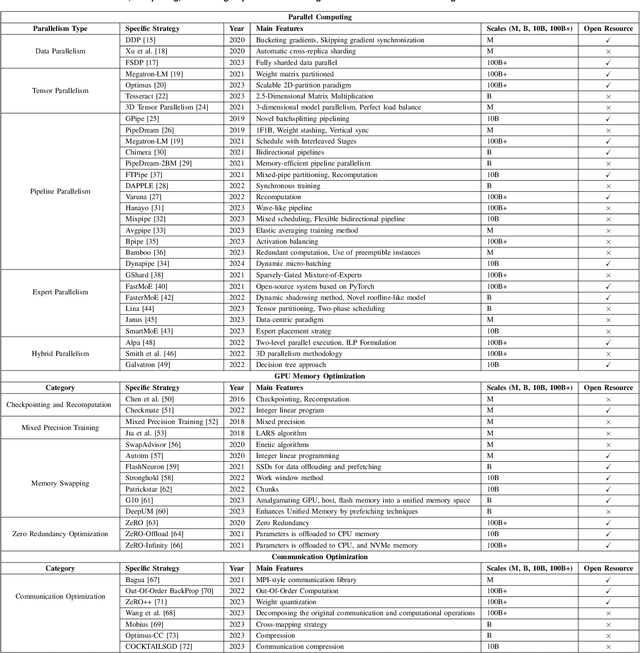
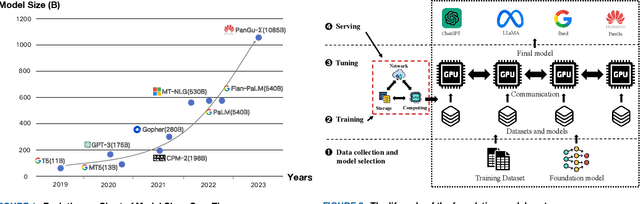
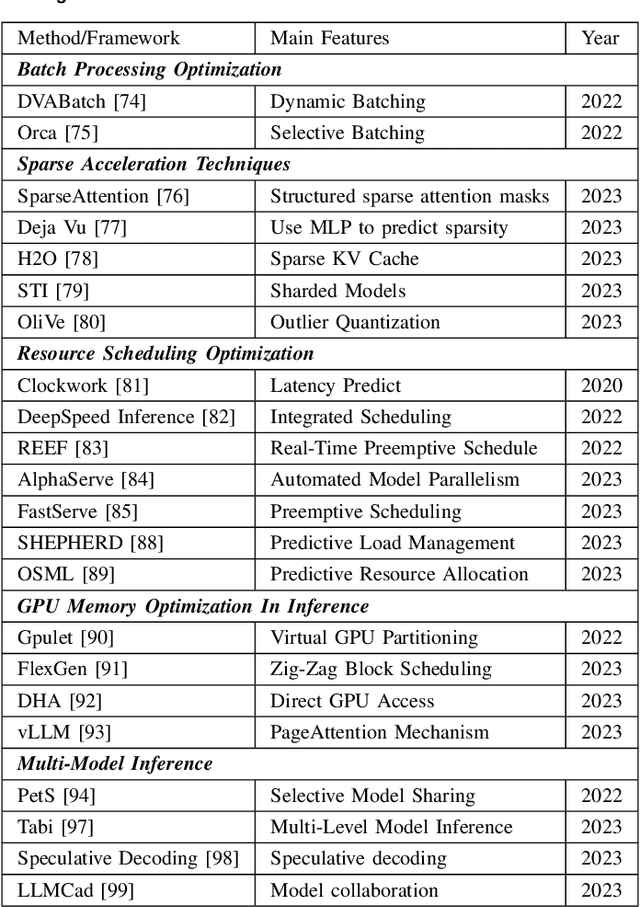
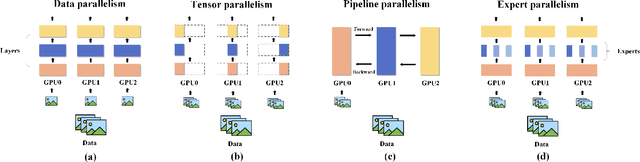
Foundation models (e.g., ChatGPT, DALL-E, PengCheng Mind, PanGu-$\Sigma$) have demonstrated extraordinary performance in key technological areas, such as natural language processing and visual recognition, and have become the mainstream trend of artificial general intelligence. This has led more and more major technology giants to dedicate significant human and financial resources to actively develop their foundation model systems, which drives continuous growth of these models' parameters. As a result, the training and serving of these models have posed significant challenges, including substantial computing power, memory consumption, bandwidth demands, etc. Therefore, employing efficient training and serving strategies becomes particularly crucial. Many researchers have actively explored and proposed effective methods. So, a comprehensive survey of them is essential for system developers and researchers. This paper extensively explores the methods employed in training and serving foundation models from various perspectives. It provides a detailed categorization of these state-of-the-art methods, including finer aspects such as network, computing, and storage. Additionally, the paper summarizes the challenges and presents a perspective on the future development direction of foundation model systems. Through comprehensive discussion and analysis, it hopes to provide a solid theoretical basis and practical guidance for future research and applications, promoting continuous innovation and development in foundation model systems.
SPOT! Revisiting Video-Language Models for Event Understanding
Dec 01, 2023
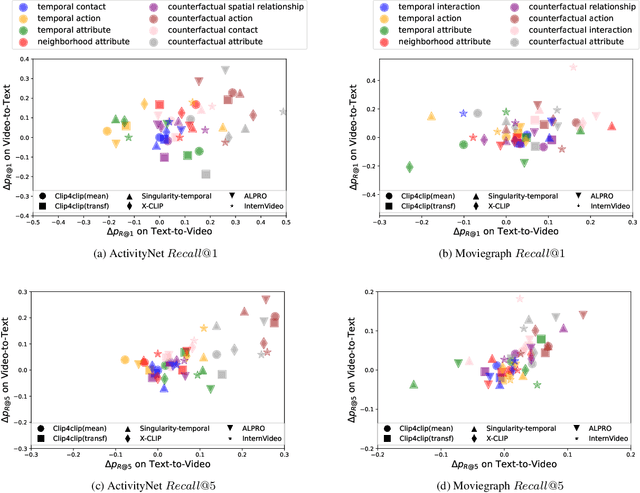


Understanding videos is an important research topic for multimodal learning. Leveraging large-scale datasets of web-crawled video-text pairs as weak supervision has become a pre-training paradigm for learning joint representations and showcased remarkable potential in video understanding tasks. However, videos can be multi-event and multi-grained, while these video-text pairs usually contain only broad-level video captions. This raises a question: with such weak supervision, can video representation in video-language models gain the ability to distinguish even factual discrepancies in textual description and understand fine-grained events? To address this, we introduce SPOT Prober, to benchmark existing video-language models's capacities of distinguishing event-level discrepancies as an indicator of models' event understanding ability. Our approach involves extracting events as tuples (<Subject, Predicate, Object, Attribute, Timestamps>) from videos and generating false event tuples by manipulating tuple components systematically. We reevaluate the existing video-language models with these positive and negative captions and find they fail to distinguish most of the manipulated events. Based on our findings, we propose to plug in these manipulated event captions as hard negative samples and find them effective in enhancing models for event understanding.
CDR-Adapter: Learning Adapters to Dig Out More Transferring Ability for Cross-Domain Recommendation Models
Nov 04, 2023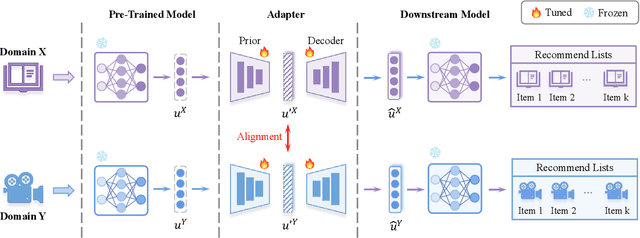

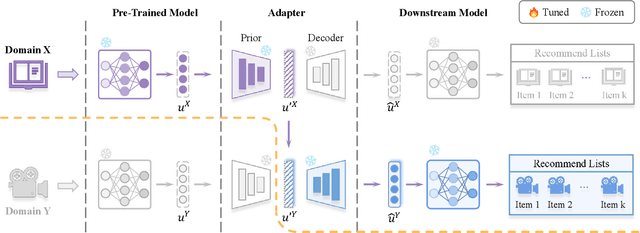
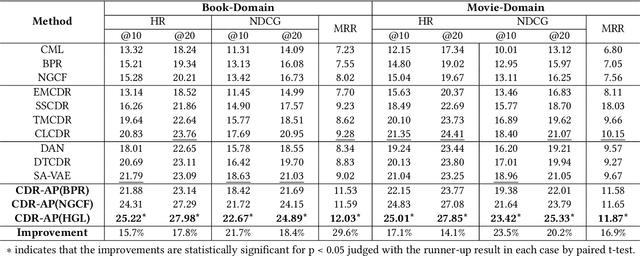
Data sparsity and cold-start problems are persistent challenges in recommendation systems. Cross-domain recommendation (CDR) is a promising solution that utilizes knowledge from the source domain to improve the recommendation performance in the target domain. Previous CDR approaches have mainly followed the Embedding and Mapping (EMCDR) framework, which involves learning a mapping function to facilitate knowledge transfer. However, these approaches necessitate re-engineering and re-training the network structure to incorporate transferrable knowledge, which can be computationally expensive and may result in catastrophic forgetting of the original knowledge. In this paper, we present a scalable and efficient paradigm to address data sparsity and cold-start issues in CDR, named CDR-Adapter, by decoupling the original recommendation model from the mapping function, without requiring re-engineering the network structure. Specifically, CDR-Adapter is a novel plug-and-play module that employs adapter modules to align feature representations, allowing for flexible knowledge transfer across different domains and efficient fine-tuning with minimal training costs. We conducted extensive experiments on the benchmark dataset, which demonstrated the effectiveness of our approach over several state-of-the-art CDR approaches.
Hybrid CNN -Interpreter: Interpret local and global contexts for CNN-based Models
Oct 31, 2022



Convolutional neural network (CNN) models have seen advanced improvements in performance in various domains, but lack of interpretability is a major barrier to assurance and regulation during operation for acceptance and deployment of AI-assisted applications. There have been many works on input interpretability focusing on analyzing the input-output relations, but the internal logic of models has not been clarified in the current mainstream interpretability methods. In this study, we propose a novel hybrid CNN-interpreter through: (1) An original forward propagation mechanism to examine the layer-specific prediction results for local interpretability. (2) A new global interpretability that indicates the feature correlation and filter importance effects. By combining the local and global interpretabilities, hybrid CNN-interpreter enables us to have a solid understanding and monitoring of model context during the whole learning process with detailed and consistent representations. Finally, the proposed interpretabilities have been demonstrated to adapt to various CNN-based model structures.
Predicting Blossom Date of Cherry Tree With Support Vector Machine and Recurrent Neural Network
Oct 10, 2022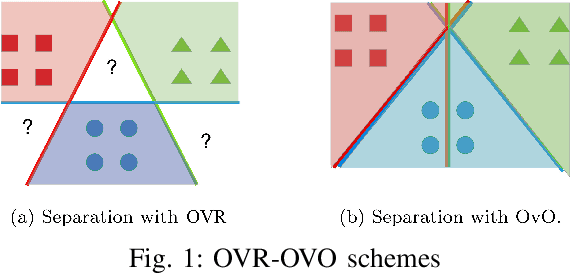
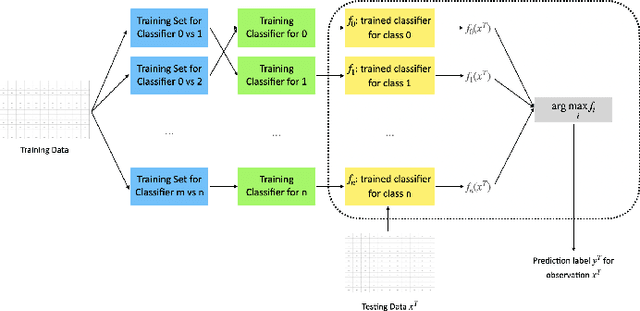
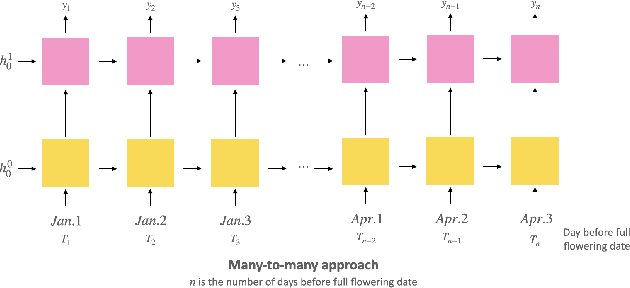
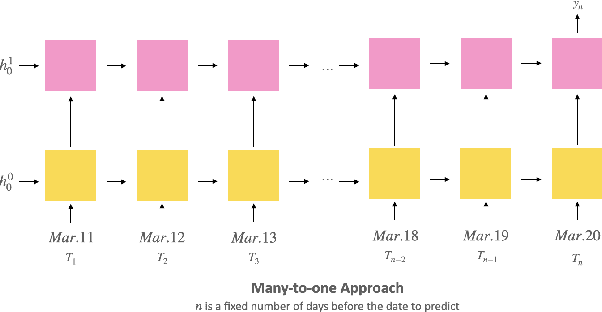
Our project probes the relationship between temperatures and the blossom date of cherry trees. Through modeling, future flowering will become predictive, helping the public plan travels and avoid pollen season. To predict the date when the cherry trees will blossom exactly could be viewed as a multiclass classification problem, so we applied the multi-class Support Vector Classifier (SVC) and Recurrent Neural Network (RNN), particularly Long Short-term Memory (LSTM), to formulate the problem. In the end, we evaluate and compare the performance of these approaches to find out which one might be more applicable in reality.