 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdeological Isolation in Online Social Networks: A Survey of Computational Definitions, Metrics, and Mitigation Strategies
Jan 12, 2026The proliferation of online social networks has significantly reshaped the way individuals access and engage with information. While these platforms offer unprecedented connectivity, they may foster environments where users are increasingly exposed to homogeneous content and like-minded interactions. Such dynamics are associated with selective exposure and the emergence of filter bubbles, echo chambers, tunnel vision, and polarization, which together can contribute to ideological isolation and raise concerns about information diversity and public discourse. This survey provides a comprehensive computational review of existing studies that define, analyze, quantify, and mitigate ideological isolation in online social networks. We examine the mechanisms underlying content personalization, user behavior patterns, and network structures that reinforce content-exposure concentration and narrowing dynamics. This paper also systematically reviews methodological approaches for detecting and measuring these isolation-related phenomena, covering network-, content-, and behavior-based metrics. We further organize computational mitigation strategies, including network-topological interventions and recommendation-level controls, and discuss their trade-offs and deployment considerations. By integrating definitions, metrics, and interventions across structural/topological, content-based, interactional, and cognitive isolation, this survey provides a unified computational framework. It serves as a reference for understanding and addressing the key challenges and opportunities in promoting information diversity and reducing ideological fragmentation in the digital age.
Towards Superior Quantization Accuracy: A Layer-sensitive Approach
Mar 09, 2025Large Vision and Language Models have exhibited remarkable human-like intelligence in tasks such as natural language comprehension, problem-solving, logical reasoning, and knowledge retrieval. However, training and serving these models require substantial computational resources, posing a significant barrier to their widespread application and further research. To mitigate this challenge, various model compression techniques have been developed to reduce computational requirements. Nevertheless, existing methods often employ uniform quantization configurations, failing to account for the varying difficulties across different layers in quantizing large neural network models. This paper tackles this issue by leveraging layer-sensitivity features, such as activation sensitivity and weight distribution Kurtosis, to identify layers that are challenging to quantize accurately and allocate additional memory budget. The proposed methods, named SensiBoost and KurtBoost, respectively, demonstrate notable improvement in quantization accuracy, achieving up to 9% lower perplexity with only a 2% increase in memory budget on LLama models compared to the baseline.
PerceiverS: A Multi-Scale Perceiver with Effective Segmentation for Long-Term Expressive Symbolic Music Generation
Nov 13, 2024Music generation has progressed significantly, especially in the domain of audio generation. However, generating symbolic music that is both long-structured and expressive remains a significant challenge. In this paper, we propose PerceiverS (Segmentation and Scale), a novel architecture designed to address this issue by leveraging both Effective Segmentation and Multi-Scale attention mechanisms. Our approach enhances symbolic music generation by simultaneously learning long-term structural dependencies and short-term expressive details. By combining cross-attention and self-attention in a Multi-Scale setting, PerceiverS captures long-range musical structure while preserving performance nuances. The proposed model, evaluated on datasets like Maestro, demonstrates improvements in generating coherent and diverse music with both structural consistency and expressive variation. The project demos and the generated music samples can be accessed through the link: https://perceivers.github.io.
Balancing Information Perception with Yin-Yang: Agent-Based Information Neutrality Model for Recommendation Systems
Apr 07, 2024While preference-based recommendation algorithms effectively enhance user engagement by recommending personalized content, they often result in the creation of ``filter bubbles''. These bubbles restrict the range of information users interact with, inadvertently reinforcing their existing viewpoints. Previous research has focused on modifying these underlying algorithms to tackle this issue. Yet, approaches that maintain the integrity of the original algorithms remain largely unexplored. This paper introduces an Agent-based Information Neutrality model grounded in the Yin-Yang theory, namely, AbIN. This innovative approach targets the imbalance in information perception within existing recommendation systems. It is designed to integrate with these preference-based systems, ensuring the delivery of recommendations with neutral information. Our empirical evaluation of this model proved its efficacy, showcasing its capacity to expand information diversity while respecting user preferences. Consequently, AbIN emerges as an instrumental tool in mitigating the negative impact of filter bubbles on information consumption.
Detecting misinformation through Framing Theory: the Frame Element-based Model
Feb 19, 2024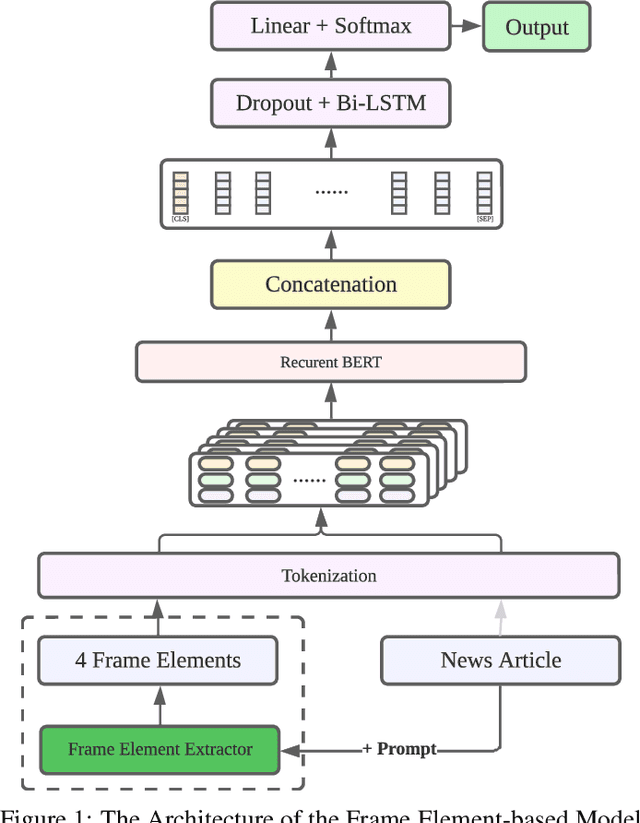
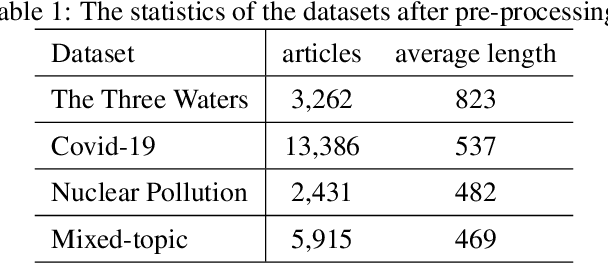
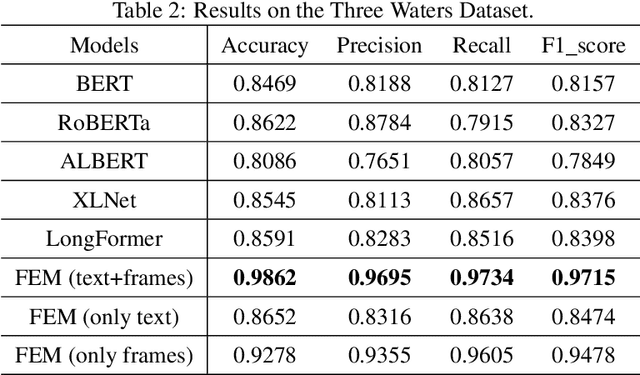
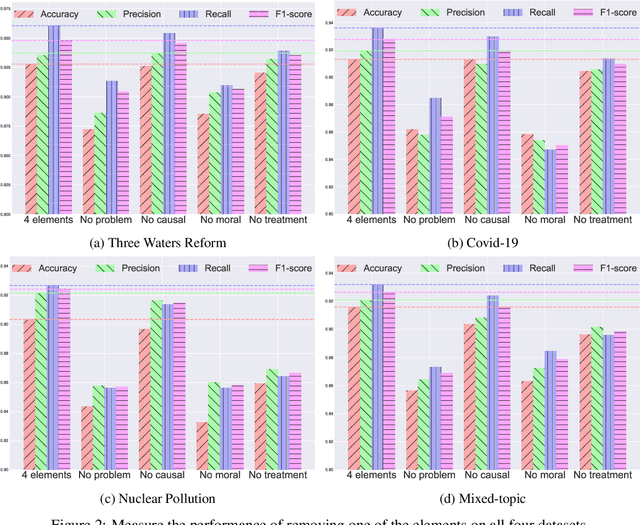
In this paper, we delve into the rapidly evolving challenge of misinformation detection, with a specific focus on the nuanced manipulation of narrative frames - an under-explored area within the AI community. The potential for Generative AI models to generate misleading narratives underscores the urgency of this problem. Drawing from communication and framing theories, we posit that the presentation or 'framing' of accurate information can dramatically alter its interpretation, potentially leading to misinformation. We highlight this issue through real-world examples, demonstrating how shifts in narrative frames can transmute fact-based information into misinformation. To tackle this challenge, we propose an innovative approach leveraging the power of pre-trained Large Language Models and deep neural networks to detect misinformation originating from accurate facts portrayed under different frames. These advanced AI techniques offer unprecedented capabilities in identifying complex patterns within unstructured data critical for examining the subtleties of narrative frames. The objective of this paper is to bridge a significant research gap in the AI domain, providing valuable insights and methodologies for tackling framing-induced misinformation, thus contributing to the advancement of responsible and trustworthy AI technologies. Several experiments are intensively conducted and experimental results explicitly demonstrate the various impact of elements of framing theory proving the rationale of applying framing theory to increase the performance in misinformation detection.
BHEISR: Nudging from Bias to Balance -- Promoting Belief Harmony by Eliminating Ideological Segregation in Knowledge-based Recommendations
Jul 06, 2023



In the realm of personalized recommendation systems, the increasing concern is the amplification of belief imbalance and user biases, a phenomenon primarily attributed to the filter bubble. Addressing this critical issue, we introduce an innovative intermediate agency (BHEISR) between users and existing recommendation systems to attenuate the negative repercussions of the filter bubble effect in extant recommendation systems. The main objective is to strike a belief balance for users while minimizing the detrimental influence caused by filter bubbles. The BHEISR model amalgamates principles from nudge theory while upholding democratic and transparent principles. It harnesses user-specific category information to stimulate curiosity, even in areas users might initially deem uninteresting. By progressively stimulating interest in novel categories, the model encourages users to broaden their belief horizons and explore the information they typically overlook. Our model is time-sensitive and operates on a user feedback loop. It utilizes the existing recommendation algorithm of the model and incorporates user feedback from the prior time frame. This approach endeavors to transcend the constraints of the filter bubble, enrich recommendation diversity, and strike a belief balance among users while also catering to user preferences and system-specific business requirements. To validate the effectiveness and reliability of the BHEISR model, we conducted a series of comprehensive experiments with real-world datasets. These experiments compared the performance of the BHEISR model against several baseline models using nearly 200 filter bubble-impacted users as test subjects. Our experimental results conclusively illustrate the superior performance of the BHEISR model in mitigating filter bubbles and balancing user perspectives.
AaKOS: Aspect-adaptive Knowledge-based Opinion Summarization
May 26, 2023The rapid growth of information on the Internet has led to an overwhelming amount of opinions and comments on various activities, products, and services. This makes it difficult and time-consuming for users to process all the available information when making decisions. Text summarization, a Natural Language Processing (NLP) task, has been widely explored to help users quickly retrieve relevant information by generating short and salient content from long or multiple documents. Recent advances in pre-trained language models, such as ChatGPT, have demonstrated the potential of Large Language Models (LLMs) in text generation. However, LLMs require massive amounts of data and resources and are challenging to implement as offline applications. Furthermore, existing text summarization approaches often lack the ``adaptive" nature required to capture diverse aspects in opinion summarization, which is particularly detrimental to users with specific requirements or preferences. In this paper, we propose an Aspect-adaptive Knowledge-based Opinion Summarization model for product reviews, which effectively captures the adaptive nature required for opinion summarization. The model generates aspect-oriented summaries given a set of reviews for a particular product, efficiently providing users with useful information on specific aspects they are interested in, ensuring the generated summaries are more personalized and informative. Extensive experiments have been conducted using real-world datasets to evaluate the proposed model. The results demonstrate that our model outperforms state-of-the-art approaches and is adaptive and efficient in generating summaries that focus on particular aspects, enabling users to make well-informed decisions and catering to their diverse interests and preferences.
Soft Prompt Guided Joint Learning for Cross-Domain Sentiment Analysis
Mar 01, 2023
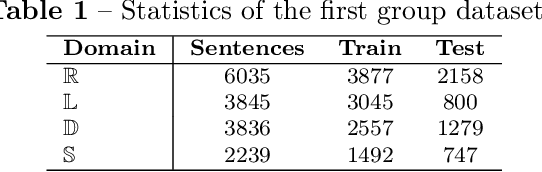


Aspect term extraction is a fundamental task in fine-grained sentiment analysis, which aims at detecting customer's opinion targets from reviews on product or service. The traditional supervised models can achieve promising results with annotated datasets, however, the performance dramatically decreases when they are applied to the task of cross-domain aspect term extraction. Existing cross-domain transfer learning methods either directly inject linguistic features into Language models, making it difficult to transfer linguistic knowledge to target domain, or rely on the fixed predefined prompts, which is time-consuming to construct the prompts over all potential aspect term spans. To resolve the limitations, we propose a soft prompt-based joint learning method for cross domain aspect term extraction in this paper. Specifically, by incorporating external linguistic features, the proposed method learn domain-invariant representations between source and target domains via multiple objectives, which bridges the gap between domains with varied distributions of aspect terms. Further, the proposed method interpolates a set of transferable soft prompts consisted of multiple learnable vectors that are beneficial to detect aspect terms in target domain. Extensive experiments are conducted on the benchmark datasets and the experimental results demonstrate the effectiveness of the proposed method for cross-domain aspect terms extraction.
DOR: A Novel Dual-Observation-Based Approach for News Recommendation Systems
Feb 02, 2023
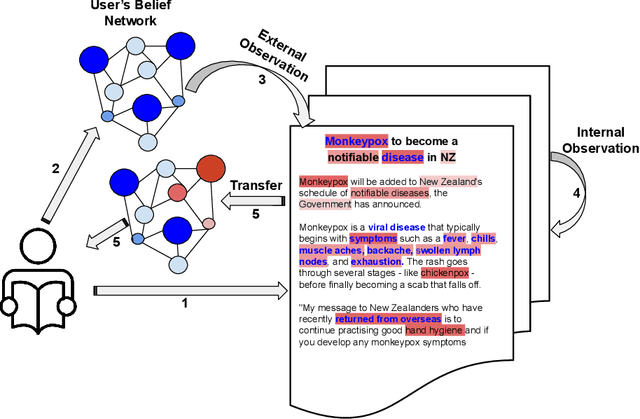
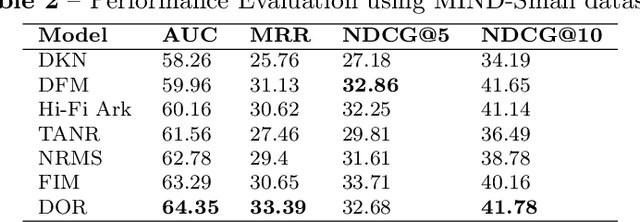
Online social media platforms offer access to a vast amount of information, but sifting through the abundance of news can be overwhelming and tiring for readers. personalised recommendation algorithms can help users find information that interests them. However, most existing models rely solely on observations of user behaviour, such as viewing history, ignoring the connections between the news and a user's prior knowledge. This can result in a lack of diverse recommendations for individuals. In this paper, we propose a novel method to address the complex problem of news recommendation. Our approach is based on the idea of dual observation, which involves using a deep neural network with observation mechanisms to identify the main focus of a news article as well as the focus of the user on the article. This is achieved by taking into account the user's belief network, which reflects their personal interests and biases. By considering both the content of the news and the user's perspective, our approach is able to provide more personalised and accurate recommendations. We evaluate the performance of our model on real-world datasets and show that our proposed method outperforms several popular baselines.
A Light-weight, Effective and Efficient Model for Label Aggregation in Crowdsourcing
Nov 19, 2022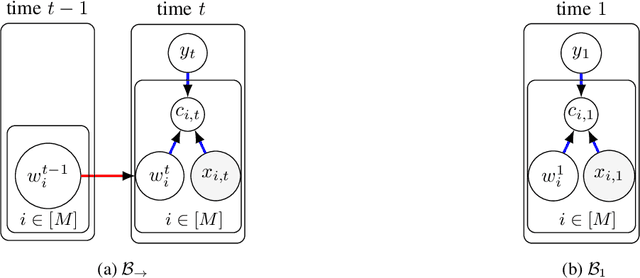
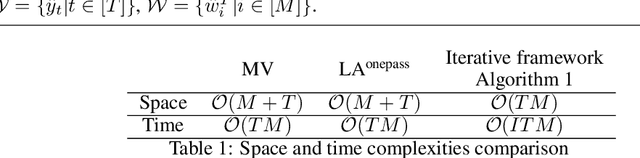
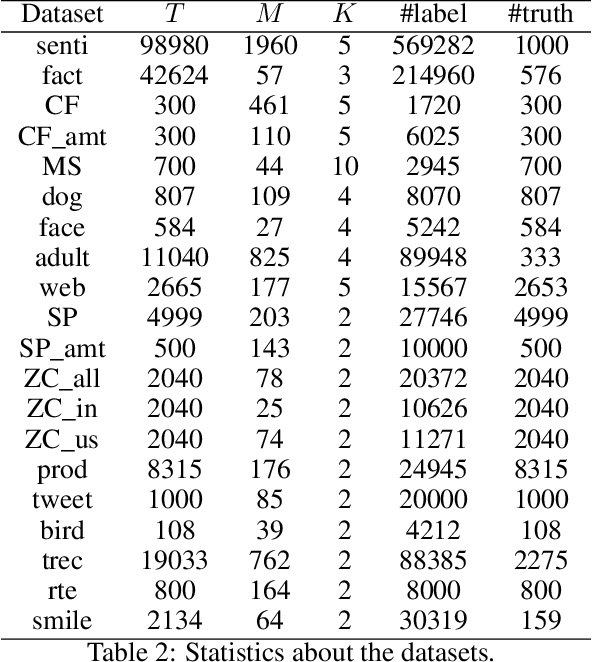
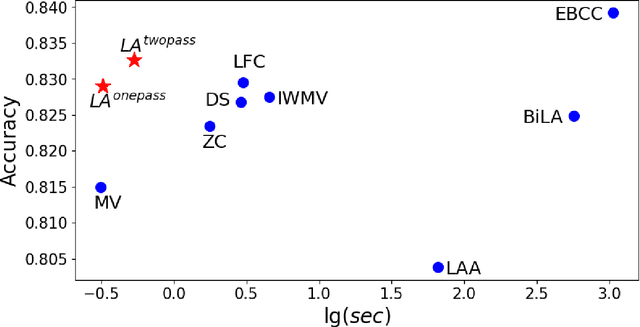
Due to the noises in crowdsourced labels, label aggregation (LA) has emerged as a standard procedure to post-process crowdsourced labels. LA methods estimate true labels from crowdsourced labels by modeling worker qualities. Most existing LA methods are iterative in nature. They need to traverse all the crowdsourced labels multiple times in order to jointly and iteratively update true labels and worker qualities until convergence. Consequently, these methods have high space and time complexities. In this paper, we treat LA as a dynamic system and model it as a Dynamic Bayesian network. From the dynamic model we derive two light-weight algorithms, LA\textsuperscript{onepass} and LA\textsuperscript{twopass}, which can effectively and efficiently estimate worker qualities and true labels by traversing all the labels at most twice. Due to the dynamic nature, the proposed algorithms can also estimate true labels online without re-visiting historical data. We theoretically prove the convergence property of the proposed algorithms, and bound the error of estimated worker qualities. We also analyze the space and time complexities of the proposed algorithms and show that they are equivalent to those of majority voting. Experiments conducted on 20 real-world datasets demonstrate that the proposed algorithms can effectively and efficiently aggregate labels in both offline and online settings even if they traverse all the labels at most twice.