 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining a Student Expert via Semi-Supervised Foundation Model Distillation
Apr 04, 2026Foundation models deliver strong perception but are often too computationally heavy to deploy, and adapting them typically requires costly annotations. We introduce a semi-supervised knowledge distillation (SSKD) framework that compresses pre-trained vision foundation models (VFMs) into compact experts using limited labeled and abundant unlabeled data, and instantiate it for instance segmentation where per-pixel labels are particularly expensive. The framework unfolds in three stages: (1) domain adaptation of the VFM(s) via self-training with contrastive calibration, (2) knowledge transfer through a unified multi-objective loss, and (3) student refinement to mitigate residual pseudo-label bias. Central to our approach is an instance-aware pixel-wise contrastive loss that fuses mask and class scores to extract informative negatives and enforce clear inter-instance margins. By maintaining this contrastive signal across both adaptation and distillation, we align teacher and student embeddings and more effectively leverage unlabeled images. On Cityscapes and ADE20K, our $\approx 11\times$ smaller student improves over its zero-shot VFM teacher(s) by +11.9 and +8.6 AP, surpasses adapted teacher(s) by +3.4 and +1.5 AP, and outperforms state-of-the-art SSKD methods on benchmarks.
PISCO: Precise Video Instance Insertion with Sparse Control
Feb 09, 2026The landscape of AI video generation is undergoing a pivotal shift: moving beyond general generation - which relies on exhaustive prompt-engineering and "cherry-picking" - towards fine-grained, controllable generation and high-fidelity post-processing. In professional AI-assisted filmmaking, it is crucial to perform precise, targeted modifications. A cornerstone of this transition is video instance insertion, which requires inserting a specific instance into existing footage while maintaining scene integrity. Unlike traditional video editing, this task demands several requirements: precise spatial-temporal placement, physically consistent scene interaction, and the faithful preservation of original dynamics - all achieved under minimal user effort. In this paper, we propose PISCO, a video diffusion model for precise video instance insertion with arbitrary sparse keyframe control. PISCO allows users to specify a single keyframe, start-and-end keyframes, or sparse keyframes at arbitrary timestamps, and automatically propagates object appearance, motion, and interaction. To address the severe distribution shift induced by sparse conditioning in pretrained video diffusion models, we introduce Variable-Information Guidance for robust conditioning and Distribution-Preserving Temporal Masking to stabilize temporal generation, together with geometry-aware conditioning for realistic scene adaptation. We further construct PISCO-Bench, a benchmark with verified instance annotations and paired clean background videos, and evaluate performance using both reference-based and reference-free perceptual metrics. Experiments demonstrate that PISCO consistently outperforms strong inpainting and video editing baselines under sparse control, and exhibits clear, monotonic performance improvements as additional control signals are provided. Project page: xiangbogaobarry.github.io/PISCO.
SemanticNN: Compressive and Error-Resilient Semantic Offloading for Extremely Weak Devices
Nov 14, 2025With the rapid growth of the Internet of Things (IoT), integrating artificial intelligence (AI) on extremely weak embedded devices has garnered significant attention, enabling improved real-time performance and enhanced data privacy. However, the resource limitations of such devices and unreliable network conditions necessitate error-resilient device-edge collaboration systems. Traditional approaches focus on bit-level transmission correctness, which can be inefficient under dynamic channel conditions. In contrast, we propose SemanticNN, a semantic codec that tolerates bit-level errors in pursuit of semantic-level correctness, enabling compressive and resilient collaborative inference offloading under strict computational and communication constraints. It incorporates a Bit Error Rate (BER)-aware decoder that adapts to dynamic channel conditions and a Soft Quantization (SQ)-based encoder to learn compact representations. Building on this architecture, we introduce Feature-augmentation Learning, a novel training strategy that enhances offloading efficiency. To address encoder-decoder capability mismatches from asymmetric resources, we propose XAI-based Asymmetry Compensation to enhance decoding semantic fidelity. We conduct extensive experiments on STM32 using three models and six datasets across image classification and object detection tasks. Experimental results demonstrate that, under varying transmission error rates, SemanticNN significantly reduces feature transmission volume by 56.82-344.83x while maintaining superior inference accuracy.
SuperGen: An Efficient Ultra-high-resolution Video Generation System with Sketching and Tiling
Aug 25, 2025Diffusion models have recently achieved remarkable success in generative tasks (e.g., image and video generation), and the demand for high-quality content (e.g., 2K/4K videos) is rapidly increasing across various domains. However, generating ultra-high-resolution videos on existing standard-resolution (e.g., 720p) platforms remains challenging due to the excessive re-training requirements and prohibitively high computational and memory costs. To this end, we introduce SuperGen, an efficient tile-based framework for ultra-high-resolution video generation. SuperGen features a novel training-free algorithmic innovation with tiling to successfully support a wide range of resolutions without additional training efforts while significantly reducing both memory footprint and computational complexity. Moreover, SuperGen incorporates a tile-tailored, adaptive, region-aware caching strategy that accelerates video generation by exploiting redundancy across denoising steps and spatial regions. SuperGen also integrates cache-guided, communication-minimized tile parallelism for enhanced throughput and minimized latency. Evaluations demonstrate that SuperGen harvests the maximum performance gains while achieving high output quality across various benchmarks.
MMHU: A Massive-Scale Multimodal Benchmark for Human Behavior Understanding
Jul 16, 2025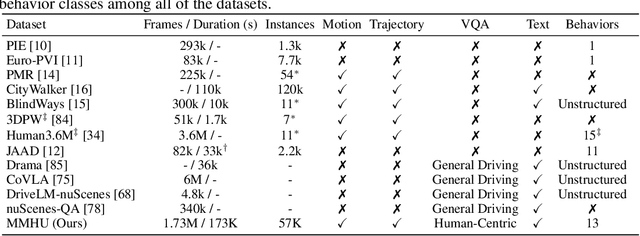



Humans are integral components of the transportation ecosystem, and understanding their behaviors is crucial to facilitating the development of safe driving systems. Although recent progress has explored various aspects of human behavior$\unicode{x2014}$such as motion, trajectories, and intention$\unicode{x2014}$a comprehensive benchmark for evaluating human behavior understanding in autonomous driving remains unavailable. In this work, we propose $\textbf{MMHU}$, a large-scale benchmark for human behavior analysis featuring rich annotations, such as human motion and trajectories, text description for human motions, human intention, and critical behavior labels relevant to driving safety. Our dataset encompasses 57k human motion clips and 1.73M frames gathered from diverse sources, including established driving datasets such as Waymo, in-the-wild videos from YouTube, and self-collected data. A human-in-the-loop annotation pipeline is developed to generate rich behavior captions. We provide a thorough dataset analysis and benchmark multiple tasks$\unicode{x2014}$ranging from motion prediction to motion generation and human behavior question answering$\unicode{x2014}$thereby offering a broad evaluation suite. Project page : https://MMHU-Benchmark.github.io.
4KAgent: Agentic Any Image to 4K Super-Resolution
Jul 09, 2025We present 4KAgent, a unified agentic super-resolution generalist system designed to universally upscale any image to 4K resolution (and even higher, if applied iteratively). Our system can transform images from extremely low resolutions with severe degradations, for example, highly distorted inputs at 256x256, into crystal-clear, photorealistic 4K outputs. 4KAgent comprises three core components: (1) Profiling, a module that customizes the 4KAgent pipeline based on bespoke use cases; (2) A Perception Agent, which leverages vision-language models alongside image quality assessment experts to analyze the input image and make a tailored restoration plan; and (3) A Restoration Agent, which executes the plan, following a recursive execution-reflection paradigm, guided by a quality-driven mixture-of-expert policy to select the optimal output for each step. Additionally, 4KAgent embeds a specialized face restoration pipeline, significantly enhancing facial details in portrait and selfie photos. We rigorously evaluate our 4KAgent across 11 distinct task categories encompassing a total of 26 diverse benchmarks, setting new state-of-the-art on a broad spectrum of imaging domains. Our evaluations cover natural images, portrait photos, AI-generated content, satellite imagery, fluorescence microscopy, and medical imaging like fundoscopy, ultrasound, and X-ray, demonstrating superior performance in terms of both perceptual (e.g., NIQE, MUSIQ) and fidelity (e.g., PSNR) metrics. By establishing a novel agentic paradigm for low-level vision tasks, we aim to catalyze broader interest and innovation within vision-centric autonomous agents across diverse research communities. We will release all the code, models, and results at: https://4kagent.github.io.
CAST: Contrastive Adaptation and Distillation for Semi-Supervised Instance Segmentation
May 29, 2025Instance segmentation demands costly per-pixel annotations and large models. We introduce CAST, a semi-supervised knowledge distillation (SSKD) framework that compresses pretrained vision foundation models (VFM) into compact experts using limited labeled and abundant unlabeled data. CAST unfolds in three stages: (1) domain adaptation of the VFM teacher(s) via self-training with contrastive pixel calibration, (2) distillation into a compact student via a unified multi-objective loss that couples standard supervision and pseudo-labels with our instance-aware pixel-wise contrastive term, and (3) fine-tuning on labeled data to remove residual pseudo-label bias. Central to CAST is an \emph{instance-aware pixel-wise contrastive loss} that fuses mask and class scores to mine informative negatives and enforce clear inter-instance margins. By maintaining this contrastive signal across both adaptation and distillation, we align teacher and student embeddings and fully leverage unlabeled images. On Cityscapes and ADE20K, our ~11X smaller student surpasses its adapted VFM teacher(s) by +3.4 AP (33.9 vs. 30.5) and +1.5 AP (16.7 vs. 15.2) and outperforms state-of-the-art semi-supervised approaches.
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
May 26, 2025The rapid advancement of Large Multimodal Models (LMMs) for 2D images and videos has motivated extending these models to understand 3D scenes, aiming for human-like visual-spatial intelligence. Nevertheless, achieving deep spatial understanding comparable to human capabilities poses significant challenges in model encoding and data acquisition. Existing methods frequently depend on external depth sensors for geometry capture or utilize off-the-shelf algorithms for pre-constructing 3D maps, thereby limiting their scalability, especially with prevalent monocular video inputs and for time-sensitive applications. In this work, we introduce VLM-3R, a unified framework for Vision-Language Models (VLMs) that incorporates 3D Reconstructive instruction tuning. VLM-3R processes monocular video frames by employing a geometry encoder to derive implicit 3D tokens that represent spatial understanding. Leveraging our Spatial-Visual-View Fusion and over 200K curated 3D reconstructive instruction tuning question-answer (QA) pairs, VLM-3R effectively aligns real-world spatial context with language instructions. This enables monocular 3D spatial assistance and embodied reasoning. To facilitate the evaluation of temporal reasoning, we introduce the Vision-Spatial-Temporal Intelligence benchmark, featuring over 138.6K QA pairs across five distinct tasks focused on evolving spatial relationships. Extensive experiments demonstrate that our model, VLM-3R, not only facilitates robust visual-spatial reasoning but also enables the understanding of temporal 3D context changes, excelling in both accuracy and scalability.
VISTA: Generative Visual Imagination for Vision-and-Language Navigation
May 17, 2025



Vision-and-Language Navigation (VLN) tasks agents with locating specific objects in unseen environments using natural language instructions and visual cues. Many existing VLN approaches typically follow an 'observe-and-reason' schema, that is, agents observe the environment and decide on the next action to take based on the visual observations of their surroundings. They often face challenges in long-horizon scenarios due to limitations in immediate observation and vision-language modality gaps. To overcome this, we present VISTA, a novel framework that employs an 'imagine-and-align' navigation strategy. Specifically, we leverage the generative prior of pre-trained diffusion models for dynamic visual imagination conditioned on both local observations and high-level language instructions. A Perceptual Alignment Filter module then grounds these goal imaginations against current observations, guiding an interpretable and structured reasoning process for action selection. Experiments show that VISTA sets new state-of-the-art results on Room-to-Room (R2R) and RoboTHOR benchmarks, e.g.,+3.6% increase in Success Rate on R2R. Extensive ablation analysis underscores the value of integrating forward-looking imagination, perceptual alignment, and structured reasoning for robust navigation in long-horizon environments.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.